
1. Crawling
- 크롤러: 크롤링 과정을 수행하는 소프트웨어 -> data mining, AI 언어 모델, 빅데이터 분석 등 다양한 IT 영역에서 필수적인 역할 수행
web crawling -> 웹페이지를 그대로 가져와서 그 안에서 데이터를 추출하는 과정
-
주된 목적: 정보 수집 및 분류를 위해 다양한 웹 페이지를 방문하여 데이터를 모으고 이를 체계적으로 분류하고자 함.
-
Ex) ChatGPT -> 웹크롤링 기반으로 학습할 데이터 가져옴.
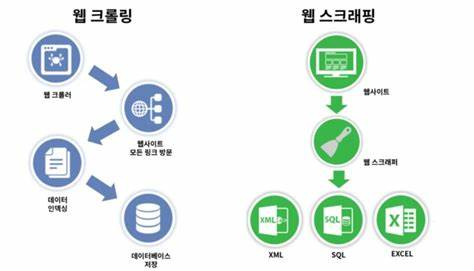
- 웹 크롤링 vs 웹 스크래핑
- 웹 크롤링(web-crawling): 정해진 링크를 따라 연결된 페이지를 가져오는 것 -> 자동화 봇인 웹 크롤러가 정해진 규칙에 따라 웹페이지들을 브라우징하는 행위
- 웹 스크래핑(web-scraping): 웹 크롤러가 수집하는 페이지가 있을 때 추출하고자 하는 위치의 데이터를 가져오는 것 -> 웹 사이트의 데이터를 수집하는 수집하는 모든 작업
2. Web-Crawling Method - Python
(1) requests, beautifulsoup 라이브러리 다운로드
- 명령 프롬프트 CMD창에서 명령어 작성하여 다운로드
pip install requests
pip install beautifulsoup4
- 각 라이브러리의 역할:
- requests: 웹 서버에 정보를 요청하고 그 결과를 가져옴 -> 원하는 웹 페이지에 HTTP 요청을 보내고, 그 응답을 쉽게 처리할 수 있도록 함.
- beautifulsoup: 가져온 HTML 문서에서 필요한 정보를 추출 -> HTML을 파싱하고 원하는 태그, 클래스, 아이디 등을 기준으로 원하는 정보를 쉽게 찾을 수 있음.
(2) 웹 크롤링 순서
-
타깃 URL 선택 및 설정
크롤링할 웹사이트의 타깃 URL을 선정하고, 첫 번째 방문할 페이지의 URL을 설정 -
웹 페이지 다운로드
- 설정된 URL로 HTTP 요청을 보내고, 응답으로 받은 HTML 데이터를 다운로드
- 일반적으로 Python에서는 requests 라이브러리를 사용
- HTML 파싱
- 다운로드한 HTML 파일에서 원하는 데이터를 추출하기 위해 파싱 작업을 진행 (웹 파싱: 웹 상의 자연어, 컴퓨터 언어 등 일련의 문자열들을 분석하는 과정)
- 주로 BeautifulSoup 같은 라이브러리를 사용하여 DOM 구조를 분석
- 데이터 추출 및 링크 수집
- HTML 파싱 과정에서 필요한 데이터를 추출
- 동시에 페이지 내에 포함된 다른 링크(URL)를 수집하여 다음에 방문할 대상 설정도 가능
- 데이터 저장 및 활용
추출한 데이터를 원하는 형식(CSV, JSON 등)으로 저장하거나, 데이터 분석, 모델 학습 등 다양한 목적으로 활용
3. 웹 크롤링 예시
-melon top100 정보 가져오기-
<특정 URL로 부터 웹페이지에 있는 텍스트(멜론의 top100 차트 정보)를 가져오기>
url = "https://www.melon.com/chart/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(url, headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')위 코드에서...
- get 함수: 지정된 URL로 HTTP GET 요청을 보내는 함수 -> 지정된 URL에서 정보를 가져오겠다고 웹페이지에 선언하는 것
- data의 text 인자에는 지정된 URL의 웹페이지의 모든 텍스트가 들어가있음 -> 다음 행의 BeautifulSoup에서 HTML parser를 이용하여 내용들을 잘라주는 역할을 수행
<BeautifulSoup의 HTML parser을 이용하여 텍스트를 parsing>
trs = soup.select('table > tbody > tr')
for tr in trs[:1]:
print(tr.select_one('.rank01 > span > a').text)
print(tr.select_one('.rank02 > a').text)
print(tr.select_one('.rank03 > a').text)
print(tr.select_one('img')['src'])위 코드에서...
- select, select_one 함수: CSS 선택자를 사용하여 HTML 문서에서 원하는 요소를 찾는 데 사용
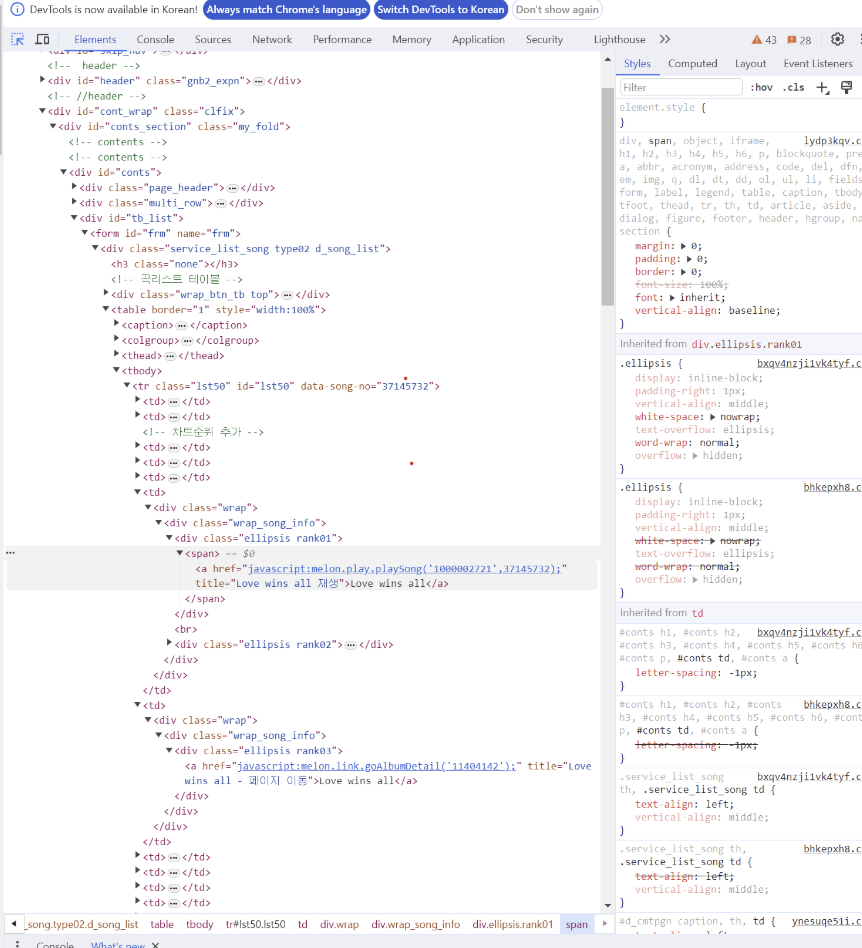
- "F12"키를 눌러 개발자 도구를 사용하여 좌측 상단의 마우스 모양을 클릭하고 웹페이지의 요소에 가져가면 원하는 요소가 담겨있는 코드를 쉽게 찾을 수 있음('table' 태그 안, 'tbody' 태그 안, 'tr'태그에 원하는 정보들이 있음을 알 수 있었음).
- 태그들을 타고 들어가면, 노래 제목은 'rank01'의 'span' 태그의 'a' 태그에 있고, 가수는 'rank02' 태그의 'a' 태그에 있고, 앨범 정보는 'rank03' 태그의 'a'태그에 있고, 앨범 커버 이미지의 정보는 'img'의 'src'인자에 있음을 알 수 있음.

🍮