ML
1.[ML] 머신러닝이란?
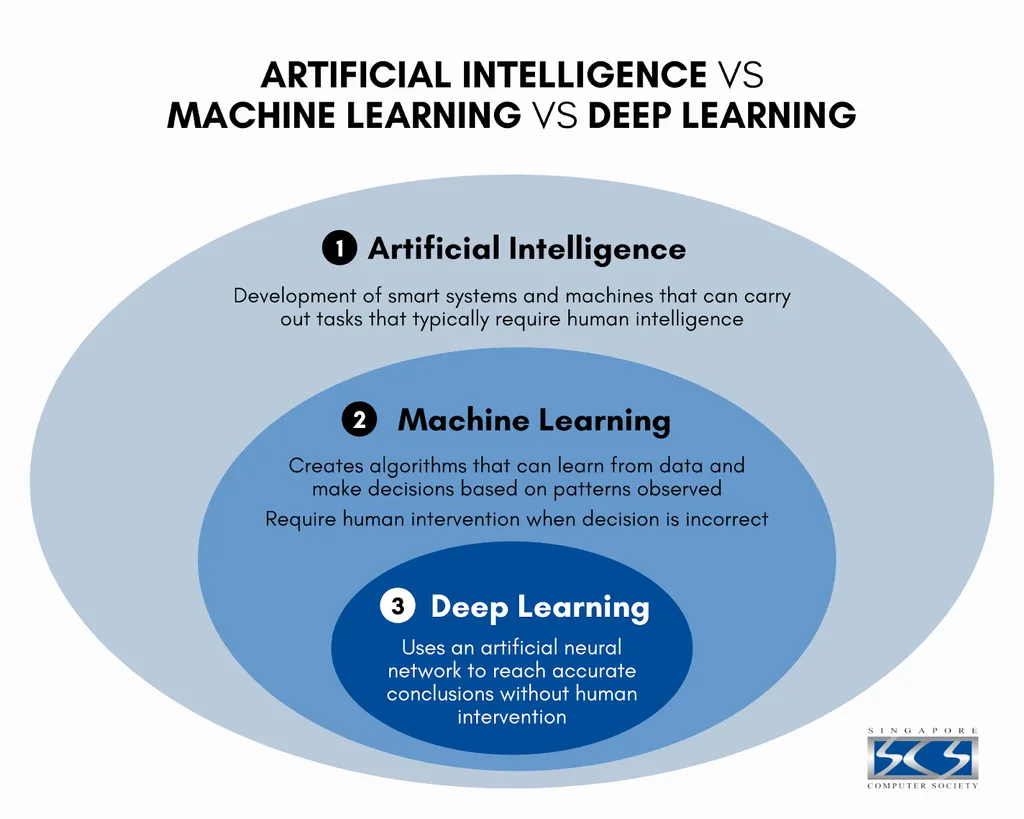
AI: 인간의 지능을 요구하는 업무를 수행하기 위한 시스템Machine Learning: 관측된 패턴을 기반으로 의사 결정을 하기 위한 알고리즘Deep Learning: 인공신경망을 이용한 머신러닝Data science: AI를 표괄하여 통계학과 컴퓨터공학을 바탕으로
2.[ML] 선형회귀

선형 회귀의 사례 몸무게와 키의 상관관계 찾아내기 > 방정식을 배운 머신이는 몸무게와 키의 데이터를 획득했다. 일정하게 증가하는 패턴이 있어서 미리 몸무게를 알면 키를 알 수 있을 것이라고 생각했다. 키와 몸무게 간의 데이터 키와 몸무게 간의 산점도 어떤 직선이
3.[ML] 분류 분석 | 로지스틱 회귀분석

PassengerId: 승객 식별자(Primary Key)Survival : 사망(0) 생존(1)Pclass: 티켓 등급(1,2,3 등급)Name: 이름Sex: 성별Age: 나이SibSp: 승객의 형제와 배우자 수Parch: 승객의 부모님과 자식 수Ticket: 티켓
4.[ML] 데이터 수집
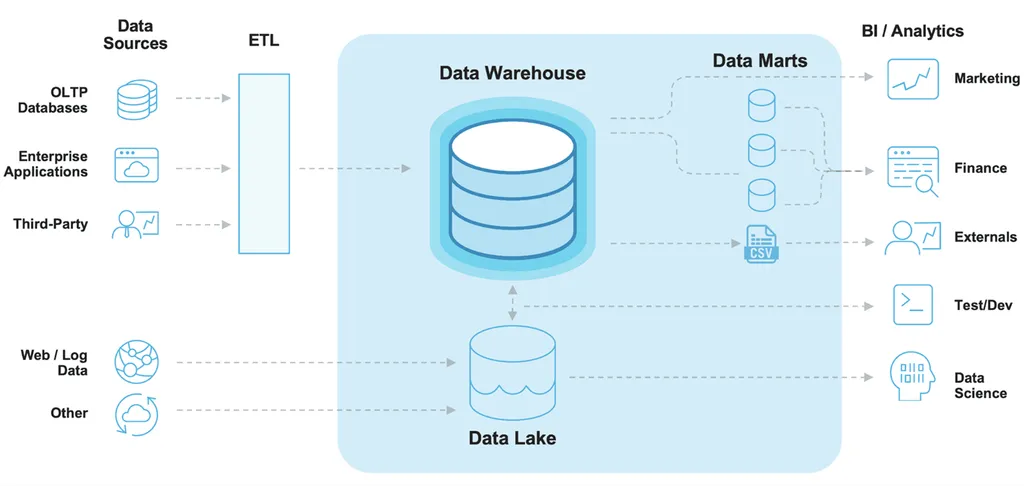
실제로 데이터를 수집하려면 개발을 통해 데이터를 적재하고 수집하는 데이터 엔지니어링 역량이 필요. 이 부분은 개발자가 직접 설계하고 저장. 데이터 분석가는 이미 존재하는 데이터를 SQL 혹은 Python 로 통해 추출하고 리포팅 혹은 머신러닝을 통한 예측을 담당. Da
5.[ML] 탐색적 데이터 분석 EDA

데이터의 시각화, 기술통계 등의 방법을 통해 데이터를 이해하고 탐구하는 과정. 데이터에 대한 정보를 얻을 수도 있고, 적절한 모델링에 대한 정보도 얻을 수 있음.예측 모델링이 아니더라도 데이터 분석에서는 반드시 필요. data.describe()include = 'al
6.[ML] 데이터 전처리 | 이상치, 결측치 처리
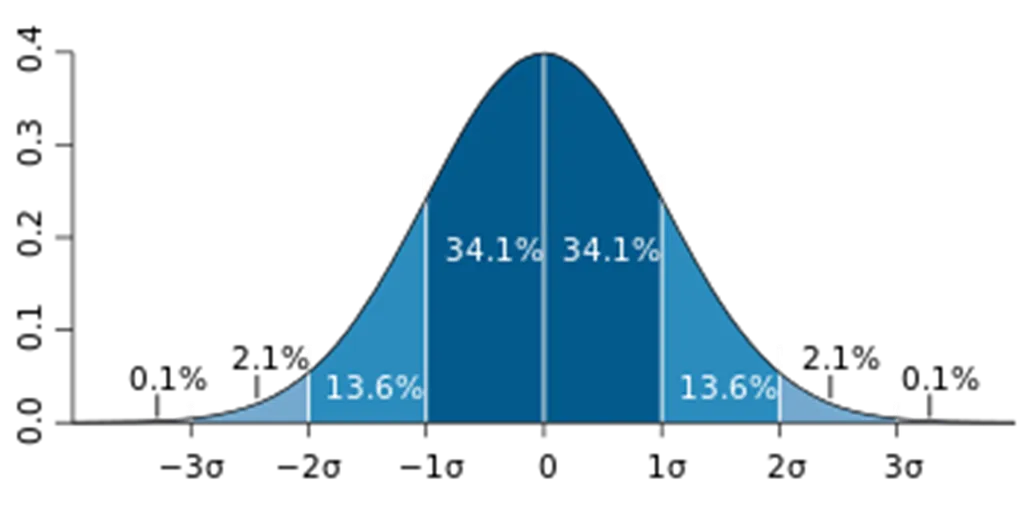
관측된 데이터 범위에서 크게 멋어난 아주 작은 값 혹은 아주 큰 값데이터가 정규분포를 따른다고 가정할 때, 평균에서 표준편차의 3배 이상 떨어져 있는 값을 이상치로 봄.모든 데이터가 정규 분포를 따르는 것은 아니기 때문에 아래 두 경우에는 적용 어려움데이터가 크게 비대
7.[ML] 데이터 전처리 | 범주형 데이터 인코딩

인코딩은 사전적으로 어떤 정보를 정해진 규칙에 따라 변환하는 것을 의미. 우리가 만든 머신러닝 모델은 숫자를 기반으로 학습하기 떄문에 반드시 인코딩 과정이 필요.문자열으로 정의된 범주 값을 고유한 숫자로 할당1등급 -> 02등급 -> 13등급 -> 2장점: 모델이 처리
8.[ML] 데이터 전처리 | 수치형 데이터 스케일링
각 데이터에 평균을 빼고 표준편차를 나누어 평균을 0, 표준편차를 1로 조정하는 방법$$ x{new} = \\frac{x - x{mean}}{x\_{std}}$$이상치가 있거나 분포가 치우쳐져 있을 때 유용모든 특성의 스케일을 동일하게 맞춤. 많은 알고리즘에서 좋은 성
9.[ML] 데이터 분리 | 과적합

국소적인 문제를 해결하는 것에 집중한 나머지 일반적인 문제를 해결하지 못하는 현상데이터를 너무 과도하게 학습한 나머지 해당 문제만 잘 맞추고 새로운 데이터를 제대로 예측 혹은 분류하지 못하는 현상모델의 복잡도모델이 지나치게 복잡할 때: 과적합모델이 지나치게 단순할 때:
10.[ML] 타이타닉 데이터로 실습

📍 전처리1\. SibSp와 Parch 합쳐서 Family 컬럼 만들기2\. 이상치, 결측치 처리3\. 숫자형 데이터 스케일링4\. 범주형 데이터 인코딩종속 변수: 성별(Sex), 나이(Age), 요금(Fare), 가족(Family), 등급(Pclass), 정박항(E
11.[ML] 교차검증 Cross validation | k-fold | GridSearch
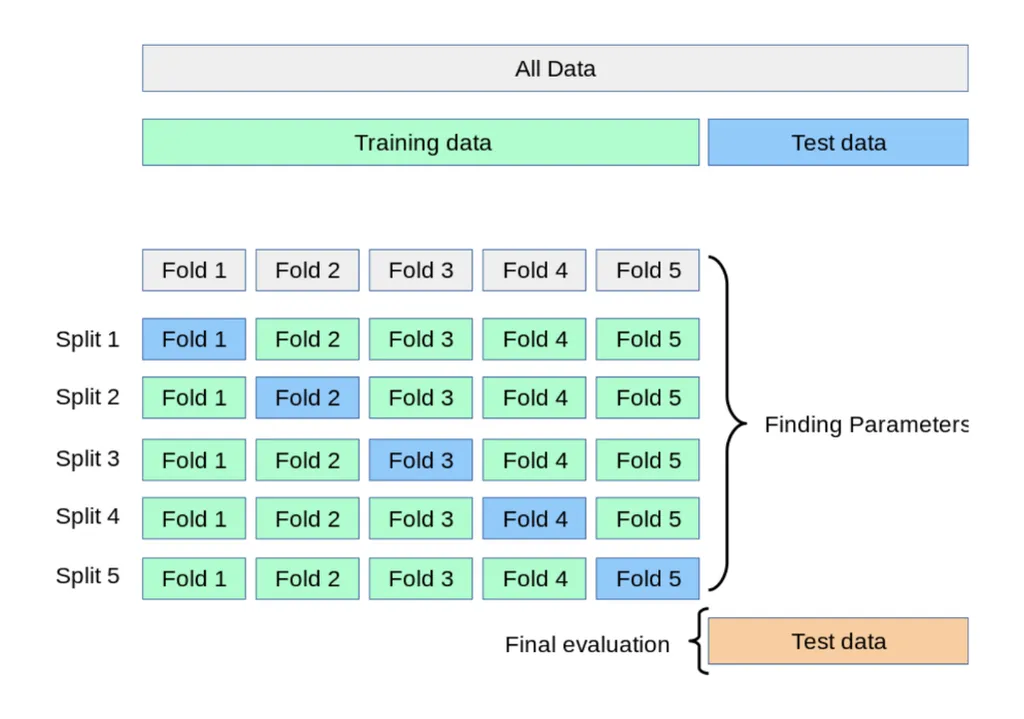
교차검증(Cross Validation)이란 데이터 셋을 여러 개의 하위 집합으로 나누어 돌아가면서 검증 데이터로 사용하는 방법Train Data를 K개의 하위 집합으로 나누어 모델을 학습시키고 최적화하는 방법k는 분할 개수split 5까지 반복 후 최종 평가데이터가
12.[ML] 의사결정 나무 Decision Tree

의사결정 규칙을 트리 구조로 나타내여 전체 자료를 몇 개의 소집단으로 분류하여 예측을 수행하는 분석 방법루트 노드(Root Node): 의사결정나무의 시작점. 최초의 분할조건리프 노드(Leaf Node): 루트 노드로부터 파생된 중간 혹은 최종 노드분류기준(criter
13.[ML] 랜덤 포레스트 Random Forest
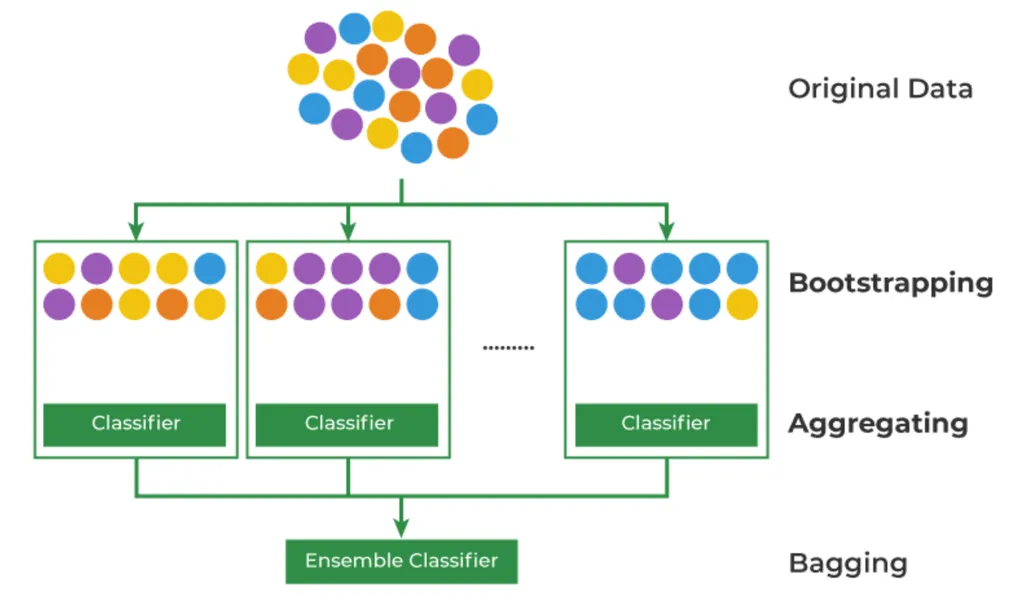
의사결정 나무의 과적합 취약성과 불안정성을 보완하기 위한 아이디어로, 트리 여러 개를 결합하여 숲(forest)를 만드는 것.머신러닝의 데이터 부족 문제를 해결하기 위한 Bootstrapping + Aggregating 방법론Bootstrapping: 데이터를 복원 추
14.[ML] knn | k nearest neighbor
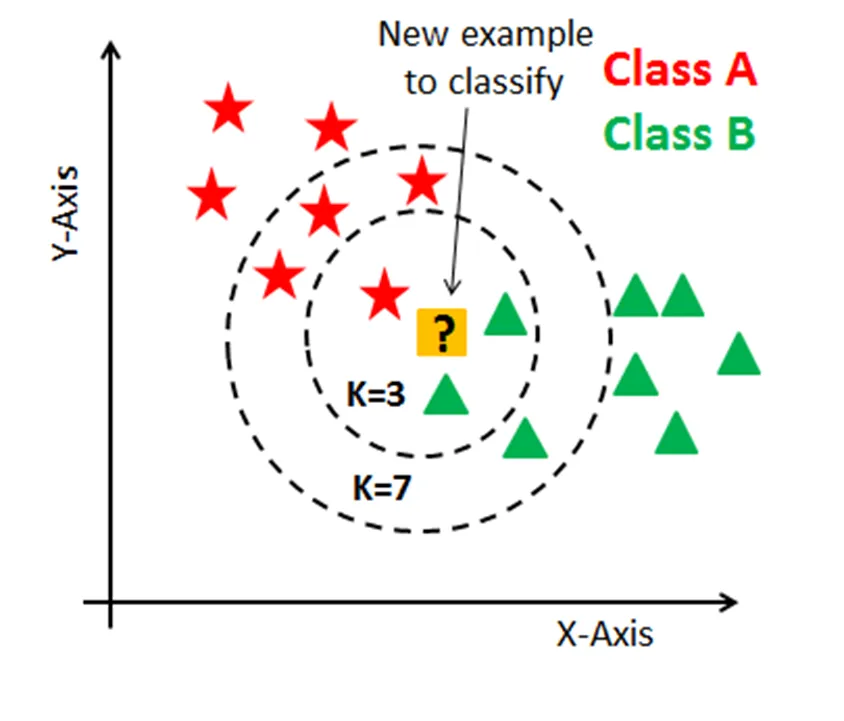
어떤 데이터가 주어졌을 때, 해당 데이터에 (거리 기준) 가장 근접한 k개의 데이터의 레이블에 따라 해당 데이터의 레이블을 예측하는 알고리즘.k = 3이라면, 가장 근접한 3개의 데이터는 별 1개와 세모 2개이므로 세모로 예측k = 7이라면, 가장 근접한 7개의 데이터
15.[ML] 부스팅 알고리즘 | 전체 실습
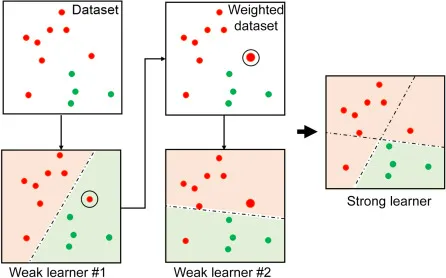
여러 개의 약한 학습기(weak learner)를 순차적으로 학습시키면서 잘못 예측한 데이터에 가중치를 부여하여 오류를 개선해 나가는 학습 방식가중치 업데이터를 경사 하강법을 통해 진행sklearn.ensemble.GradientBoostingClassifierskle
16.[ML] K-means clustering | 엘보우 기법 | 실루엣 계수
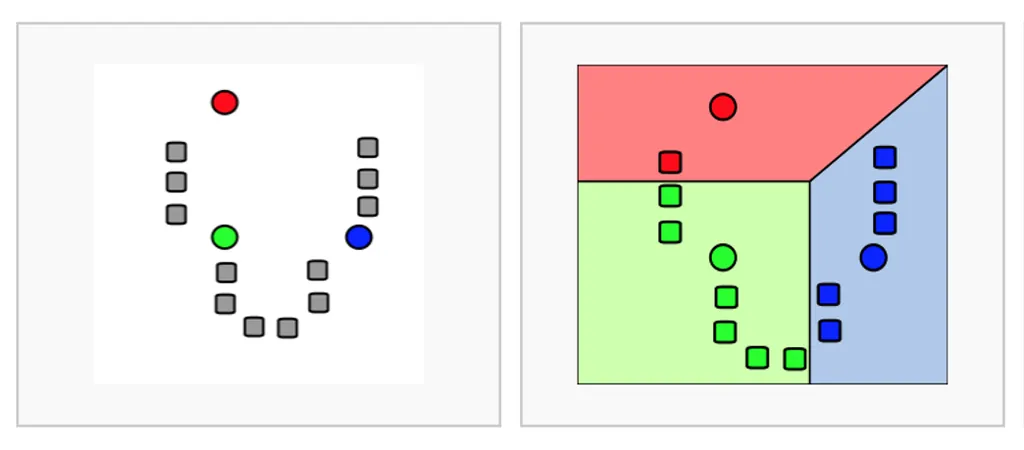
주어진 데이터를 k개의 군집으로 묶는 알고리즘으로순집 수 설정(K개)임의의 중심점 선정각 데이터를 가장 가까운 중심점에 할당하여 그룹화각 클러스터의 새로운 중심점 재계산3-4번을 클러스터의 중심이 더 이상 변하지 않을 때까지 반복데이터가 과도하게 일반화ex) 단 두 집
17.[ML] RFM 고객 세그먼테이션 실습

RFM이란? 데이터셋
18.[ML] 통계 + ML 과제 풀이

결측치 없음statistics csv 파일을 읽고, 성별 Review Rating 에 대한 평균과 중앙값을 동시에 구해주세요. 결과는 소수점 둘째자리까지 표현해주세요.그리고 이에 대한 해석을 간략하게 설명해주세요.결과 제출형태코드와 결과값해석결과:성별, Review R