Using raw string text for Machine Learning models
= "Natural Language Processing" : Supervised learning text tasks
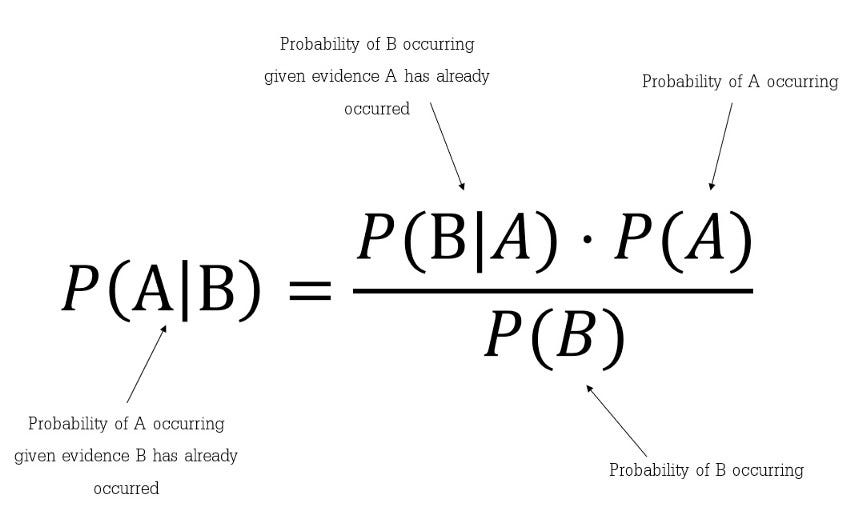
1. Bayes' Theorem
Naive Bayes -> Bayes' Theorem으로 supervised learning classify
2. NLP Classification - Joint probability
Bayes' Theorem을 Machine Learning Model로 conversion이 가능하다.
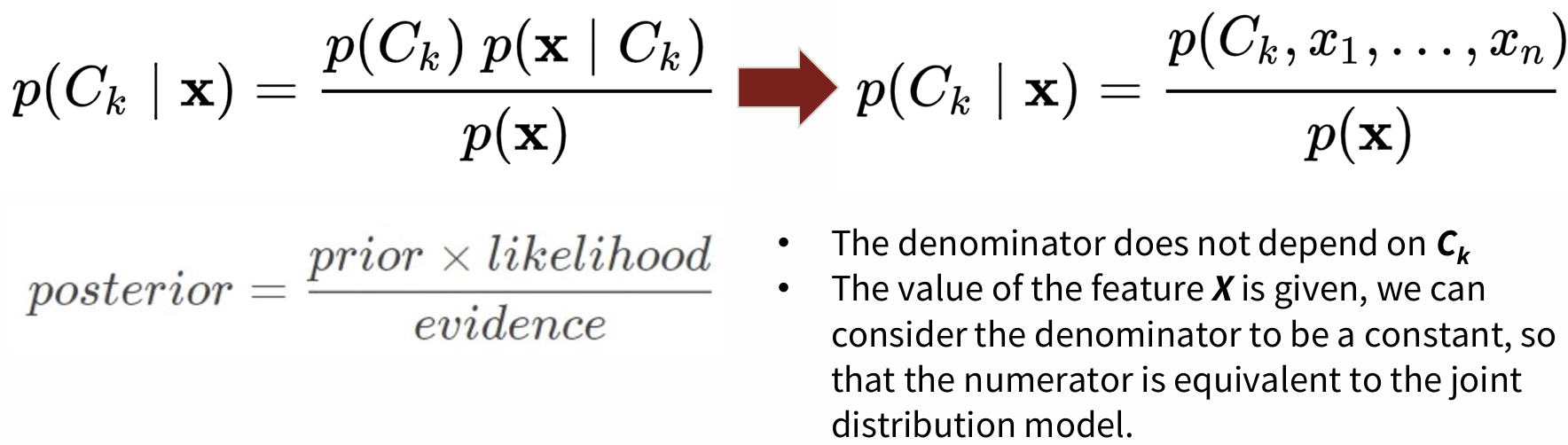
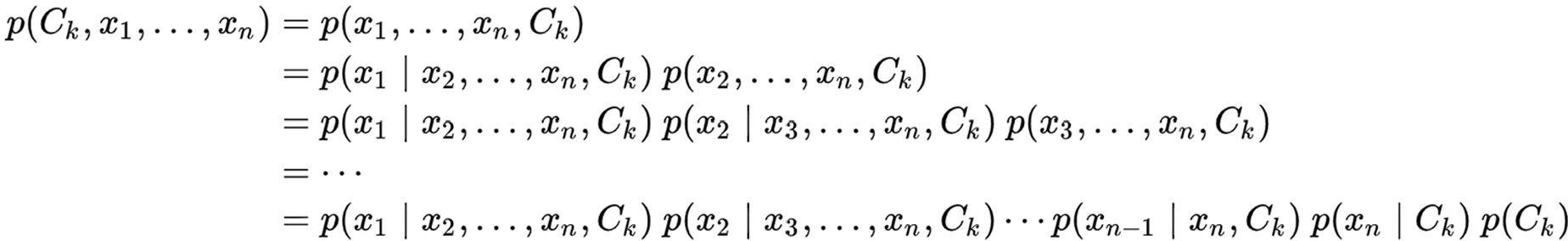
- 여기서 Numerator: Equal to joint probability model -> chain rule에 의해 product of conditional probabilities로 표현 가능 (물론, 모든 x feature가 independent하다는 가정하에)
따라서, 최종 joint model(the full Naive Bayes Model)은 아래와 같이 적을 수 있음. 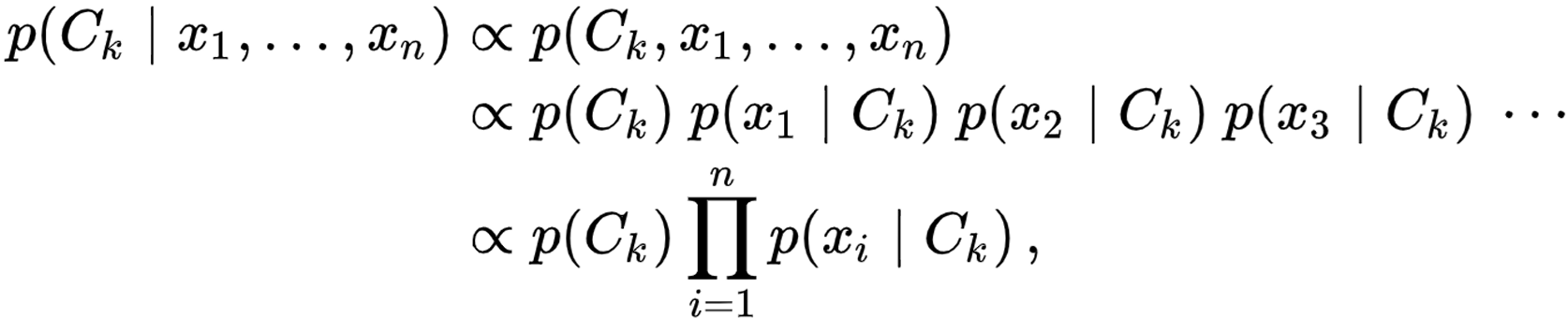
3. Variation of Naive Bayes Model
Naive Bayes Model의 variation으로는 Multinomial/Gaussian/Complement/Categorical/Bernoulli 등으로 다양함.
이 중 가장 잘 이용되는 모델은 Multinomial Naive Bayes Model.
4. Two main methods of extracting features from text data
1) Count Vectorization
-
각 document에 있는 가능한 모든 단어들을 겹치지 않게 펼치고 frequency count vector를 생성한다.
-
Document Term Matrix(DTM) 예시
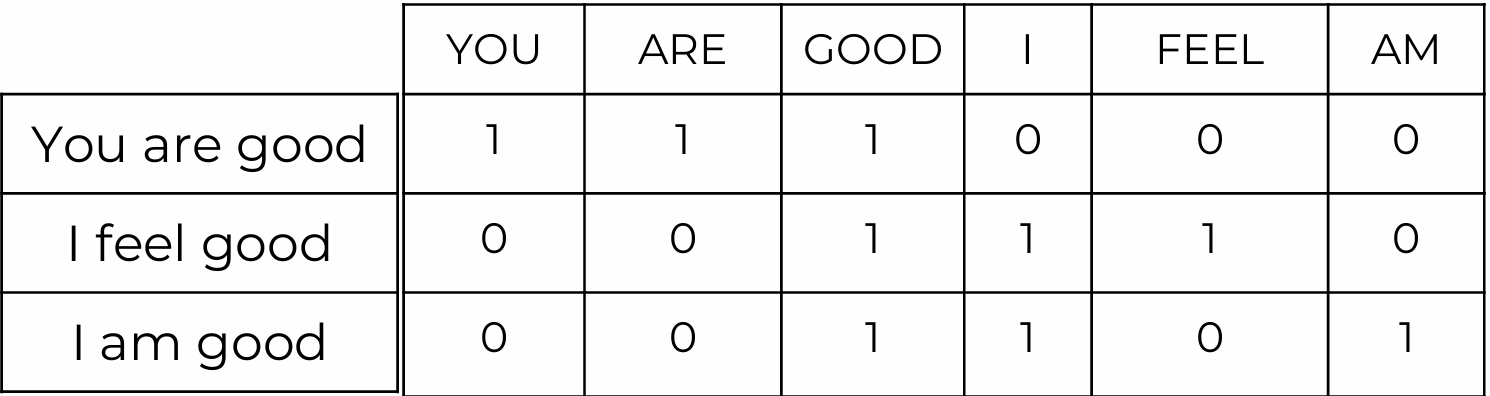
-
most value: 0 (sparse함) -> document가 클수록 더 sparse해짐
-
표에서 [단어들: feature, 빈도수 백터: strength of feature]
2) TF-IDF (Term Frequency-Inverse Document Frequency)
- DFT 채우는 대신 Document Frequency issue 해결: common할 stop words들 처리
- Inverse Document Frequency: non-stop words들이 common한 document 고려
희귀-> weight 증가시킴
흔함-> weight 감소시킴 (값이 0에 가까울수록 단어가 common)
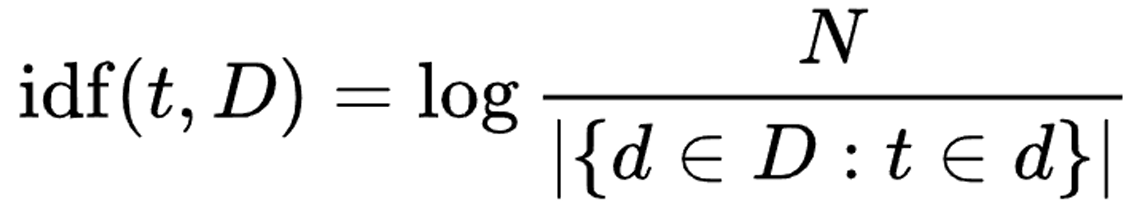
예를 들어, 100개 word에서 'run' 100개면 IDF는
-> log 1 = 0

🍮