[Paper Review] Classifying ECG abnormalities using 1D Convolutional Neural Networks(1D-CNN) with Leaky-ReLU function
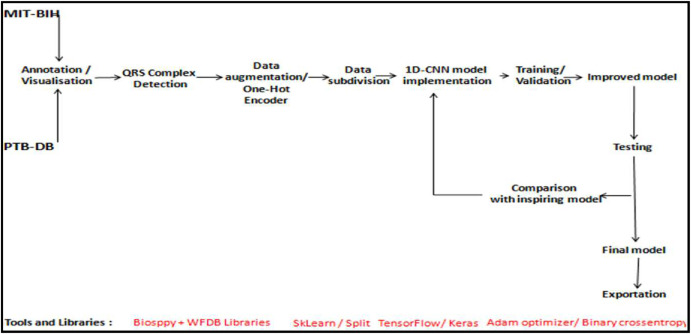
1. Summary of this paper
The steps of preprocessing(followed by QRS complex detection, data augmentation, data subdivision) and modeling have a significant impact on the overall performance of the classification model. Also the choice of the activation function (Leaky-ReLU in this paper) and the number&type of layers influences the result.
High-quality classification leads to detect ECG abnormalities with a very high precision, recall and accuracy remaining the same on the test dataset.
All of these processes and their accompanying consequences show that it has the potential to handle more cardiac abnormalities (because features can be learned automatically based on the provided dataset).
The comprehensive structure of the implementation process is outlined below. (I've encapsulated the particulars of certain processes delineated in the paper.)
2. Details
2-1. Used database
(1) MIT-BIH
- Contains..
: recordings of the two-channel ambulatory ECG signals from 47 people - Represents the classes of..
: normal ECG, premature contractions(arterial & ventricular), bundle branch block(right and left), signal at an accelerated rate
(2) PTB-DB
- Contains..
: archives of ECG signals from 290 mixed population(age-17~87, rate of 1-5 recordings per person) - Can be summarized into two main classes of..
: healthy people & people with a variety of coronary heart disease
2-2. QRS complex detection
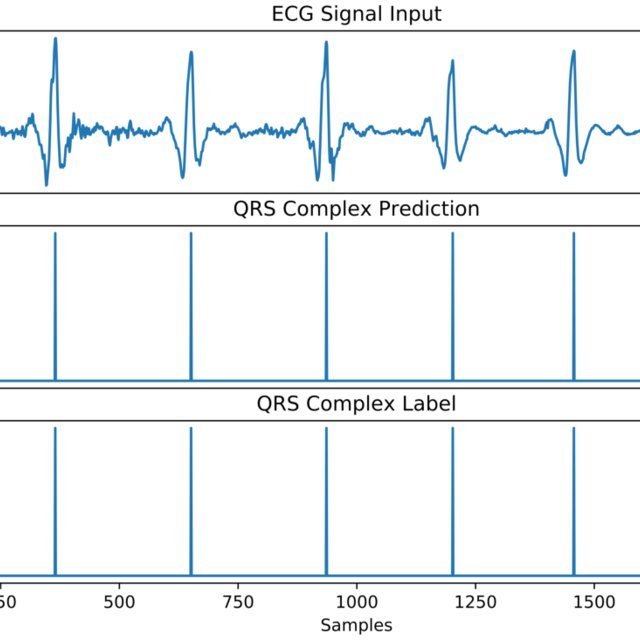
- Necessity
: The heterogenity of database needs to be augmented('one-hot-encoder: location of "1" differentiating each vector from the others' method is used for encoding in data augmentation step in this paper) and preprocessed. The data augmentation step regularizes the amount of data in each class to be equal(<- this step only possible after detecting the QRS complex in the ECG signals). - Denotes..
: either the peak or the highest point of the signal standing out as a crucial feature of the ECG
2-3. Used activation function
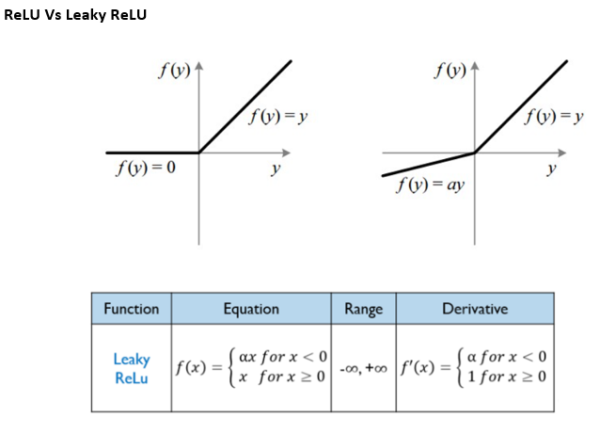
Leaky-ReLU function is used in this paper considering that it assigns a variant to negative values to reserve the neurons and keeps the valuable data in the end.
However, for the smaller PTB-DB dataset, the activation function was changed to the standard "ReLU" instead of "Leaky ReLU" to prevent the dying ReLU issue. The model was trained for 30 epochs, demonstrating strong learning and generalization abilities across various cardiac datasets.
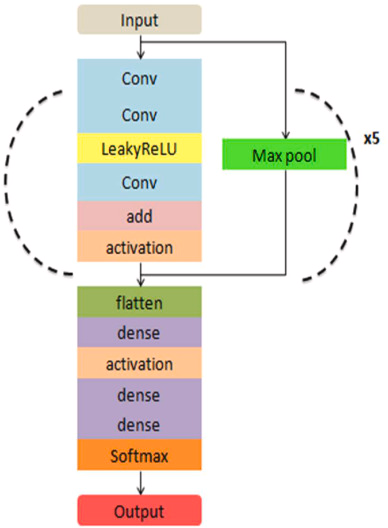 Outlined above is the architecture of the 1D-CNN model proposed within this paper.
Outlined above is the architecture of the 1D-CNN model proposed within this paper.
3. Conclusion
Various factors, including data quality, preprocessing and regularization steps, choice of activation function, and the number and type of layers, are crucial in enhancing the overall performance of the classification model. Moreover, this approach has led to algorithms that achieve very high precision, recall, and accuracy. With its capability for automatic learning, this model shows promise for further development to address more heart abnormalities in the future.
[Link to the paper reviewed]
https://www.sciencedirect.com/science/article/pii/S2666521222000333?via%3Dihub#abs0015
