로지스틱 회귀 이론
타이타닉 생존 분류 문제
데이터셋 소개
import pandas as pd
titaninc_df = pd.read_csv('경로입력', encoding= 'utf-8')
titaninc_df.head(3)
변수 설명
- PassengerId: 승객 식별자(Primary Key)
- Survival : 사망(0) 생존(1)
- Pclass: 티켓 등급(1,2,3 등급)
- Name: 이름
- Sex: 성별
- Age: 나이
- SibSp: 승객의 형제와 배우자 수
- Parch: 승객의 부모님과 자식 수
- Ticket: 티켓 번호
- Fare: 요금
- Cabin: 객실 이름
- Embarked: 승선한 항구 C(Cherbourg), Q(Queenstown), S(Southampton)
가설 설정
"비상상황 특성 상 여성을 배려해 여성이 더 많이 생존했을 것이다."
확인 방법 1. pivot table
pd.pivot_table(titaninc_df, index = 'Sex', columns = 'Survived',aggfunc='size')
확인 방법 2. 그래프
import seaborn as sns
sns.countplot(titaninc_df, x = 'Sex', hue ='Survived')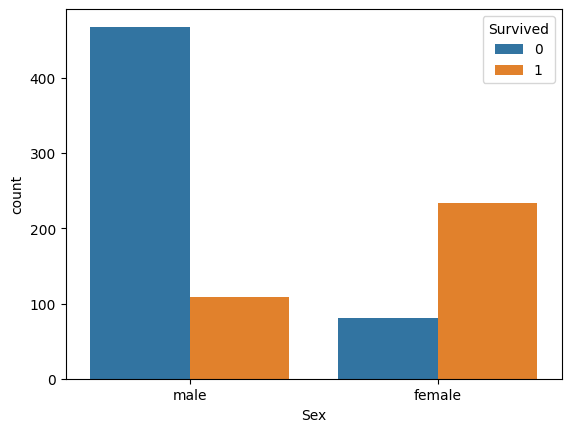
정확도 확인
- (233+468)/891*100 = 78.67564534231201
- 즉, 78.67%의 정확도.
하지만 Data-sceintific 하지 않으니 다른 도구를 배워보자.
로지스틱 회귀 이론
범주형 종속변수에서 선형 함수의 한계
X가 연속형 변수이고, Y가 특정 값이 될 확률이라고 설정한다면, 왼쪽 그림과 같이 선형으로 설명하긴 쉽지 않아 보인다. 확률은 0과 1사이 인데, 예측 값이 확률 범위를 넘어갈 수 있는 문제가 있음.
하지만 오른쪽 그림처럼 S자 형태의 함수를 적용하면 잘 설명한다고 할 수 있을 것이다.

로짓 개념의 등장
오즈비 Odds ratio (승산비)
패확률 대비 성공확률.
- 도박사들이 자주 쓰는 개념으로, 예를 들어 도박이 성공할 확률이 80% 라면, 오즈비는 80%/20% = 4. 즉, 1번 실패하면 4번은 딴다는 의미.
- 위 공식에서 P는 확률값으로 0과 1 사이인데, 이 경우 P가 증가하면 오즈비는 급격히 증가하고 선형성을 따르지 않음. (좌측 그래프)
- 따라서 log를 씌워 완화 (우측 그래프)
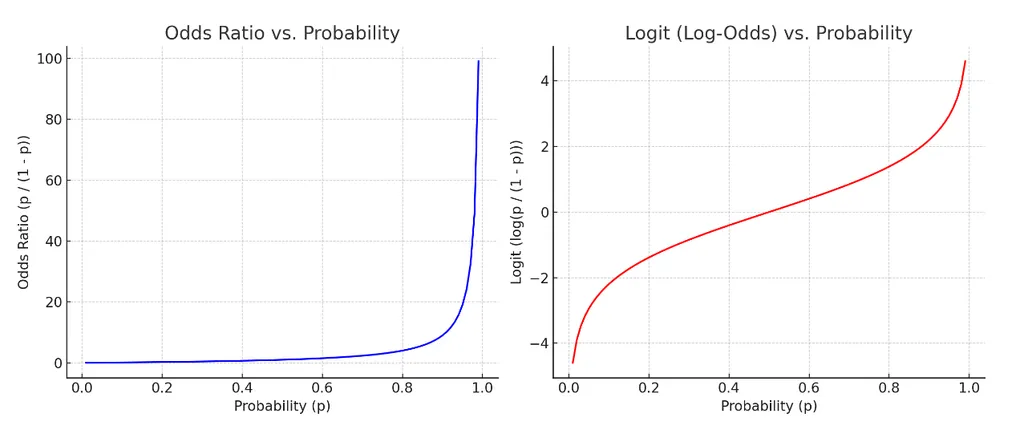
로짓의 장점: 어떤 값을 가져오더라도 반드시 특정 사건이 일어날 확률(Y값이 특정 값일 확률)이 0과 1 사이 값을 가짐
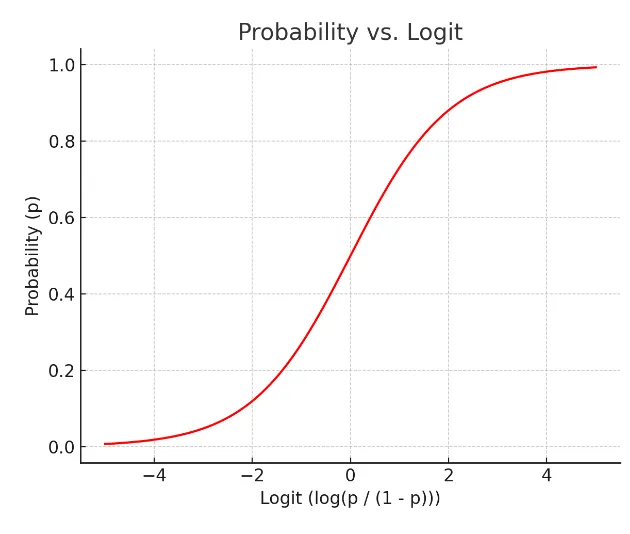
오즈비와 확률의 관계 (로짓과 확률의 관계)
- 로짓의 그래프가 오즈비 그래프보다 더 선형적인 그림을 나타내어 선형회귀의 기본식 활용 가능
- 로지스틱 '회귀'라고 불리는 이유이기도 함
로지스틱 함수
- 위 우측 그래프의 '확률-로짓'의 X-Y 관계를 교체
시그모이드 함수 중 하나로 딥러닝에서 활용.
값을 넣으면 확률이 도출된다.
- 로짓과 기존 선형회귀의 우변을 합치면
- 양변에 자연지수 를 취하면
- 해석: X값이 만큼 증가하면 오즈비는 만큼 증가한다.
로지스틱함수는 가중치 값을 안다면 X값이 주어졌을 때 해당 사건이 일어날 수 있는 의 확률을 계산할 수 있음. 이때, 확률 0.5를 기준으로 그보다 높으면 사건이 일어남(), 그렇지 않으면 사건이 일어나지 않음()으로 판단하여 분류 예측에 사용.
평가지표
정확도
정확도의 한계
예) 암 예측 모델
- 100명의 환자가 입실, 95명은 음성(정상), 5명은 양성(암 환자)
- 모든 환자에게 음성 진단을 내리면 정확도는 95%
- 정확도는 높지만, 실제 양성 암환자는 한 명도 맞추지 못함.
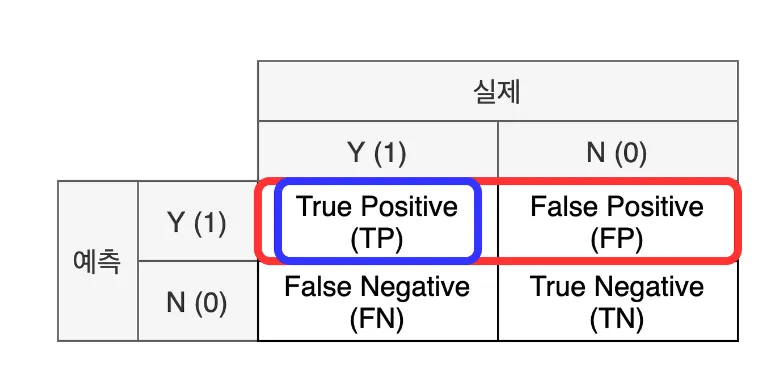
혼동 행렬 Confusion Matrix
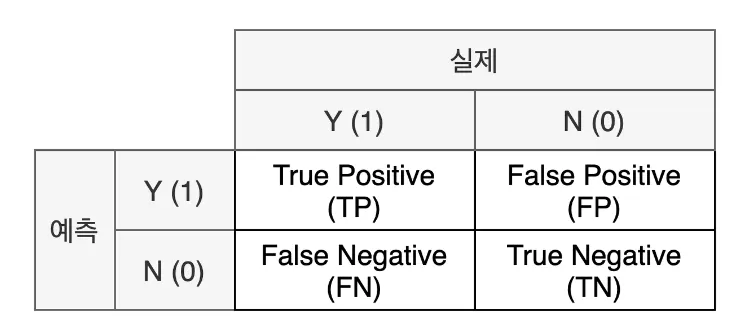
실제 값과 예측 값에 대한 모든 경우의 수를 표현하기 위한 2*2 행렬
-
실제와 예측이 같으면 True, 다르면 False
-
예측을 양성으로 했다면 Positive, 음성으로 했다면 Negative
-
해석
- TP: 실제로 양성(암 환자)이면서 양성(암 환자) 올바르게 분류된 수
- FP: 실제로 음성(정상인)이지만 양성(암 환자)로 잘못 분류된 수
- FN: 실제로 양성(암 환자)이지만 음성(정상인)로 잘못 분류된 수
- TN: 실제로 음성(정상인)이면서 음성(정상인)로 올바르게 분류된 수
정밀도 Precision
- 모델이 양성으로 예측한 결과 중 실제 양성의 비율 (모델 관점)
재현율 Recall
- 실제 양성 데이터 중 모델이 양성으로 예측한 비율 (데이터 관점)

- 암 진단 케이스처럼 FN의 발생을 줄여야 하는 경우는 재현율이 중요
F1-score
- 정밀도와 재현율의 조화 평균
정확도 Accuracy
실제 적용
- TP: 실제로 양성(암 환자)이면서 양성(암 환자) 올바르게 분류된 수 → 0명
- FP: 실제로 음성(정상인)이지만 양성(암 환자)로 잘못 분류된 수 → 0명
- FN: 실제로 양성(암 환자)이지만 음성(정상인)이라고 분류된 수 → 5명 (위험!)
- TN: 실제로 음성(정상인)이면서 음성(정상인)이라고 분류된 수 → 95명
- 정밀도는 정의되지 않음(divsion by zero), 재현율은 0
- 결과적으로 f1-score는 0
값이 unbalance하지 못할 때에는 정확도가 제기능을 못할 수 있음. 따라서 이를 위해서 Y 범주의 비율을 맞춰주거나 평가 지표를 f1 score을 사용함으로써 이를 보완해야 함.
실습
Fare - Survived
데이터 살펴보기
titaninc_df.head(3)
- 숫자형 데이터: Age, SibSp, Parch, Fare
- 범주형 데이터: Pclass, Sex, Cabin, Embarked
# info(): 데이터에 대한 결측치, 데이터전체 개수 등
titaninc_df.info()결과:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 891 entries, 0 to 890
Data columns (total 12 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 PassengerId 891 non-null int64
1 Survived 891 non-null int64
2 Pclass 891 non-null int64
3 Name 891 non-null object
4 Sex 891 non-null object
5 Age 714 non-null float64
6 SibSp 891 non-null int64
7 Parch 891 non-null int64
8 Ticket 891 non-null object
9 Fare 891 non-null float64
10 Cabin 204 non-null object
11 Embarked 889 non-null object
dtypes: float64(2), int64(5), object(5)
memory usage: 83.7+ KBX 변수: Fare
Y 변수: Survived
데이터 분포 확인하기
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.linear_model import LogisticRegression
sns.scatterplot(titaninc_df, x = 'Fare',y = 'Survived')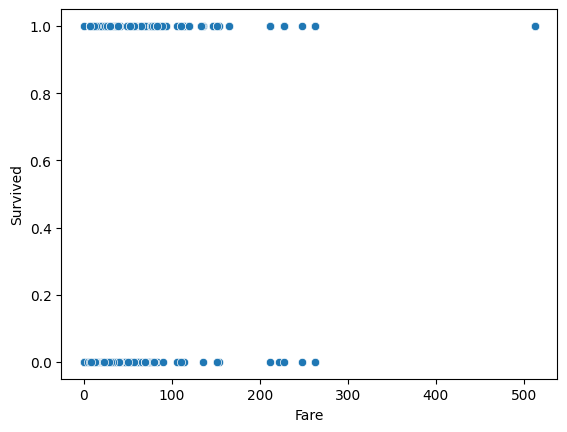
- 기대한 모양이 나오지 않은 것 확인.
- Fare의 데이터 분포 먼저 확인!
sns.histplot(titaninc_df, x = 'Fare')
titaninc_df.describe()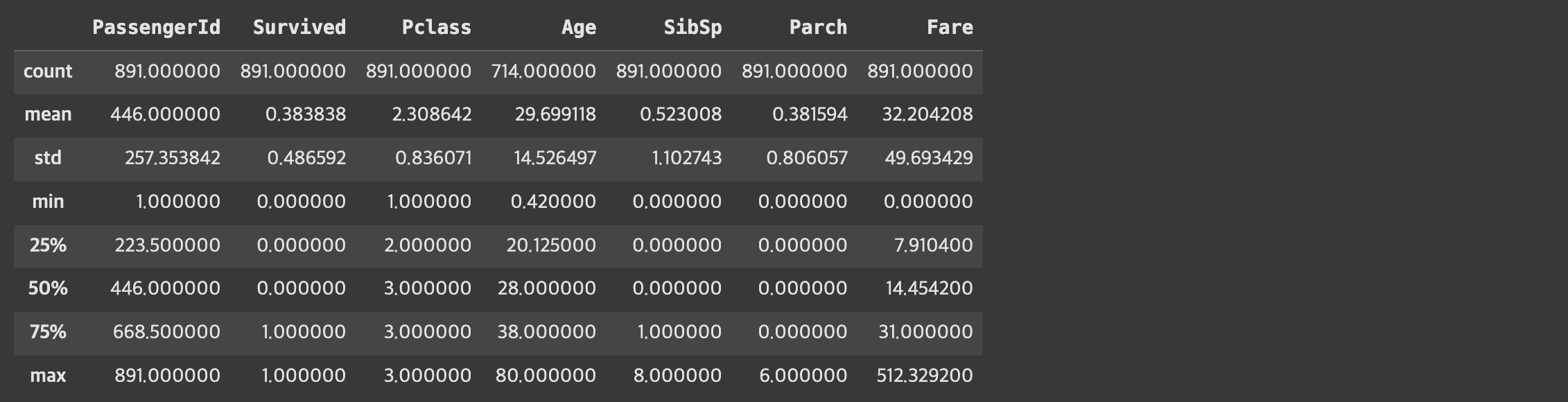
- Fare의 평균은 약 32$, 중위값 약 14$, 표준편차 약 50 등이라는 것을 확인할 수 있음.
모델 학습시키기
X_1 = titaninc_df[['Fare']]
y_true = titaninc_df[['Survived']]
model_lor = LogisticRegression()
model_lor.fit(X_1, y_true)학습된 모델 속성 확인하기
# 함수 정의
def get_att(x):
#x모델을 넣기
print('클래스 종류', x.classes_)
print('독립변수 개수', x.n_features_in_)
print('들어간 독립변수(x)의 이름',x.feature_names_in_)
print('가중치',x.coef_)
print('바이어스', x.intercept_)
get_att(model_lor)결과:
클래스 종류 [0 1]
독립변수 개수 1
들어간 독립변수(x)의 이름 ['Fare']
가중치 [[0.01519666]]
바이어스 [-0.94131796]
평가하기
from sklearn.metrics import accuracy_score, f1_score
# 함수 정의하기
def get_metrics(true, pred):
print('정확도', accuracy_score(true, pred))
print('f1-score', f1_score(true, pred))
# Fare로 예측한 Survived
y_pred_1 = model_lor.predict(X_1)
get_metrics(y_true, y_pred_1)결과:
정확도 0.6655443322109988
f1-score 0.35497835497835495
다중 로지스틱 회귀
X 변수: Fare (수치형), Sex, Pclass (범주형)
Y 변수: Survived
데이터 전처리
# 문자열로 된 성별 데이터를 0, 1로 변경
def get_sex(x):
if x == 'female':
return 0
else:
return 1
titaninc_df['Sex_en'] = titaninc_df['Sex'].apply(get_sex)모델 학습시키기
X_2 = titaninc_df[['Pclass','Sex_en','Fare']]
y_true = titaninc_df[['Survived']]
model_lor_2 = LogisticRegression()
model_lor_2.fit(X_2,y_true)학습된 모델 속성 확인하기
get_att(model_lor_2)결과:
클래스 종류 [0 1]
독립변수 갯수 3
들어간 독립변수(x)의 이름 ['Pclass' 'Sex_en' 'Fare']
가중치 [[-8.88331324e-01 -2.53993425e+00 1.64019087e-03]]
바이어스 [3.02004403]
평가하기
y_pred_2 = model_lor_2.predict(X_2)
get_metrics(y_true, y_pred_2)결과:
정확도 0.7867564534231201
f1-score 0.7121212121212122
+) 각 데이터가 0 또는 1로 분류될 확률 확인하기
- model.predict_proba(data)
model_lor_2.predict_proba(X_2)결과:
array([[0.8977979 , 0.1022021 ], # [0으로 분류될 확률, 1로 분류될 확률]
[0.09546762, 0.90453238],
[0.40901264, 0.59098736],
...,
[0.40287202, 0.59712798],
[0.58880217, 0.41119783],
[0.89772263, 0.10227737]])모델링 기본 마무리
- 선형 회귀와 로지스틱 회귀의 공통점
- 모델 생성이 쉬움
- 가중치 (회귀계수) 통한 해석이 쉬움
- X변수에 범주형, 수치형 변수 둘 다 사용 가능
- 차이점
| 선형회귀(회귀) | 로지스틱 회귀(분류) | |
|---|---|---|
| Y(종속변수) | 수치형 | 범주형 |
| 평가척도 | Mean Square Error, R-square | Accuracy, F1-score |
| 모델 | sklearn.linear_model.LinearRegression | sklearn.linear_model.LogisticRegression |
| 평가 | sklearn.metrics.mean_squared_error, sklearn.metrics.r2_score | sklearn.metrics.accuracy_score, sklearn.metrics.f1_Score |
