Control dependency
Control Dependency in Pipelined Microarchitecture

1. Introduction: What is Control Dependency?
Control Dependency는 Jump, Branch 같은 명령어가 실행될 때 다음 실행될 PC(Program Counter) 값을 예측하기 어려운 문제를 의미합니다.
즉, 명령어의 흐름(Control Flow)이 변경될 가능성이 있을 때, 올바른 명령어를 예측하는 것이 어렵다는 것이 핵심 문제입니다.
1.1. Why is Control Dependency a Problem?
- 대부분의 명령어는 PC + 4로 다음 명령어를 예측할 수 있음.
- 하지만 Branch(분기)나 Jump(점프) 명령어는 특정 조건에 따라 다른 주소로 이동할 수 있음.
- 이 경우, 다음에 실행될 PC 값을 미리 알 수 없기 때문에 Pipeline에서 Stalling이 발생할 가능성이 높음.

2. Handling Control Dependency
Control Dependency를 해결하는 방법에는 여러 가지가 있습니다.
2.1. Stall the Pipeline (Stalling)
- 문제 해결 방식:
- Jump, Branch 명령어를 만날 때까지 Pipeline을 멈추고(스톨) 올바른 PC 값을 결정한 후 실행.
- 단점:
- Stalling은 CPU 성능을 크게 저하시킴.
- Branch를 만날 때마다 Pipeline이 멈추기 때문에 비효율적.
2.2. Guess the Next Fetch Address (Branch Prediction)
- 문제 해결 방식:
- CPU가 Branch가 Taken(분기 실행됨)인지 Not Taken(분기 실행 안됨)인지 미리 예측하고 명령어를 실행.
- 예측이 맞으면 Pipeline이 정상 실행됨.
- 예측이 틀리면 Pipeline을 Flush(비우고) 올바른 명령어를 다시 Fetch.
- Branch Prediction의 효과
- 일반적인 Forward (if-then-else) 분기에서는 약 50% 예측 성공률.
- Loop(반복문) 분기에서는 약 90% 예측 성공률.
2.3. Employ Delayed Branching (Branch Delay Slot)
- 문제 해결 방식:
- Branch 명령어 이후 한 개의 명령어를 무조건 실행하도록 설계.
- 즉, Branch 명령어가 실행되더라도 Branch Delay Slot 안의 명령어는 항상 실행되므로 Pipeline이 멈추지 않음.
예제
BEQ r1, r2, TARGET // Branch가 실행될 수도 있고 안 될 수도 있음
ADD r3, r4, r5 // 이 명령어는 무조건 실행 (Branch Delay Slot)- ADD r3, r4, r5는 실행될 것이 보장되므로, Pipeline Stalling을 피할 수 있음.
- 단점
- Branch 이후 실행할 의미 있는 명령어가 없는 경우, No-Op(NOP)를 삽입해야 함 → 낭비 발생.
2.4. Do Something Else (Fine-Grained Multithreading)
- 문제 해결 방식:
- 현재 스레드가 Branch로 인해 Stall되면, 다른 스레드를 실행하여 CPU 낭비를 줄이는 기법.
- 단점
- 멀티스레딩이 가능한 하드웨어 구조가 필요함.
- 모든 프로그램이 멀티스레딩을 활용할 수 있는 것은 아님.
2.5. Eliminate Control-Flow Instructions (Predicated Execution)
- 문제 해결 방식:
- Branch 없이 실행할 수 있도록 명령어를 변형하여 Control Dependency를 제거하는 기법.
- 예를 들어, 조건부 분기 대신에 Predicate Register를 사용하여 특정 명령어를 실행할지 여부를 결정.
- 예제
CMP r1, r2 // r1과 r2 비교
MOV.EQ r3, r4 // r1 == r2 이면 r3 = r4 수행 (Branch 필요 없음)-
일반적인 Branch와 다르게 하드웨어에서 Condition Register를 활용하여 실행 여부를 결정.
-
장점
- Branch 예측이 필요 없음 → Branch Misprediction(예측 실패)로 인한 Pipeline Flush 방지 가능.
-
단점
- 모든 조건을 검사해야 하므로, 실제로 필요하지 않은 연산도 수행될 수 있음 (Useless Work 발생).
- 예측 실패가 적은 경우에만 효과적.
2.6. Fetch from Both Possible Paths (Multipath Execution)
- 문제 해결 방식:
- Branch가 Taken이 되는 경우와 Not Taken이 되는 경우를 모두 실행.
- 실행이 확정되면 불필요한 경로를 취소.
- 단점
- 두 개의 경로를 실행하기 위해 두 배의 하드웨어 리소스 필요.
- 연산량이 급증하여 전력 소모가 커질 수 있음.
3. Optimizing Control Dependency Handling
3.1. Efficient Guessing of Next PC
- 가장 기본적인 방법은 항상 PC + 4를 가져오는 것.
- 하지만 Branch가 많은 경우 비효율적이므로, Branch Prediction을 활용하는 것이 일반적.
3.2. Predicate Combining
- 여러 개의 조건을 가진 분기를 하나의 단일 분기로 결합하는 기법.
- 여러 개의 Branch가 발생하는 것을 줄이기 위해 활용됨.
- 단점
- 조건을 합치다 보면 필요 없는 조건을 체크하는 경우가 발생할 수 있음.
- 즉, 성능 최적화가 필요함.
Branch Prediction in Pipelined Microarchitecture
1. Introduction: Why Branch Prediction?
Branch Prediction은 Control Dependency로 인해 발생하는 성능 저하를 줄이기 위한 기법입니다.
1.1. The Problem with Control Dependency
- Branch(분기) 명령어가 실행될 때, 다음 실행할 PC 값을 정확히 예측하기 어려움.
- 만약 Branch가 Taken(분기 발생) 되면, 기존에 Fetch된 명령어는 모두 폐기(Flush)되어야 함.
- 현대 프로세서에서는 30~40단계의 Deep Pipeline이 사용되므로, Branch Misprediction(예측 실패) 시 최대 10 Cycle 이상 손실이 발생할 수 있음.
- Branch 명령어는 프로그램 실행 중 15~20% 빈도로 등장하므로, 올바른 예측이 성능에 큰 영향을 미침.
2. How Branch Prediction Works
Branch Prediction의 목표는 Branch가 Taken인지 Not Taken인지 미리 예측하여 실행 속도를 높이는 것입니다.
2.1. Key Problems in Branch Prediction
- Is the instruction a branch?
→ Fetch 단계에서 Branch인지 아닌지 식별해야 함. - Will the branch be taken?
→ Branch가 실행될 것인지, 그대로 진행할 것인지 예측. - What is the target address?
→ Branch가 Taken일 경우, 정확한 Target Address를 찾아야 함.
이 3가지 문제를 해결하는 방법이 Branch Prediction 기법입니다.
3. Branch Prediction Approaches
Branch Prediction은 Static Prediction(컴파일 타임 예측)과 Dynamic Prediction(런타임 예측) 두 가지로 나뉩니다.
3.1. Static Branch Prediction
컴파일 시점에서 미리 Branch의 동작을 예측하는 방법.
1) Always Taken / Always Not Taken
- 항상 Taken으로 예측하거나 항상 Not Taken으로 예측하는 방식.
- 간단한 구현이 가능하지만 예측 정확도가 낮음.
2) Backward Taken, Forward Not Taken (BTFN)
- Loop(반복문)처럼 뒤로 가는 Branch는 Taken으로 예측.
- If-else 같은 Forward Branch는 Not Taken으로 예측.
- 일반적으로 60~70%의 예측 정확도를 가짐.
3) Profile-Based Prediction
- 컴파일러가 프로그램을 실행(Profiling)하여 Branch의 경향성을 분석.
- Branch Instruction에 Hint Bit를 추가하여 예측 방향을 저장.
- 실제 실행과 다를 경우 예측 실패 가능성 있음.
4) Predicate Combining
- 여러 개의 Branch를 하나의 복합적인 조건으로 결합하여 예측.
- Branch 수를 줄일 수 있지만, 필요 없는 조건 체크가 추가될 수 있음.
5) User-Defined Likely/Unlikely
- 개발자가 직접 Branch의 발생 가능성을 명시하는 방식.
- 예: __ builtin_expect()을 사용하여 Branch가 자주 발생하는지(likely) 또는 거의 발생하지 않는지(unlikely) 지정.
3.2. Performance Impact of Static Branch Prediction
- Example CPI Calculation
- 데이터 Hazard 없음.
- 전체 명령어 중 20%가 Branch Instruction.
- 70%의 Branch가 Taken.
- Branch Prediction이 틀릴 경우 Penalty = 2 Cycles.
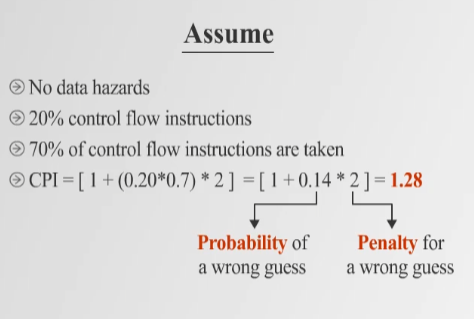
즉, Branch Prediction을 통해 CPI를 1.28로 낮출 수 있음.
Dynamic Branch Prediction in Pipelined Microarchitecture
1. Introduction: Why Dynamic Branch Prediction?
Branch Prediction은 Control Dependency로 인해 발생하는 성능 저하를 줄이기 위한 핵심 기법입니다.
1.1. The Need for Dynamic Branch Prediction
- Static Prediction은 단순한 방식이지만, 변화하는 실행 패턴을 고려하지 않음.
- Dynamic Branch Prediction은 실행 시점의 패턴을 학습하여 더 높은 정확도를 제공.
- Modern CPU에서는 Branch Prediction 실패 시 Pipeline Flush가 발생하여 큰 성능 저하가 있음.
- Branch가 Taken인지 Not Taken인지 예측해야 하고, Target Address도 빠르게 찾아야 함.
2. How Dynamic Branch Prediction Works
Dynamic Branch Prediction은 실행 시점에서 학습하며 예측 정확도를 높이는 방식입니다.
2.1. Key Problems to Solve
- Branch Instruction인지 판별
→ Branch인지 아닌지 구별하여 Prediction 적용. - Branch Taken 여부 예측
→ Taken인지 Not Taken인지 예측. - Branch Target Address 예측
→ Taken일 경우, 정확한 Target Address를 예측.
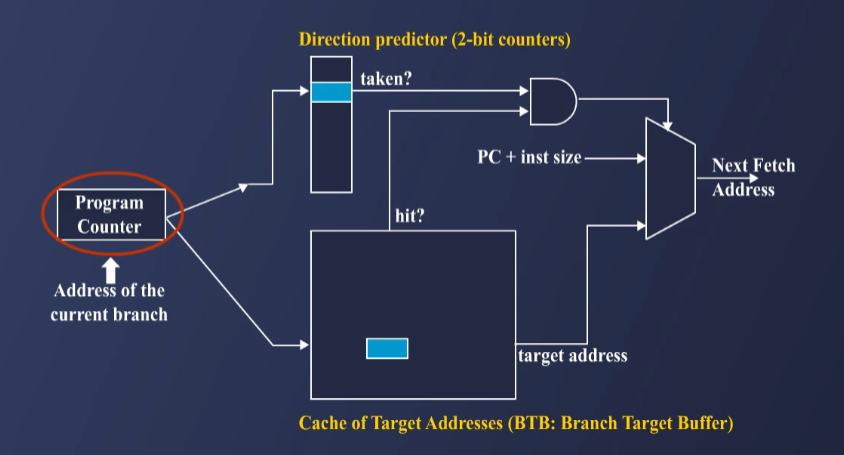
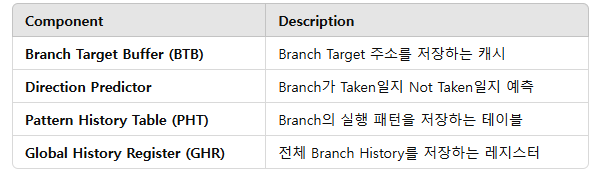
2.2. Key Hardware Components
3. Types of Dynamic Branch Predictors
3.1. Last Time Predictor (Single-Bit)


-
가장 간단한 방식으로, 마지막 실행 결과(Taken or Not Taken)를 저장하여 다음에 그대로 예측.
-
단순한 Loop에서는 높은 예측 정확도 (~90%).
-
하지만 TNTNTNTN(번갈아가며 실행되는 패턴)에서는 0% 예측 정확도.
-
단점: 하나의 Bit만 저장하므로, 변화가 많은 Branch에서는 예측 실패가 잦음.
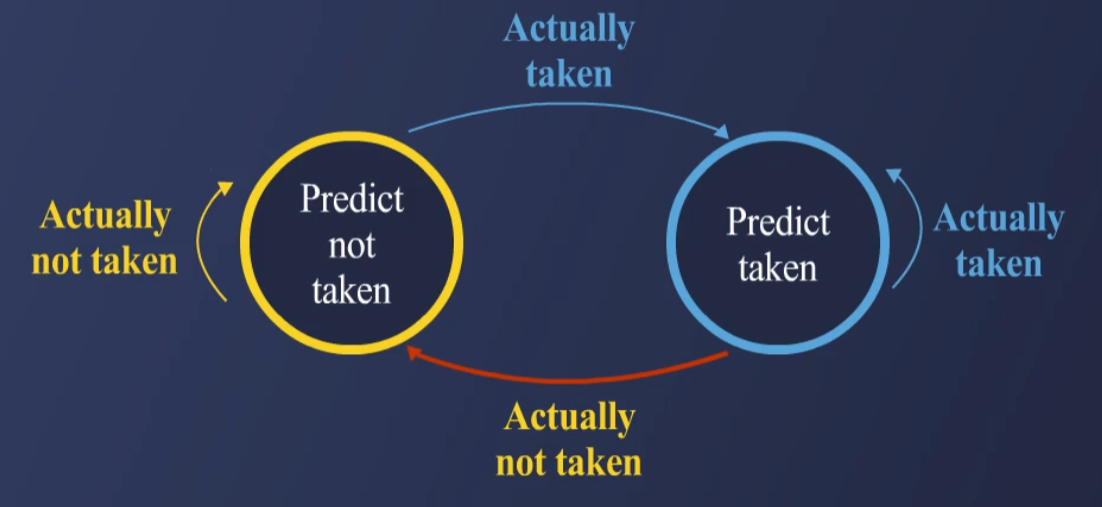
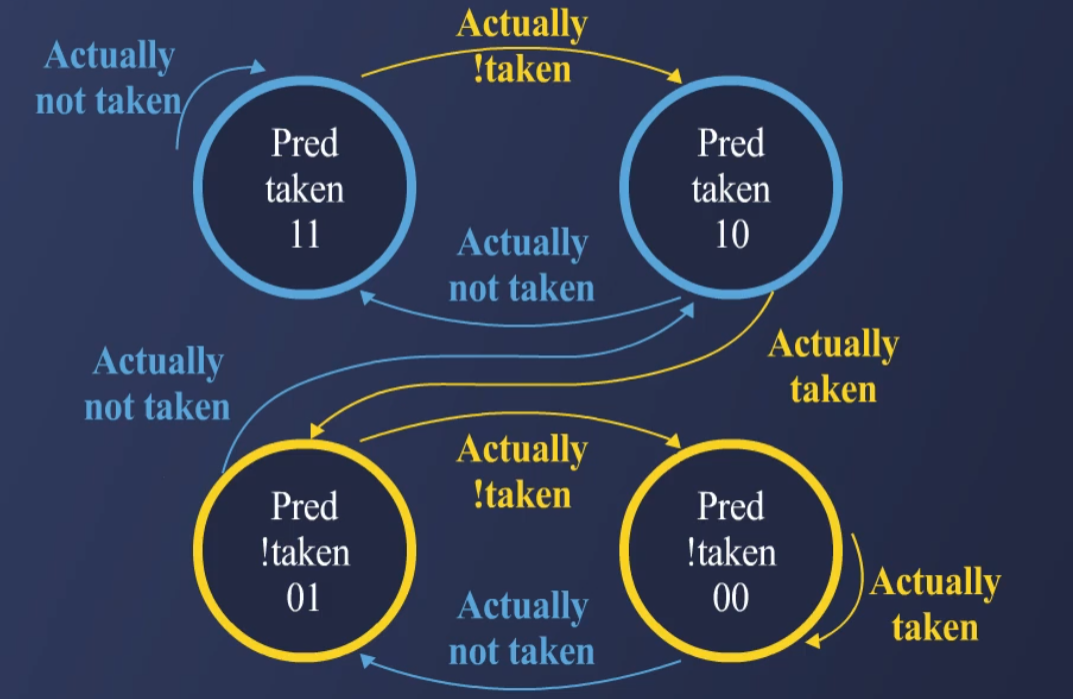
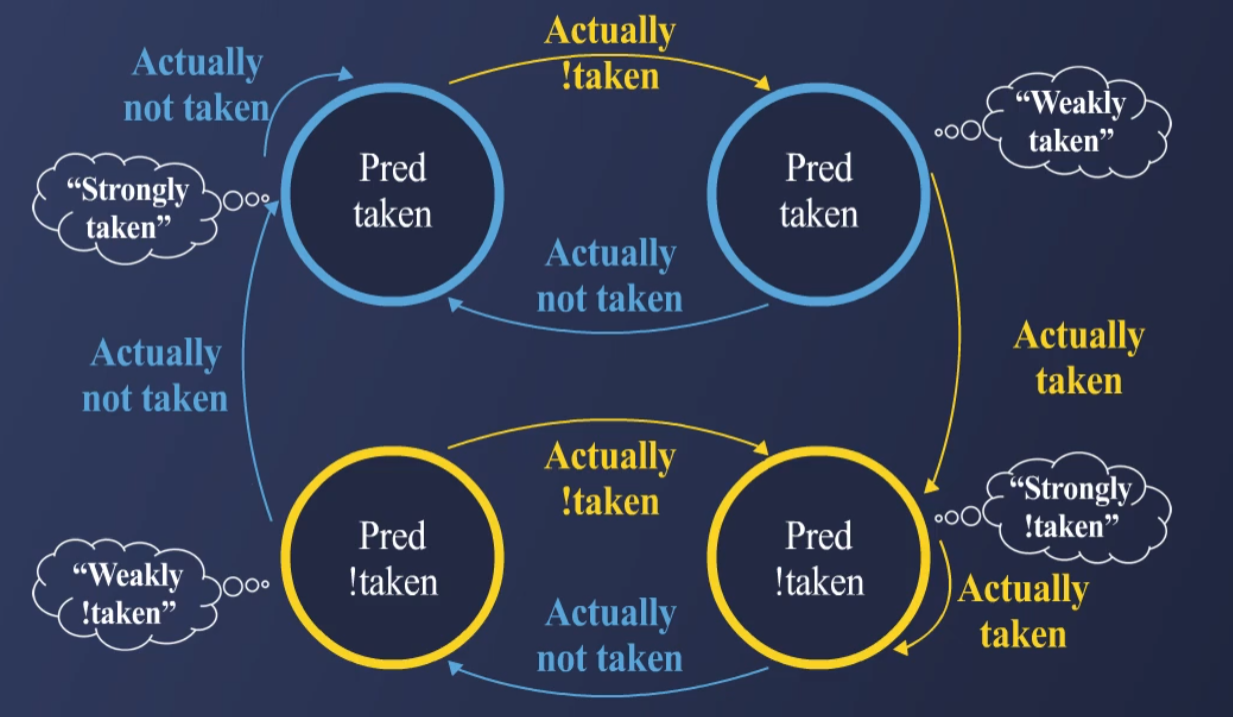
3.2. Two-Bit Saturating Counter
-
Last Time Predictor의 단점(Too Sensitive)을 개선한 방식.
-
2비트로 상태를 유지하며 빠르게 예측을 변경하지 않음.
-
상태 변화:
-
Strongly Taken (11) → Weakly Taken (10) → Weakly Not Taken (01) → Strongly Not Taken (00)
-
한 번의 Miss로 예측이 쉽게 변경되지 않도록 설계.
-
Loop와 같은 반복 구조에서 더 높은 예측 정확도를 제공 (95%).
-
단점: Pattern이 계속 바뀌는 경우에도 정확도가 떨어질 수 있음.
-
3.3. Branch Target Buffer (BTB)
- BTB는 Branch Target Address를 캐싱하는 구조.
- 한 번 실행된 Branch의 Target Address를 저장하여 Fetch 단계에서 바로 예측 가능.
- BTB Hit 시: 저장된 Target Address로 분기.
- BTB Miss 시: 기본적으로 PC+4를 사용하여 다음 명령어 Fetch.
How BTB Works
- Program Counter(PC)가 BTB에서 Branch Instruction을 찾음.
- 찾으면 저장된 Target Address로 Jump.
- Branch가 Taken인지 Not Taken인지는 Direction Predictor가 판단.
3.4. Two-Level Global Branch Prediction
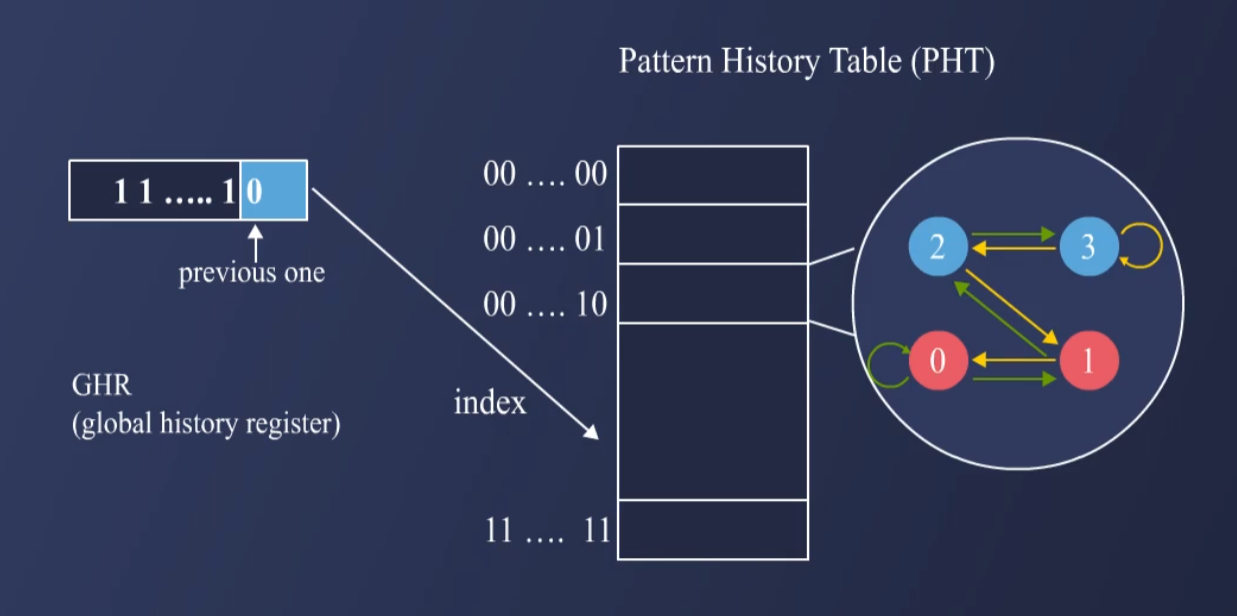
- Branch History를 저장하는 Global History Register(GHR)을 활용.
- 이전 여러 Branch 결과를 이용해 예측하는 방식.
- Pattern History Table (PHT)을 사용하여, 특정 패턴에서 Branch가 Taken인지 Not Taken인지 예측.
How it Works
1. GHR(Global History Register): 최근 Branch 결과 저장 (Taken/Not Taken).
2. PHT(Pattern History Table): GHR을 Index로 사용하여 과거의 예측 패턴을 참조.
3. Taken/Not Taken 여부를 결정하고, 예측을 업데이트.
3.5. GShare Predictor
- Two-Level Predictor의 확장 버전.
- PC 주소와 Global History를 XOR하여 더 나은 예측을 수행.
- Branch History와 Program Counter의 패턴을 결합하여 더욱 높은 정확도 제공 (~90% 이상).
How GShare Works
1. PC와 GHR 값을 XOR 연산하여 PHT 인덱스 생성.
2. 해당 인덱스에서 Two-Bit Counter를 읽고 Taken/Not Taken 예측.
3. Branch 결과에 따라 GHR을 업데이트하여 지속적인 학습.
