knn
어떤 데이터가 주어졌을 때, 해당 데이터에 (거리 기준) 가장 근접한 k개의 데이터의 레이블에 따라 해당 데이터의 레이블을 예측하는 알고리즘.
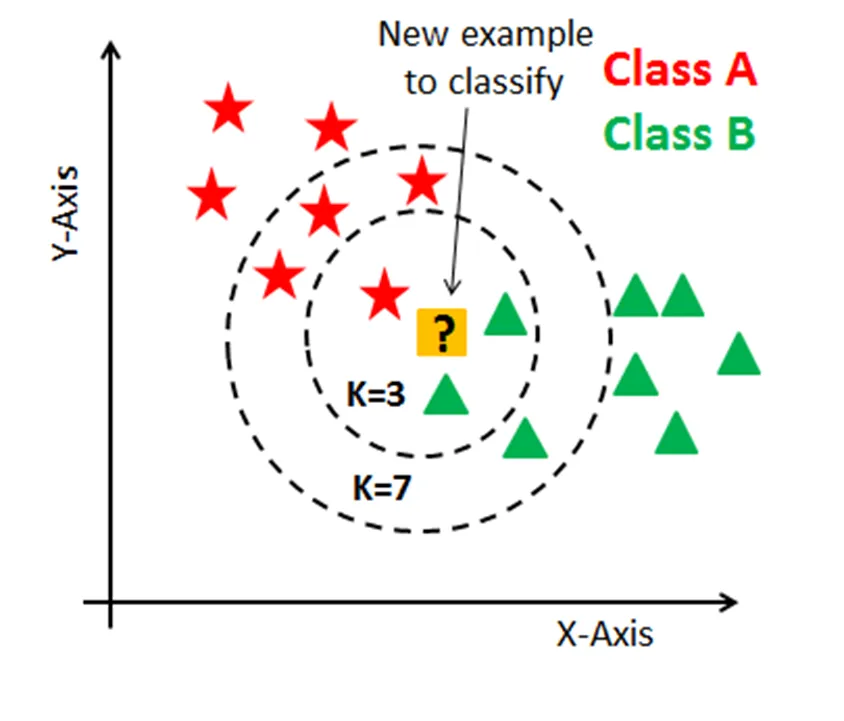
- k = 3이라면, 가장 근접한 3개의 데이터는 별 1개와 세모 2개이므로 세모로 예측
- k = 7이라면, 가장 근접한 7개의 데이터는 별 4개와 세모 3개이므로 별로 예측
그렇다면 k는 몇으로 정해야 하는가?
또 거리는 어떻게 측정해야 하는가?
하이퍼 파라미터
- 파라미터 parameter: 머신러닝 모델이 학습하는 과정해서 추정하는 내부 변수. 자동으로 결정되는 값.
ex) 선형회귀에서 가중치와 편향 - 하이퍼 파라미터 hyper parameter: 기계 학습 모델 훈련을 관리하는 외부 구성 변수. 모델 학습 과정이나 구조에 영향을 미침.
- 모델의 하이퍼 파라미터를 바꾸면서 좋은 평가지표가 나올 때까지 실험하고 원리를 밝혀내는 것이 바로 데이터사이언스의 기반이고 '과학'이라는 단어가 붙은 이유!
거리
-
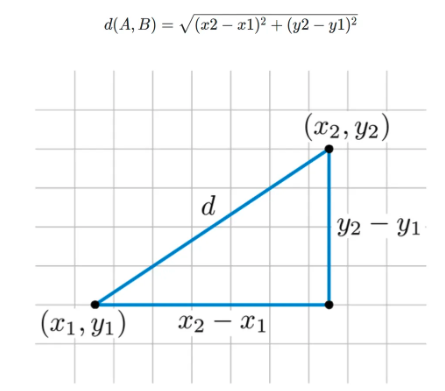
유클리드 거리
-
맨해튼 거리:
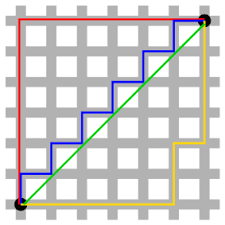
knn 알고리즘은 기본적으로 거리 기반이기 때문에 단위의 영향을 크게 받음. 따라서 표준화 필수
장점
- 이해하기 쉽고 직관적이다
- 모집단의 가정이나 형태를 고려하지 않아도 된다
- 회귀, 분류 모두 가능
단점
- 차원의 수가 많을수록 계산량이 많아진다
- 거리 기반이기 때문에 표준화가 필수적으로 필요
실습
sklearn.neighbors.KNeighborsClassifiersklearn.neighbors.KNeighborsRegressor
from sklearn.neighbors import KNeighborsClassifier
model_knn = KNeighborsClassifier()
model_knn.fit(X,y)
y_knn_pred = model_knn.predict(X)
get_score('knn',y,y_knn_pred)
# knn acc 스코어는: 0.826 f1_score는: 0.76
To Dare is To Do