교차검증(Cross Validation)이란 데이터 셋을 여러 개의 하위 집합으로 나누어 돌아가면서 검증 데이터로 사용하는 방법
K-fold
-
Train Data를 K개의 하위 집합으로 나누어 모델을 학습시키고 최적화하는 방법
-
k는 분할 개수
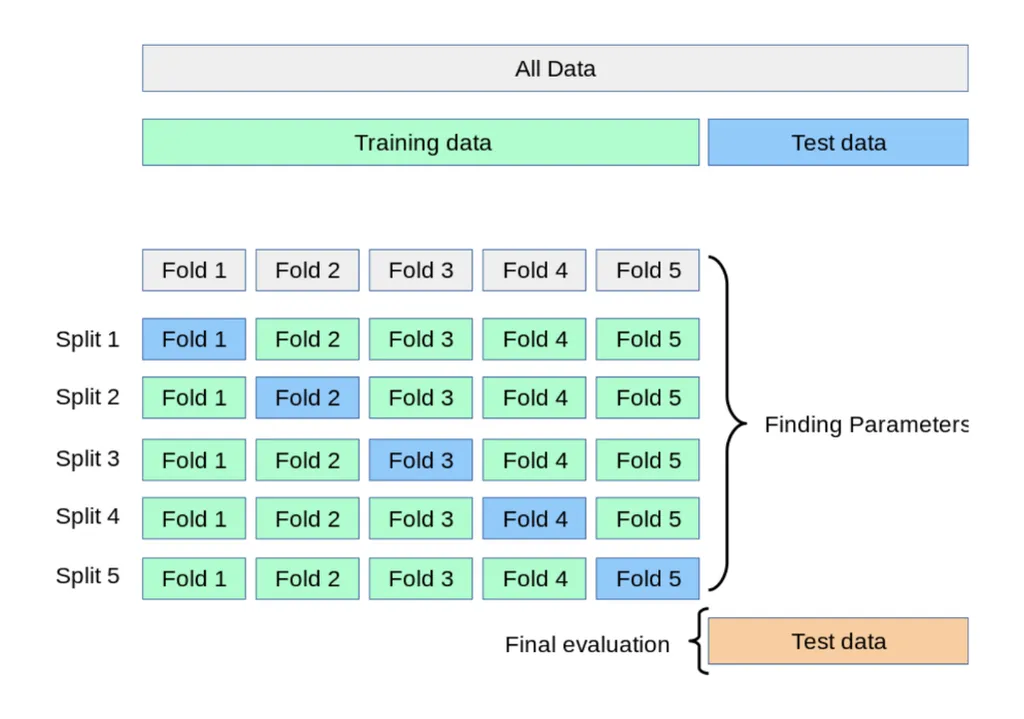
-
split 5까지 반복 후 최종 평가
-
데이터가 부족한 경우 유용
- 함수
skelarn.model_selection.KFoldsklearn.model_selection.StrifiedKFold: 불균형한 레이블(Y)를 가지고 있을 때 사용
실습
from sklearn.model_selection import KFold
import numpy as np
kfold = KFold(n_splits = 5)
scores = []
X = train_df_2[['Age_mm_sc','Fare_sd_sc','Family_mm_sc','Pclass_le',
'Sex_le','Embarked_C','Embarked_C','Embarked_C']]
y = train_df_2['Survived']
for i, (train_index, test_index) in enumerate(kfold.split(X)):
X_train, X_test = X.values[train_index], X.values[test_index]
y_train, y_test = y.values[train_index], y.values[test_index]
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score
model_lor2 = LogisticRegression()
model_lor2.fit(X_train,y_train)
y_pred2 = model_lor2.predict(X_test)
accuracy = accuracy_score(y_test, y_pred2).round(3)
print(i,'번째 교차검증 정확도는', accuracy)
scores.append(accuracy)
print('평균 정확도', np.mean(scores))결과:
0 번째 교차검증 정확도는 0.787
1 번째 교차검증 정확도는 0.798
2 번째 교차검증 정확도는 0.775
3 번째 교차검증 정확도는 0.763
4 번째 교차검증 정확도는 0.831
평균 정확도 0.7908
GridSearch 하이퍼 파라미터 자동 적용
하이퍼 파라미터: 모델을 구성하는 입력 값 중 사람이 임의적으로 바꿀 수 있는 입력 값
다양한 값을 넣고 실험할 수 있기 때문에 Grid Search로 이를 자동화
실습
from sklearn.model_selection import GridSearchCV
params = {'solver' : ['newton-cg','lbfgs','liblinear','sag','saga'],
'max_iter' : [100,200]}
grid_lor = GridSearchCV(model_lor2, param_grid = params, scoring='accuracy', cv = 5)
grid_lor.fit(X_train, y_train)
print('최고의 하이퍼 파라미터',grid_lor.best_params_)
print('최고의 정확도', grid_lor.best_score_.round(3))결과:
최고의 하이퍼 파라미터 {'max_iter': 100, 'solver': 'newton-cg'}
최고의 정확도 0.786

To Dare is To Do