RFM 고객 세그멘테이션이란?
- 고객 세그먼테이션: 다양한 기준으로 고객을 분류하는 기법. 고객을 특성에 맞게 세분화하여 유형에 따라 맞춤형 마케팅이나 서비스를 제공하는 것이 목표.
RFM의 개념
- Recency: 가장 최근 구입일에서 오늘까지의 시간
- Frequency: 상품 구매 횟수
- Monetary value: 총 구매 금액
데이터셋 살펴보기
InvoiceNO: 6자리의 주문번호(취소된 주문은 c 로 시작)StockCode: 5자리의 제품 코드Description: 제품 이름(설명)Quantity: 주문 수량InvoiceDate: 주문 일자, 날짜 자료형UnitPrice: 제품 단가CustomerID: 5자리의 고객 번호Country: 국가명
!pip install openpyxl
from google.colab import drive
drive.mount('/content/drive')
file_path = '/content/drive/MyDrive/내배캠 실습/ML/Online Retail.xlsx'
retail_df = pd.read_excel(file_path)
retail_df.head(3)
- 컬럼 info 확인
retail_df.info()
# 결과:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 541909 entries, 0 to 541908
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 InvoiceNo 541909 non-null object
1 StockCode 541909 non-null object
2 Description 540455 non-null object
3 Quantity 541909 non-null int64
4 InvoiceDate 541909 non-null datetime64[ns]
5 UnitPrice 541909 non-null float64
6 CustomerID 406829 non-null float64
7 Country 541909 non-null object
dtypes: datetime64[ns](1), float64(2), int64(1), object(4)
- 결측값 확인
retail_df.isnull().sum()
데이터 EDA
retail_df.describe(include = 'all')
알 수 있는 내용
CustomerID컬럼에 결측치가 있음InvoiceNo컬럼에 결측치가 많음Quantity,UnitPrice컬럼에 음수가 있음Country컬럼에는 'United Kingdom' 값이 가장 많음- 전체 고객에 대해 가장 마지막 주문 날짜는 '2011-12-09'
Quantity가 0보다 작은 행 확인
cond1 = retail_df['Quantity']< 0
retail_df[cond1]
전처리 전략
CustomerID가 결측치인 행 삭제InvoiceNo가 C로 시작하거나,Quantity가 음수이거나,UnitPrice가 음수인 행 삭제
전처리
전처리 대상에 해당하는 행 삭제 (위 4개 조건)
cond_cust = (retail_df['CustomerID'].notnull())
cond_invo = (retail_df['InvoiceNo'].astype(str).str[0] != 'C')
cond_minus = (retail_df['Quantity'] > 0) & (retail_df['UnitPrice'] > 0)
retail_df_2 = retail_df[cond_cust & cond_invo & cond_minus]
retail_df_2.info()
# retail_df_2 결과
<class 'pandas.core.frame.DataFrame'>
Index: 397884 entries, 0 to 541908
Data columns (total 8 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 InvoiceNo 397884 non-null object
1 StockCode 397884 non-null object
2 Description 397884 non-null object
3 Quantity 397884 non-null int64
4 InvoiceDate 397884 non-null datetime64[ns]
5 UnitPrice 397884 non-null float64
6 CustomerID 397884 non-null float64
7 Country 397884 non-null object
dtypes: datetime64[ns](1), float64(2), int64(1), object(4)Country 컬럼에서 특정 국가(United Kingdom)만 남기기
retail_df_2['Country'].value_counts()[:10]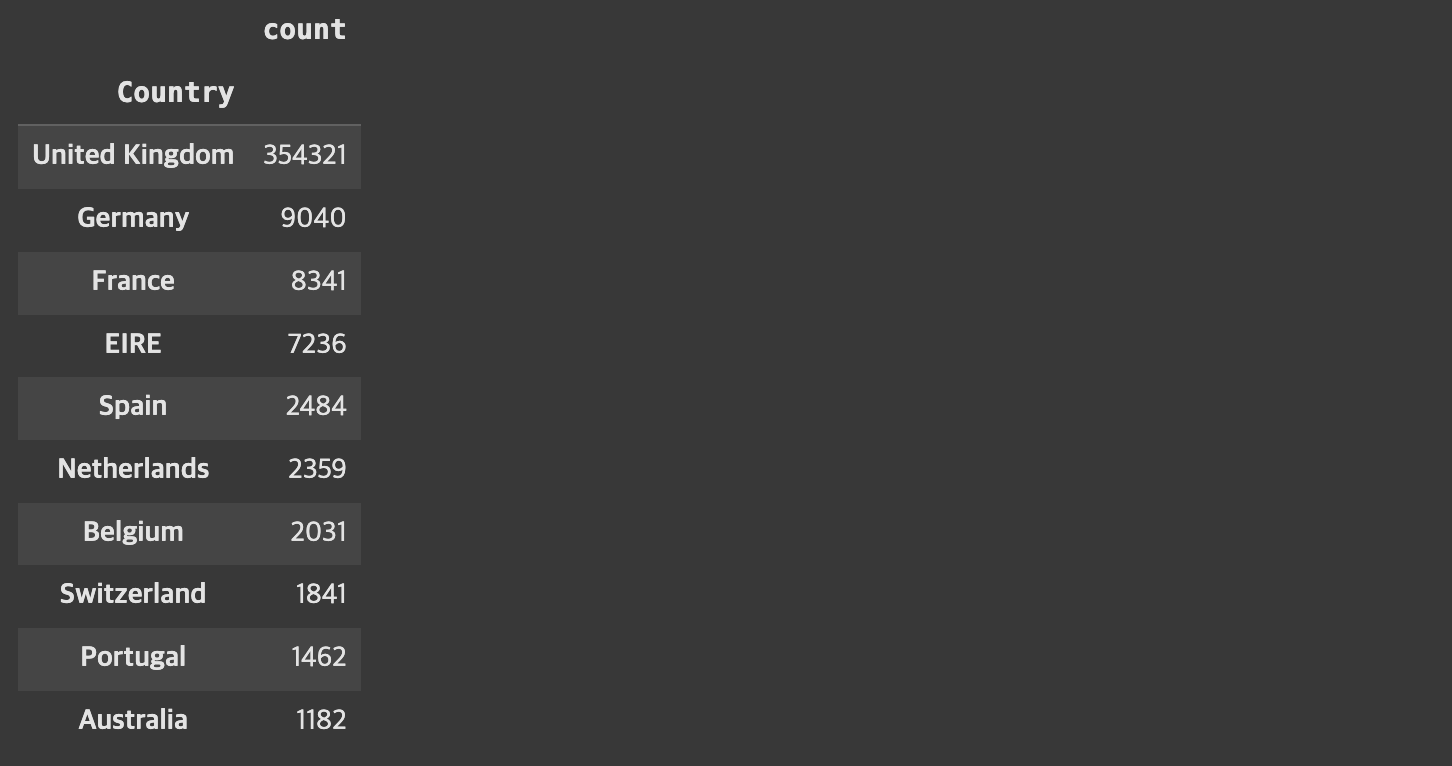
cond_uk = (retail_df_2['Country'] =='United Kingdom')
retail_df_2 = retail_df_2[cond_uk]각 행 별 주문 금액 컬럼 추가
retail_df_2['Amt'] = retail_df_2['Quantity'] * retail_df_2['UnitPrice'] # amount
retail_df_2['Amt'] = retail_df_2['Amt'].astype('int') # 정수형으로 변환고객ID 별 총 주문금액 (Monetary value) 구하기
retail_df_2.pivot_table(index = 'CustomerID', values = 'Amt', aggfunc='sum').sort_values('Amt', ascending=False)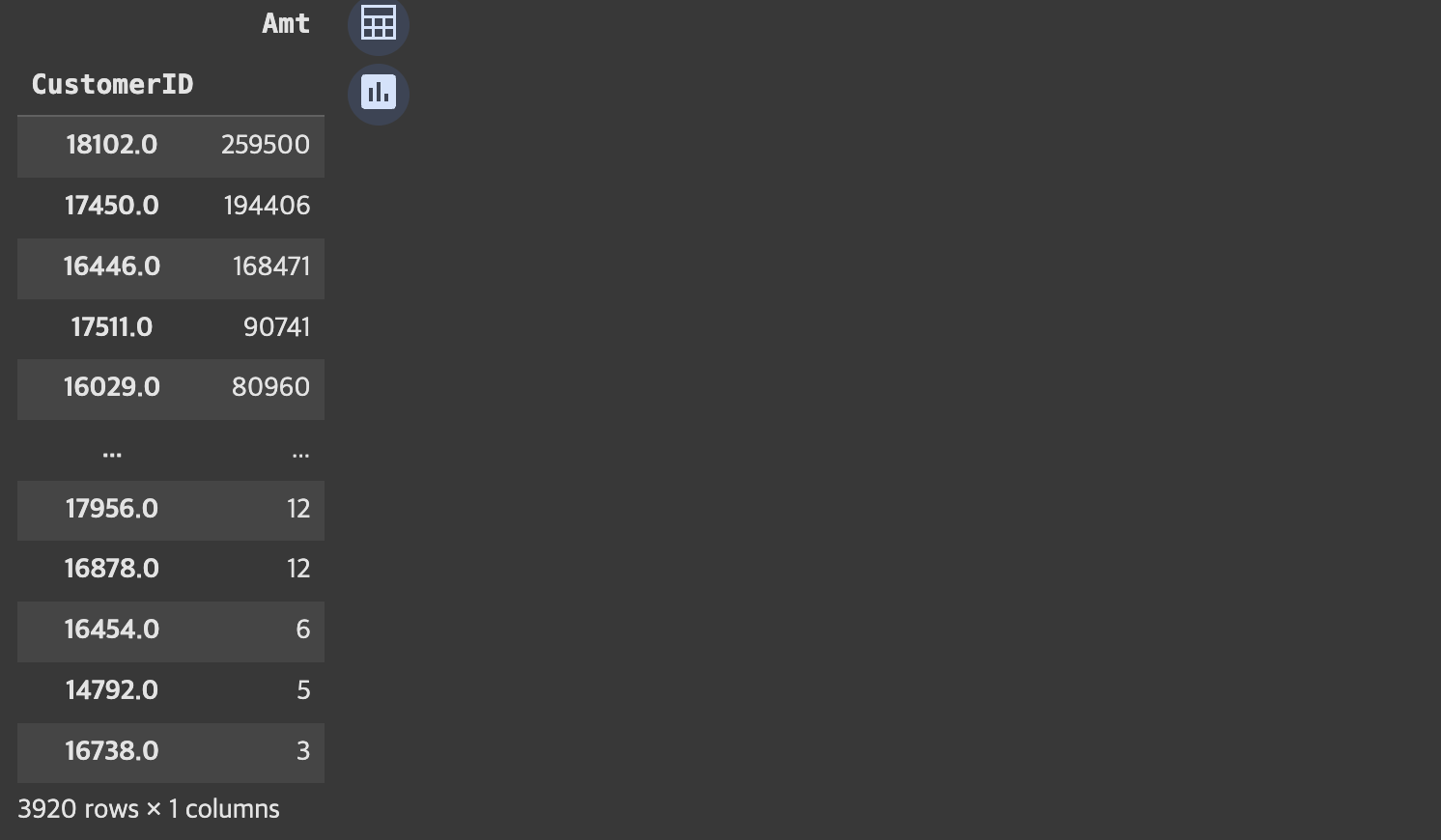
Recency 구하기
import datetime as dt
# 2011.12.10일 기준으로 각 날짜를 빼고 + 1 -> Period
# Period = 주문 날짜와 현재 날짜 사이의 기간 (작을수록 최근 주문)
# CustomerID 기준으로 Priod의 최소의 Priod를 구하면 그것이 Recency
retail_df_2['Period'] = (dt.datetime(2011,12,10) - retail_df_2['InvoiceDate']).apply(lambda x: x.days+1)
retail_df_2.head(3)
RFM DataFrame 완성시키기
rfm_df = retail_df_2.groupby('CustomerID').agg({
'Period' : 'min',
'InvoiceNo' : 'count',
'Amt' : 'sum'
})
# 컬럼명 변경
rfm_df.columns = ['Recency','Frequency','Monetary']
rfm_df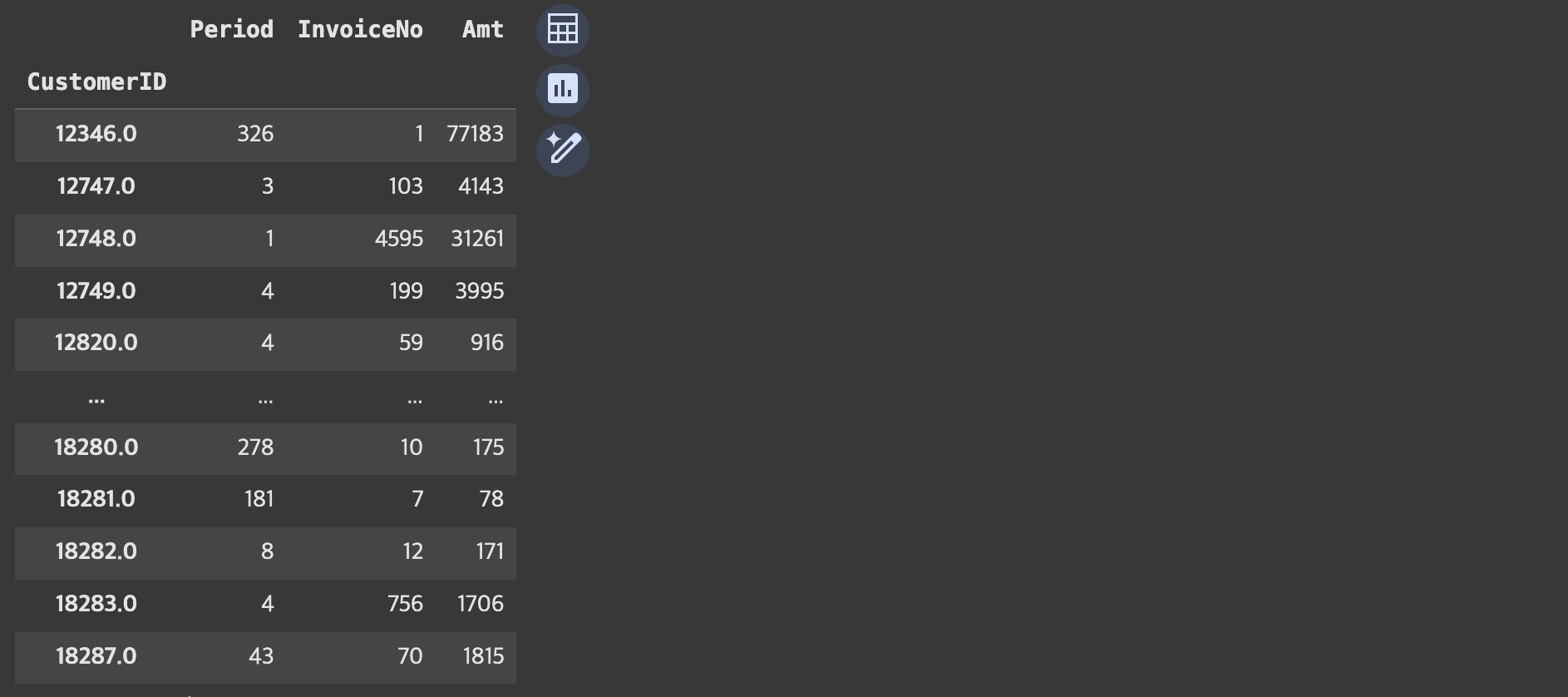
컬럼별 분포 확인
Recency
sns.histplot(rfm_df['Recency'])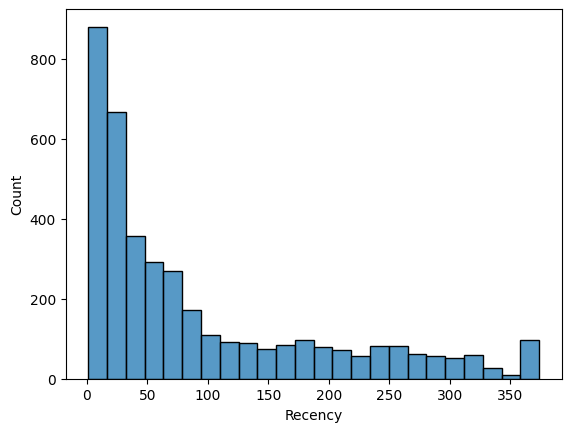
Frequency
sns.histplot(rfm_df['Frequency'])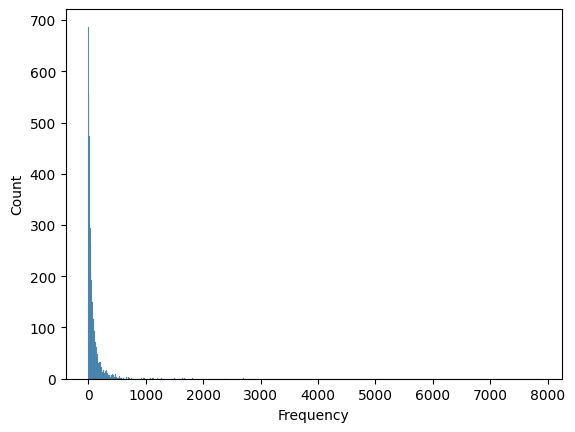
Monetary
sns.histplot(rfm_df['Monetary'])
데이터 정규화
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_features = sc.fit_transform(rfm_df[['Recency','Frequency','Monetary']])Kmeans clustering 및 실루엣 계수 구하기
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
kmeans = KMeans(n_clusters = 3, random_state = 42)
labels = kmeans.fit_predict(X_features)
rfm_df['label'] = labels
silhouette_score(X_features, labels)
# 0.5930190673437187군집화 시각화하여 확인해보기
kmeans_visual: 군집을 시각화하는 사용자 정의 라이브러리
from kmeans_visaul import visualize_silhouette
visualize_silhouette([2,3,4,5,6], X_features) # [] = cluster 개수
# cluster 개수가 2, 3, 4, 5, 6개일 때 군집 시각화 + 실루엣 계수 반환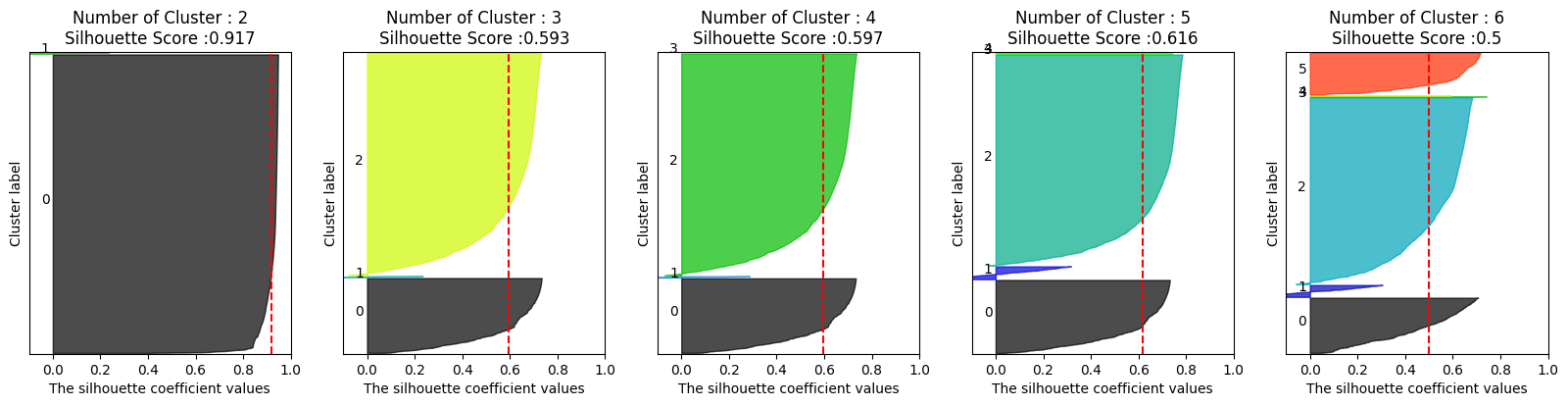
- 군집화가 균일하게 이루어지지 않은 것으로 보인다.
ex) Number of cluster = 3 인데 하나의 클러스터는 거의 보이지 않음. 군집이 4개 이상일 때도 마찬가지.
📍 로그 스케일을 통한 추가 전처리가 필요할 것으로 보임
log scaling을 통한 추가 전처리
import numpy as np
rfm_df['Recency_log'] = np.log1p(rfm_df['Recency'])
rfm_df['Frequency_log'] = np.log1p(rfm_df['Frequency'])
rfm_df['Monetary_log'] = np.log1p(rfm_df['Monetary'])다시 군집화 확인
X_features2 = rfm_df[['Recency_log','Frequency_log','Monetary_log']]
sc2 = StandardScaler()
X_features2_sc = sc2.fit_transform(X_features2)
visualize_silhouette([2,3,4,5,6], X_features2_sc)
- 실루엣 계수는 낮으나 로그 스케일링 이전보다 훨씬 잘 군집화된 것을 확인할 있다.

To Dare is To Do