[Paper Review] Low-Rank Adaptation of Large Language Models (LoRA)
1. Overall Summary of the whole content
LoRA는 사전학습된 모델의 가중치를 고정하고, 각 트랜스포머 레이어에 학습 가능한 low-rank 행렬을 추가하여 다운스트림 작업에 적응하도록 한다. 논문에서는 LLM을 효율적으로 fine-tuning하기 위한 새로운 방법인 LoRA를 제안한다.
2. Details
1) Low-Rank 행렬을 통한 효육적인 fine-tuning
- Pre-trained된 LLM의 모든 가중치를 업데이트하는 대신, 특정 레이어에서 가중치 행렬을 low-rank approximation 으로 분해하여 fine-tuning.
- 기존 모델과 유사하거나 더 나은 성능을 제공
- 학습해야 할 파라미터의 수를 많이 줄일 수 있음.
- 계산 효율성 증가
- 메모리 사용량 감소
2) GPT-3 175B 모델에서 LoRA의 성능
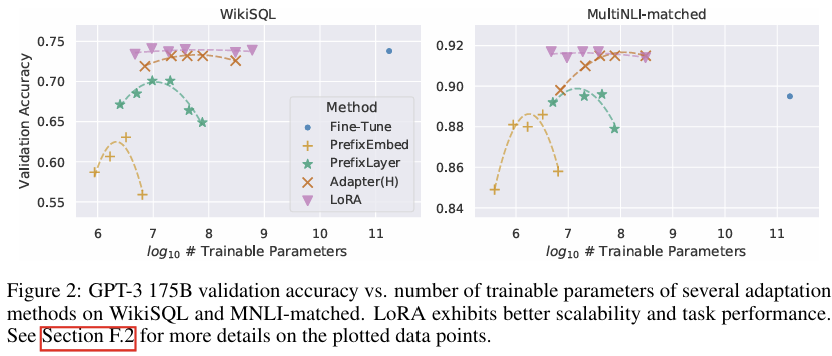
- GPT-3 175B 모델을 대상으로 실험한 결과, LoRA는 1/10,000 수준의 적은 파라미터로 학습하지만 전체 모델을 업데이트한 것과 비슷한 성능을 달성
- GPU 메모리 사용량을 기존보다 약 3배 감소시키면서 추론 속도는 유지
3) Pytorch 통합 패키지
- pre-trained된 가중치와 LoRA가 적용된 새로운 모델의 체크포인트 제공
- RoBERTa, DeBERTa, GPT-2 등 주요 사전 학습 모델에 LoRA를 통합하는 방법 설명
4) 기존의 어댑터 기반 접근 방식의 추론 지연 문제 해결
- LoRA는 low-rank 행렬을 활용하여 추론 지연 시간 없이 높은 효율성 달성
- 추론 할 때에도 원래의 가중치 W에 ΔW=A를 더하는 방식으로 동작하여 지연 시간이 발생하지 않음
- 학습 처리량 증가로 대규모 모델에서도 활용 가능
3. Conclusion
논문과 같은 접근방식을 통해 LLM의 미세 조정 시 발생하는 효율성 문제 및 자원 소모 등을 해결하는 데 큰 기여를 할 수 있다. 특히 LoRA는 메모리 제약이 있는 환경에서 유용하며, LLM을 더 적은 자원으로 더 많은 작업에 적용가능하게 한다. 따라서 추론, 학습, 메모리 사용의 전반적인 최적화를 달성하는 데 굉장히 효과적인 방법으로 평가받고 있다.
[Reviewed Paper]

🍮