[Paper Review] Training language models to follow instructions with human feedback (InstructGPT)
1. Overall Summary of the whole content
기존 GPT-3와 같은 LLM은 텍스트 생성 능력이 뛰어나지만, 사용자의 명령을 완벽하게 이해하고 따르는 능력에는 여전히 한계가 있으며, 사용자의 의도와 미묘하게 어긋나는 결과를 생성하는 경우가 많다. 해당 논문에서는 언어모델이 인간의 피드백을 잘 반영하여 작동하도록 강화학습을 사용하여 GPT-3모델을 개선한 InstructGPT를 다룬다. 또, LLM이 명령을 더 잘 이해하고 수행하도록하며, 모델의 성능과 안전성 및 신뢰성을 높이는 방법론을 제안한다.
2. Details
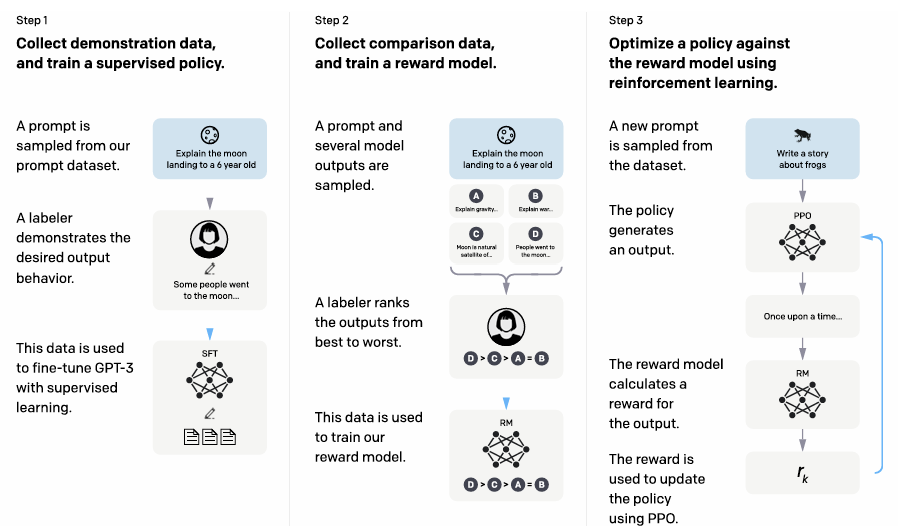
(1) RLHF(Reinforcement Learning from Human Feedback) - SFT, RM, PPO
논문에서는 RLHF를 통해 InstructGPT를 훈련시키는 방법론을 제안한다. 이는 이용자의 선호도를 모델 훈련에 반영하는 과정으로, 이전의 지도 학습 기반 모델보다 사용자 친화적인 출력 생성이 가능하여 여러 분야에서 개선된 사용자 경험을 제공한다.
<RLHF의 주요 3단계>
- Supervised Fine-Tuning(SFT)
- prompt(명령어)와 이에 대한 적절한 응답을 수집하여 모델이 초기 학습 방향을 설정하게 함.
- labelers(인간 평가자)가 작성한 적절한 출력 예시들을 기반으로 기존 GPT-3 모델을 초기 fine-tuning함.
- Reward Model Training
- 인간 평가자가 여러가지 출력 결과들을 비교하여 '선호도'를 표기한 데이터를 수집.
- 수집한 데이터를 기반으로 보상 함수를 학습(선호도를 잘 반영하는 출력 -> 높은 점수를 받도록 설계).
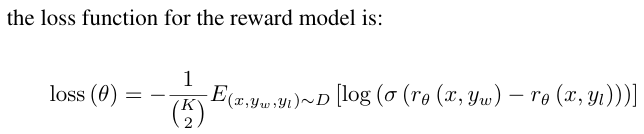
- Proximal Policy Optimization(PPO)
- 학습된 RM을 기반으로 GPT-3을 반복적으로 fine-tuning.
- 이 알고리즘 사용으로 RM의 점수를 극대화하도록 정책 최적화.

<인간 피드백 데이터의 한계>
- 평가자 간 의견 불일치로 reward model 학습 시 잡음이 생길 수 있음.
- 평가자 개인의 선호도나 편향이 데이터에 포함될 가능성이 존재.
- 고품질 피드백 데이터를 얻으려면 많은 시간과 비용이 소요됨.
(2) InstructGPT - 성능 개선
 기존의 GPT-3모델과 비교했을 때, InstructGPT는 사용자 선호도 및 명령 수행 정확도등의 지표들에서 큰 개선을 보였다. 특히 훈련 과정에서 사용자 피드백이 잘못된 출력을 보정하도록 유도하여 편향 및 오류를 감소시켰으며, 소규모의 피드백 데이터만으로도 모델의 성능을 크게 향상시켜 데이터의 효율성을 증폭시켰다.
기존의 GPT-3모델과 비교했을 때, InstructGPT는 사용자 선호도 및 명령 수행 정확도등의 지표들에서 큰 개선을 보였다. 특히 훈련 과정에서 사용자 피드백이 잘못된 출력을 보정하도록 유도하여 편향 및 오류를 감소시켰으며, 소규모의 피드백 데이터만으로도 모델의 성능을 크게 향상시켜 데이터의 효율성을 증폭시켰다.
<주요한 결과들을 정리해보면...>
- 동일한 파라미터 크기를 기준으로 비교했을 때, 더 뛰어난 명확성과 일관성.
- 핵심 내용 위주의 응답(불필요/과도한 정보 줄임).
- 입력 명령에 적합한 응답 비율이 2배 이상 향상.
(3) 소규모 모델의 효율적 활용
InstructGPT는 기존의 GPT-3과 같은 175B 파라미터 모델뿐만 아니라, 소규모 파라미터 모델에서도 성능 향상을 보여준다. RLHF를 적용한 소규모 모델은 동일 크기의 기존 GPT-3모델보다 높은 사용자 선호도를 보이는데, 이는 그저 모델 크기를 늘리는 것만으로는 해결되지 않는 품질 문제를 RLHF가 효과적으로 보완하였음을 의미한다.
<결과적 효율성>
- 중소형 규모의 하드웨어에서도 고품질 언어 모델을 배포할 수 있는 가능성을 제시
- 모델 비용의 효율성 및 소규모 모델에서도 사용 가능한 응용 사례 증가
<의의>
- 자원이 제한된 환경에서도 사용자(인간) 친화적인 모델 활용 가능성을 열어줌.
- 소규모 모델의 실용적 사용 사례를 증가시켜 대규모 파라미터 모델의 독점적인 사용을 완화 -> 다양한 규모의 AI 모델 개발에 기여.
(4) 편향 및 안전성 문제
InstructGPT도 여전히 완벽하지는 못하며, <인간 피드백 데이터의 한계>에서 언급한 바와 같이, 훈련 데이터 및 평가자의 개인적인 편견을 반영할 위험이 있고 공격적인 언어를 생성할 수도 있다는 등의 몇몇 문제들이 남아있다. 이에 대비해 평가자들의 다양성을 높이고, 여러 관점을 반영하는 피드백 시스템 도입이 필요하다. 또, 유해한 응답이나 부정적인 발언에 낮은 점수를 주도록 학습시키는 등의 보상 구조 개선도 필요한 상황으로, 이에 대한 연구도 진행중이다.
(5) 이론과 구현 현실 사이의 차이
- PPO 알고리즘을 활용하여 모델을 강화학습할 때 reward model의 점수를 극대화하는 방향으로 최적화를 수행한다고 하지만, PPO 알고리즘의 효율성은 모델의 복잡도나 크기에 따라 달라질 수 있다.
- 평가자 간의 의견 불일치나 데이터의 노이즈가 생길 수 있으며, 이는 reward model의 학습에 부정적인 영향을 미쳐서 최적화가 불안정해지거나 모델이 잘못 학습할 수 있다.
<PPO 알고리즘의 적용 코드 예시>
import gym
from stable_baselines3 import PPO
# OpenAI Gym 환경 불러오기
env = gym.make('CartPole-v1')
# PPO 모델 학습
model = PPO('MlpPolicy', env, verbose=1)
model.learn(total_timesteps=10000)
# 학습된 모델 저장
model.save("ppo_cartpole")
# 모델 테스트
obs = env.reset()
for _ in range(1000):
action, _states = model.predict(obs, deterministic=True)
obs, reward, done, info = env.step(action)
if done:
obs = env.reset()
3. Conclusion
논문의 InstructGPT는 지도학습, 보상 모델 학습, 그리고 강화학습을 단계적으로 실행하여 기존 GPT-3 모델보다 사용자 선호도에 더 부합한 결과를 출력하는 것에 성공했다. 제안된 방법론은 언어모델의 신뢰성을 향상시킬 뿐만 아니라, 현실에서의 적용 가능성도 실질적으로 입증했다.
향후에는 데이터의 편향 문제를 완화하고, 다양한 배경을 포괄할 수 있는 확장된 피드백 시스템 도입이 필요하다. 이 논문에서 진행된 연구는 모델의 성능을 높이는 것에 그치지 않고, AI 시스템이 인간과 더욱 조화롭게 협력할 수 있는 방향성까지 나아가 제시했다는 점에서 큰 의의를 지닌다.
[Reviewed Paper]
