[Paper Review📚] <Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network>
Hyebbb Paper Review

CVPR 2020에 accept된 < Blindly Assess Image Quality in the Wild Guided by A Self-Adaptive Hyper Network >를 읽고 정리한 내용이다.
1. Introduction
Image quality assessment를 줄여서 IQA라고 한다. 이 IQA의 목표는 computer가 사람처럼 이미지의 quality를 평가할 수 있도록 하는 것.
지금까지 다양한 IQA방법들이 제안되어 왔는데, 원본 image에 다양한 distortions들을 인위적(synthetic)으로 생성해낸 이미지들에 대해서는 잘 평가하는데 성공을 했음에도 불구하고, 인위적으로 만들어낸 distortion이 아닌 실제(authentic) 진짜 distortion을 담고 있는 이미지에 대해서는 계속 도전 과제로 남아있다.
Authentic distorted image에 대한 IQA의 문제점을 세가지 측면에서 보면,
-
1) authentic distorted image에 대해서는 reference, 즉 원본 이미지가 존재하지 않기 때문에 다양한 IQA들(FR-IQA, RR-IQA, BIQA 등) 중에서도 가장 어렵다고 할 수 있는 BIQA(No-reference Image Quality Assessment) 하나로 제한된다.
-
2) 인위적으로 만들어낸 distortion과 달리 실제 distortion들은 global하게 uniform한 distortion뿐만 아니라 local하게 non-uniform한 distortion도 담고 있기 때문에 훨씬 복잡한 distortion을 잡아내야 한다는 어려움이 있다.
-
3) database의 측면으로 봤을 때, synthetic IQA database의 경우에는 약 30개정도의 content에서 여러 noise들을 합성해 놓은 이미지들인데, authentic IQA database들은 약 만장이 넘는 이미지들이 모두 다른 content들을 포함하고 있기 때문에 이 content의 변화들이 확실히 IQA의 generalization에 큰 문제가 된다.
이런 authentic distortion의 다양성 & content variation을 고려하는 authentic distorted image에 대한 IQA로 여러 방법들이 시도되었는데,
그 중에서 ImageNet과 같은 classification database에 실제 distortion들이 존재한다고 가정한 채, 그 classification task에 대해 pretrain된 deep learning model을 real world distrion을 예측하는데 적용하는 방법으로 시도되었다. (ex. DBCNN의 tailored VGG-16부분)
이 논문에서는, 이 시도에는 아직 몇몇 결점이 존재한다고 말한다.
-
1) 이 시도로는 classification을 위한 global한 feature들만이 학습이 되기 때문에 Authentic IQA는 local한 부분에 존재하는 다양한 distortion들도 인지하지 못하고 무시해버리는 점.
-
2) image content를 인식한 후 image quality를 판단하는 사람들의 image quality 인식 방법과 달리, image content와 quality를 동시에 학습하여 올바른 판단을 하지 못하는 문제점.
ex.

(출처:https://www.youtube.com/watch?v=qksOm2bHRyg) (left): 사람들은 하늘위의 구름사진을 보고 "구름이네~"라고 대상 content를 파악한 후 high quality라고 판단을 내리지만, computer는 구름의 넓게 펼쳐져 있는 형태 때문에 "blurry하다"고 판단한 후 low quality로 판단을 내린다.
(right): 사람들은 "청바지네~"라고 content를 파악하고 high quality라고 판단할 수 있지만, computer는 청바지라는 content를 고려하지 않은 채 이 질감을 보고 "noisy하다"고 판단하여 poor quality로 판단을 내린다.
그래서 이 논문에서는 이 두가지 문제점을 고려하여 distortion의 다양성을 고려하여 multi-scale로 local feature들을 추출해내는 1) local distortion aware module과, 넓은 content variation을 커버하기 위해 quality prediction network의 weight들을 생성하는 2) hyper network 구조를 제안한다.
2. Proposed Method
전체적인 구조를 보면 세가지 부분으로 이루어져 있다.
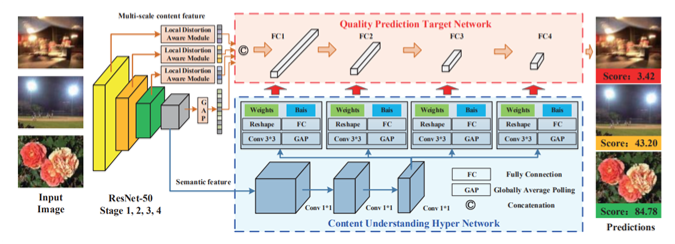
- semantic feature들을 추출하는 backbone network
- image quality를 예측하는 target network
- target network를 위한 self-adaptive parameter들을 생성하는 hyper network
즉, hyper network는 인식되는 content에 따라 quality를 인식하는 것에 대한 rule을 순응적으로 학습할 수 있게 되고, 만들어진 rule을 따라 target network가 최종 quality score을 예측을 하게 되는 것이다!
이 모델은 image content에 따라 image quality를 순응적으로, 적응하여 예측하는 Self-Adaptive IQA model인데, 이를 식으로 살펴보면 다음과 같다.

- (Tranditional)
기존의 deep learning base의 quality prediction model은 input image x와 weight parameter가 network model에 들어가면 quality score q가 뽑히는 형태이다. 이 때 quality score을 뽑아내는 test 과정에서 weight parameter 세타가 고정되어 있기 때문에 같은 종류의 quality feature들이 추출되었다고 prediction model을 생각할 수 밖에 없게 된다. (위의 하늘 위 구름, 청바지를 예시로 든 문제점이 발생함) - (Proposed)
제안된 모델은 image의 content를 먼저 인식한 후에 image quality를 예측하는 사람들의 평가 방법을 모방하여, network parameter theta가 input image에 따라 달라지도록 한다. 이 때 많은 content들에 대해 network들을 모두 학습하는건 비효율적이기 때문에 단순화하기 위해 hyper network을 사용한다. input image x로부터 추출한 semantic feature인 S(x)가 hypernetwork의 input으로 들어가게 되고, hyper network가 image quality를 판단하는 rule에 대한 mapping을 학습하면, 학습된 rule을 기반으로 target network가 self-adaptive quality feature을 추출해 낸다. (사실 마지막 target network를 거치는 부분에서는 parameter 수를 줄이고 간소화 하기 위해 multi-scale feature들이 합쳐진 vx가 input으로 들어간다)
모델을 하나하나씩 살펴보면,
Semantic Feature Extraction Network
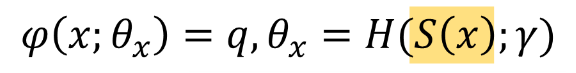
맨 처음 부분인 semantic feature extraction network부분은 ResNet 모델을 사용하고 있고, ImageNet으로 pretrain된 모델에서 뒤의 두 레이어를 제거한 모델을 사용하고 있다.
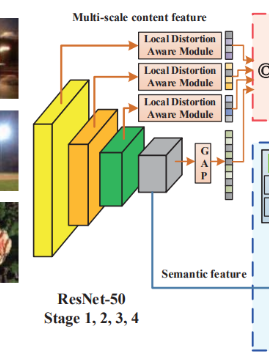
이 모델을 거치고 맨 마지막에 나온 S(x)는 hyper network의 input으로 들어가게 되고, 또 총 3개의 레이어에서 중간중간에 feature들을 추출해 내는데 이 추출해 낸 것들을 concat해서 Sms(x)를 만들어내고 이는 target network의 input인 Vx가 된다. 중간중간 feature들을 뽑아 합치는 것을 input으로 넣음으로써 local distortion들도 잡아낼 수 있도록 했다고 한다.
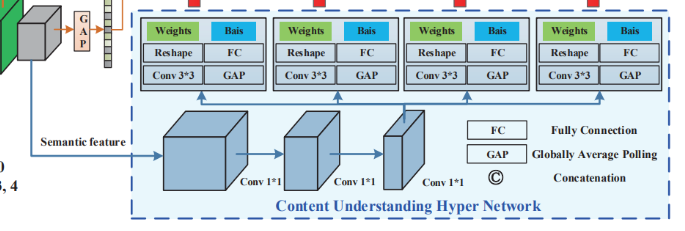
Hyper Network
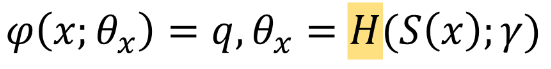
다음 단계 Hyper network는, 세개의 convolutionlayer들로 이루어져 , 이 레이어를 거치게 되면 최종적으로 target network에서의 각각의 fully-connexcted layer의 wieght들을 만들어 내게 된다. 이 때 추출된 feature들을 reshape해서 weight들을 만들어내고, (여기서 output channel과 fully connected layer들은 target network의 레이어와 dimension을 고려해서 결정해야 함). 그렇게 생성된 weight들은 결국 image quality를 인식하는 rule로 작용하게 된다.
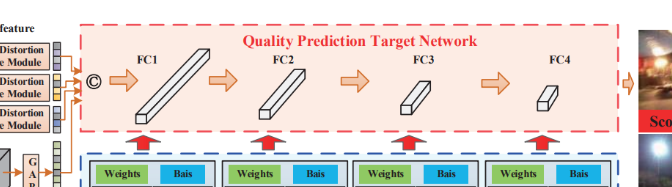
Target Network
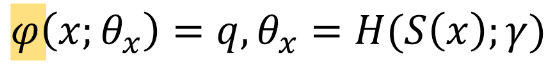
마지막으로 target network는 4개의 fully connected layer로 간단하게 이루어져 있고, 앞서 첫번째 단계에서 뽑혀 나온 벡터가 input으로 들어와 각각의 layer들에 앞서 생성한 weight들과 함께 통과하여 최종적인 quality score가 뽑히게 된다.
3. Experiment
이 논문에서는 dataset으로 authentically distorted image database 세가지를 사용하였고, 합성된 distortion image들에 대해서도 성능을 확인하기 위해 LIVE와 CSIQ dataset도 평가를 위해 사용하였다.
- Three authentically distorted image databases
-> LIVE Challenge(1162 images), KonIQ-10k(10073 images), BID(blur 586 images) - Synthetic image databases
-> LIVE(779 images), CSIQ(866 images)
이미지는 random sampling 후 224 224로 자른 후 flipping을 하여 data augmentation을 하였다.
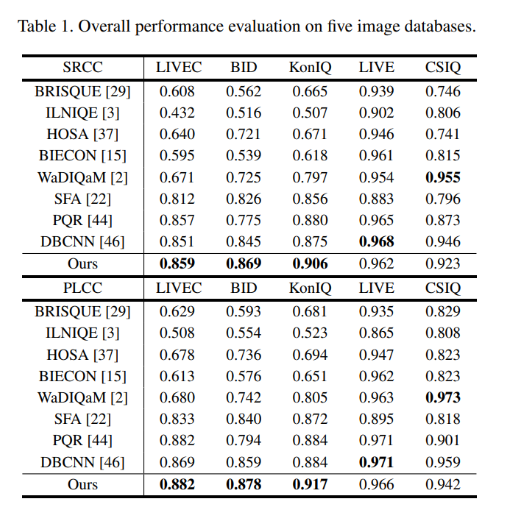
결과를 보면, 기존의 Blind IQA보다 authentic distortion database에 대해서는 SOTA를 달성하였고, 합성 distortion database에 대해서도 꽤 높은 성능을 보인 것을 확인할 수 있다.
4. Visualization of Self-Adaptive Weights

Hyper network에서 content에 따라 생성되는 weight들이 어떤 식으로 잘 생성이 되었는지 PCA transform하여 시각화 한 결과이다. content들에 따라 확실히 같은 content에 대해서는 비슷한 weight을 다른 content에 대해서는 다른 weight들을 생성해냈음을 확인할 수 있다.
논문 정리를 마치며, 다시 짚어보면
- Authentic distortion의 local한 다양한 feature들도 추출하기 위한 local distortion aware module과,
- authentic distorted database 속 content의 다양성을 고려하여 quality prediction network의 weight들을 생성하는 hyper network 구조를 포함하여
총 세 단계로 구성된 IQA deep learning model을 이 논문에서는 제시하였다.
authentic과 synthetic를 고려하여 두 부분으로 나누어 pretrain후 feature을 뽑아 bilinear pooling으로 score을 뽑아내는 DBCNN 모델과 모델 구성의 기반? 느낌은 되게 비슷하다고 느껴지지만, DBCNN의 성능을 뛰어넘었다는 점에서 굉장히 주목할만한 모델인 듯하다.
음,,그리고 처음 볼 때는 모델이 생각보다 굉장히 복잡해 보였지만, code 상으로는 되게 간단하게 구현되어 있는 것 같다!
끝`(>﹏<)′
