표준화 Standardization
각 데이터에 평균을 빼고 표준편차를 나누어 평균을 0, 표준편차를 1로 조정하는 방법
특징
장점
- 이상치가 있거나 분포가 치우쳐져 있을 때 유용
- 모든 특성의 스케일을 동일하게 맞춤. 많은 알고리즘에서 좋은 성능을 보임
단점
- 데이터의 최대-최소 값이 정해져있지 않음
함수
- 함수:
sklearn.preprocessing.StandardScaler
- 메소드
fit: 데이터학습(평균과 표준편차를 계산)transform: 데이터 스케일링 진행- 속성
mean_: 데이터의 평균 값scale_,var_: 데이터의 표준 편차,분산 값n_features_in_: fit 할 때 들어간 변수 개수feature_names_in_: fit 할 때 들어간 변수 이름n_samples_seen_: fit 할 때 들어간 데이터의 개수
정규화 Normalizatoin
데이터를 0과 1 사이의 값으로 조정 (min = 0, max = 1)
특징
장점
- 모든 특성의 스케일을 동일하게 맞춤
- 최대-최소 범위가 명확
단점
- 이상치에 영향을 많이 받을 수 있음. 이상치가 없을 때 유용
함수
- 함수:
sklearn.preprocessing.MinMaxScaler
- (표준화와 공통인 것은 제외)
- 속성
data_min_: 원 데이터의 최소 값data_max_: 원 데이터의 최대 값data_range_: 원 데이터의 최대-최소 범위
실습
데이터 확인
- 수치형 데이터인 Age와 Fare 컬럼 확인하기
import seaborn as sns
sns.pairplot(titaninc_df[['Age','Fare']])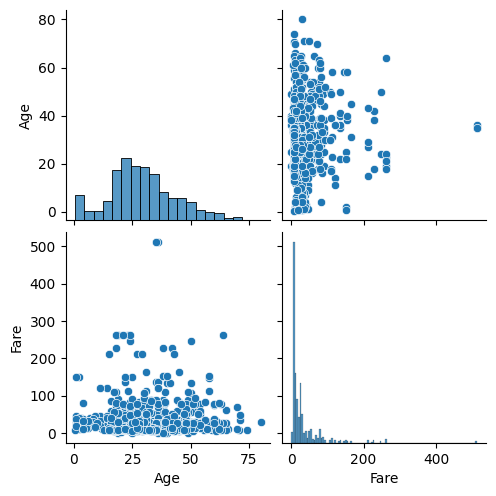
titaninc_df[['Age','Fare']].describe()
- Fare 컬럼은 한 쪽으로 치우쳐진 경향이 있기 때문에 standardization 진행
- Age 컬럼은 이상치가 없으므로 normalization 진행
스케일링 진행
- 모델 불러오기
from sklearn.preprocessing import MinMaxScaler, StandardScaler
mm_sc = MinMaxScaler() # normalization
sd_sc = StandardScaler() # standardization- 값 변환하기
titanic_df['Age_mean_mm_sc'] = mm_sc.fit_transform(titanic_df[['Age_mean']])
titanic_df['Fare_sd_sc'] = sd_sc.fit_transform(titanic_df[['Fare']])
titanic_df.head()
+) 로버스트 스케일링 Robust Scaling
중앙값과 IQR을 이용한 스케일링
특징
장점
- 이상치에 덜 민감함
단점
- 표준화와 정규화에 비해 덜 사용됨
함수
- 함수:
sklearn.preprocessing.RobustScaler
- 속성
center_: 훈련 데이터의 중앙값

To Dare is To Do