[Paper Review📚] <The Unreasonable Effectiveness of Deep Features as a Perceptual Metric>
Hyebbb Paper Review

CVPR 2018에 accept된 < The Unreasonable Effectiveness of Deep Features as a Perceptual Metric > 를 읽고 정리한 내용이다.
1. Motivation
다양한 분야에서 어떤 것들을 비교하기 위해 여러 distance들이 사용되는 것은 가장 기본적인 작업이지만, computer vision분야에서 이 작업은 계속해서 wide-open problem으로 남아있다. 시각적인 패턴을 비교하는 task는 시각적 패턴이 매우 고차원적이고, 때론 주관적이며, human visual perception을 모방하는 것을 목표로 하기 때문이다.
우리가 잘 알고있는 Euclidean distance나 PSNR과 같은 measure들은 pixel-wise independence를 가정하기 때문에 이미지와 같은 구조화된 output들을 평가하기에 충분하지 않다. (예를 들어, blurring은 매우 큰 perceptual 변화를 일으키지만 값의 변화는 매우 작다.)
결국, 이 task에서 가장 중요한 것은 인간의 판단과 일치하게 두 이미지가 얼마나 유사한지 측정하는 "perceptual distance"이고 SSIM 등 많은 perceptually motivated distance metric들이 제안되었다.
하지만, 인간의 유사성 판단의
1) depend high-order image structure
2) context-dependent (ex. 빨간 원이 빨간 사각형과 비슷한지, 파란 원과 비슷한지 판단할 때 )
3) not actually constitute a distance metric 한
세가지 특징으로 인해 perceptual metric을 구성하는 건 어려운 문제였다. (많은 distortion type들을 포함하는 large-scale dataset으로 학습했을 때에도 generalization에 실패했다)
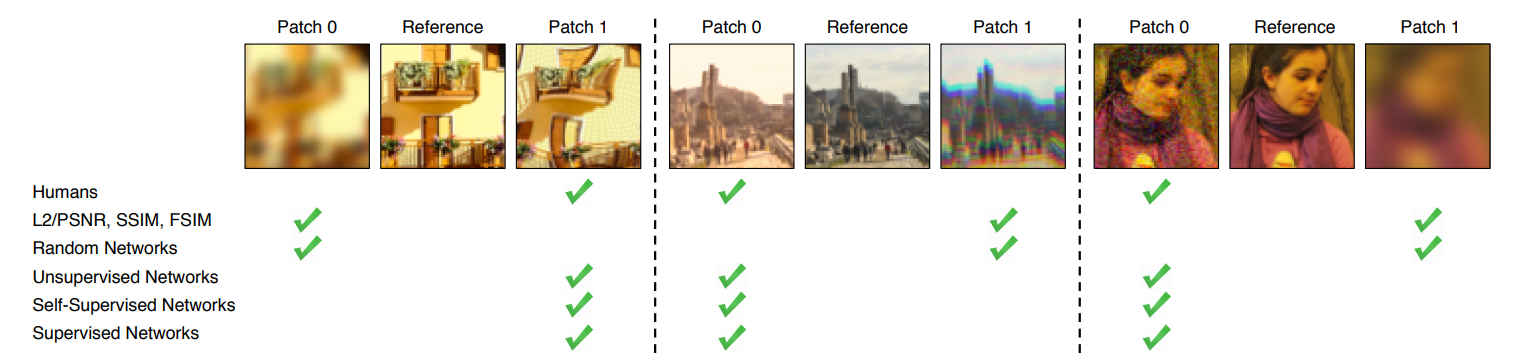 |
|---|
| 가운데 원본과 더 비슷한 이미지를 찾는 문제에서 L2/PSNR, SSIM, FSIM과 같은 기존 metric은 잘못된 판단(Human의 판단과 다른)을 하고 있다. |
그래서 perceptual similarity를 많은 데이터셋들로 직접 training하지 않고 그 notion을 학습할 수 있는 방법으로 VGG feature space의 distance가 등장하였다. 한 학회에서, high-level image classification task로 학습된 deep convolutional network의 internal activation이 다양한 task들을 위한 representational space로 매우 유용하다는 것이 밝혀졌고, 다양한 task(ex. neural style transfer, image superresolution 등)task에서 VGG로 뽑아낸 feature space의 distance를 "perceptual loss"로 측정하여 사용하고 있다. (image regression task를 위해 image classification task로 학습된 network의 feature를 사용한다.)
이 논문에서는, 이 "perceptual loss"가 실제로 얼마나 human visual perception과 상응할지, 어떻게 고전적인 perceptual image evaluation metric들과 비교할지, 네트워크 아키텍쳐가 중요한지, ImageNet classification task로 학습되어야 하는지, 다른 task들에 잘 작동하는지 등의 여러 의문점들을 평가하고 그에 대답들을 제시하고 있다.
이 논문의 Contribution은 다음과 같다.
- 484k human judgments를 포함하는 large-scale, highly varied, perceptual similarity dataset인 새로운 데이터셋 소개
- supervised, self-supervised, unsupervised 목표로 학습된 deep feature들이 low-level perceptual similarity를 잘 모델링한다. 이는 이전의 널리 사용된 metric들을 뛰어넘는 결과를 보였다.
- network architecture만으로는 성능을 설명하지 못한다.
- (자신들이 제시한 data로) pre-trained된 네트워크로부터 feature response를 "calibrating"하여 성능을 향상시킬 수 있다.
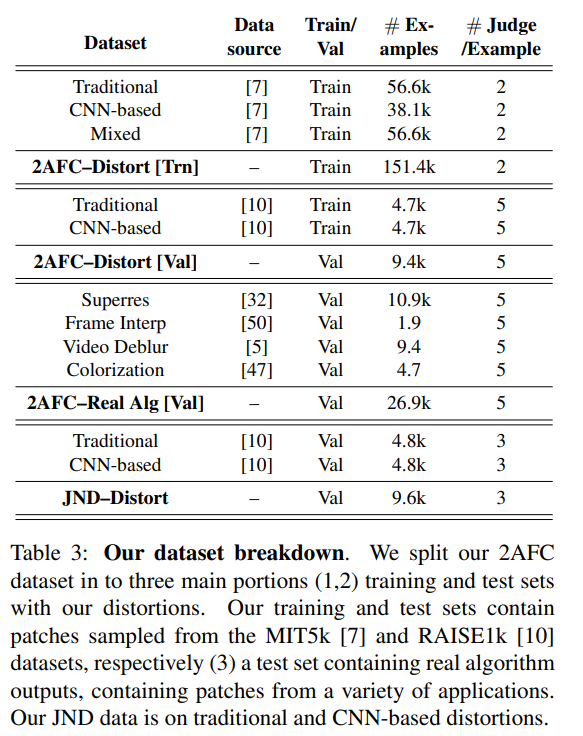
2. Berkeley-Adobe Perceptual Patch Similarity(BAPPS) Dataset
유명한 LIVE, TID2008, CSIQ, TID2013 등의 image quality assessment를 위한 데이터셋들은 각각의 image의 "quality"에 초점이 맞춰져 있다.
하지만, 이 논문에서 제시하는 데이터셋은 quality assessment보다 "perceptual similarity"에 초점을 맞추었고, 기존의 데이터셋들보다 새로운 distortion들과 deep network based distortion들을 포함하고 있다. 그리고 full image가 아닌 patch들로 구성되어 있다.
Distortions
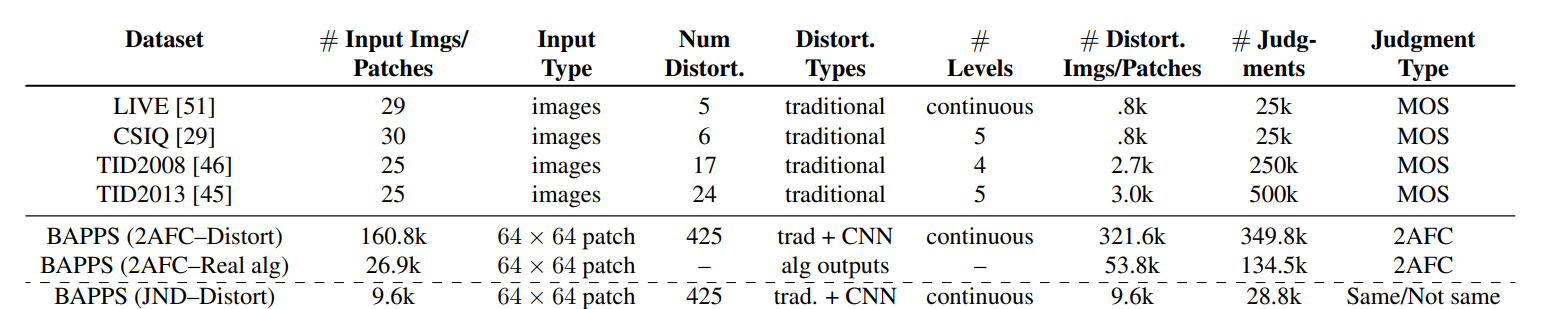 |
|---|
| 이렇게 다양한 distortion type들이 존재한다. |
Psychophysical Similarity Measurements
지금까지와는 다른 신기한 이 두가지 판단 방법을 사용했다.
- 2AFC similarity judgments
- Just noticeable differences(JND)
기존의 dataset들은 MOS나 DMOS와 같은 score들을 가지고 있었던 반면, 2AFC similarity judgments같은 경우에는 train은 2 judgments, val은 5 judgments를, JND도 3 judgment만을 가진다.
3. Deep Feature Spaces
이 논문에서는, 다양한 network들로 feature distance들을 평가하고 있다. 여기서는 convolutional layer에 대해 cosine distance (in the channel dimension)을 계산하고 spatial dimension과 network의 layer에 걸쳐 평균을 구하는 방법을 사용했다.
Network Architectures
SqueezeNet, AlexNet, VGG 세가지 architecture에 대해서 평가하고 있다.
- 5 conv layers from the VGG network
- conv1-conv5 layers from AlexNet
- first conv layer and some subsequent fire modules from SqueezeNet
Network activations to distance
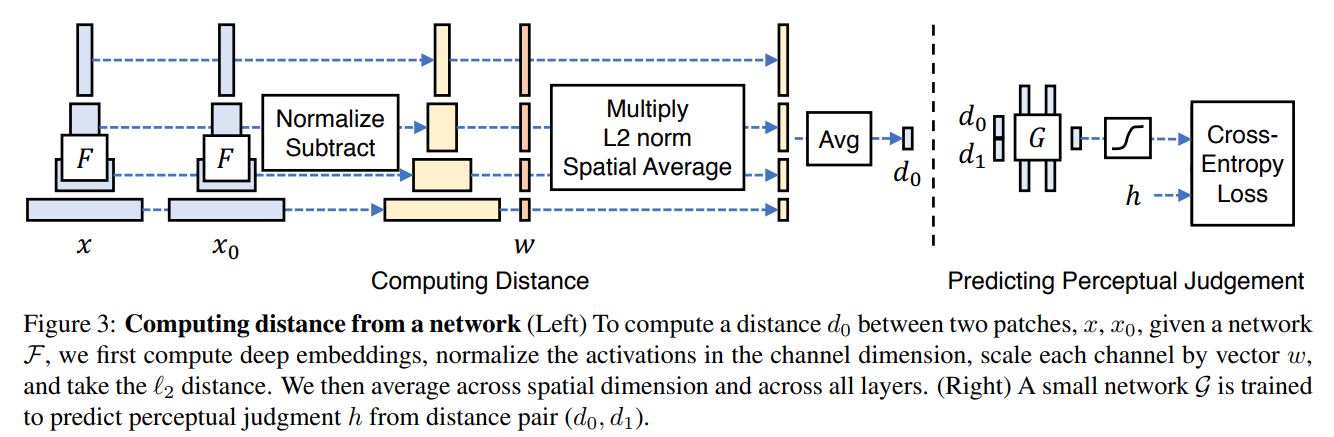 |
|---|
| network 를 거친 reference 와 distorted patch 의 distance를 구하는 방법 |
위의 그림을 보면,
1) 레이어들로부터 feature들을 뽑아낸 뒤, channel 차원마다 normalize를 한다.
2) 그리고 channel마다 activation값들을 scaling하여 벡터 로 만든 후, distance를 계산하고 각각 평균을 구하고 더해줌으로써 distance를 계산한다.
식은 다음과 같다.
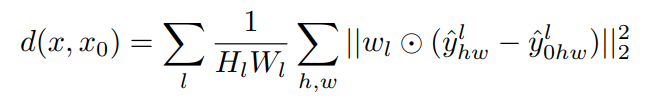
=> 주어진 convolutional layer에 대해, channel 차원상의 cosine distance를 구하고 spatial dimension과 network의 레이어에 걸쳐 평균을 구한다.
Training on our data
여기서 우리의 training with perceptual judgment를 위해 세가지 variant를 고려하는데, lin, tune, scratch 이다.
- lin : pre-train된 network의 가중치 를 고정하고 linear한 가중치 를 그 위에 학습한다. -> 이를 통해 기존의 feature space에 있는 일부 파라미터들의 "perceptual calibration"을 구성!
- tune : pre-train된 classification 모델에서 초기화 후, network 에 대한 모든 가중치가 fine-tune된다.
- scratch : random한 Gaussian 가중치에서 초기화하고, 우리의 judgment로 전체를 학습한다.
이 논문에서는 이 세가지를 "Learned Perceptual Image Patch Similarity metric"라고 말한다.
그리고 이 metric을 사용하여 이 논문이 이끌어내고자 하는 바를 위한 실험을 진행한다.
4. Experiments
이 부분은 수행한 실험 결과를 바탕으로 다음 질문들에 답을 하는 형식으로 이루어져있다.
질문들과 그에 대한 답은 다음과 같다.
-
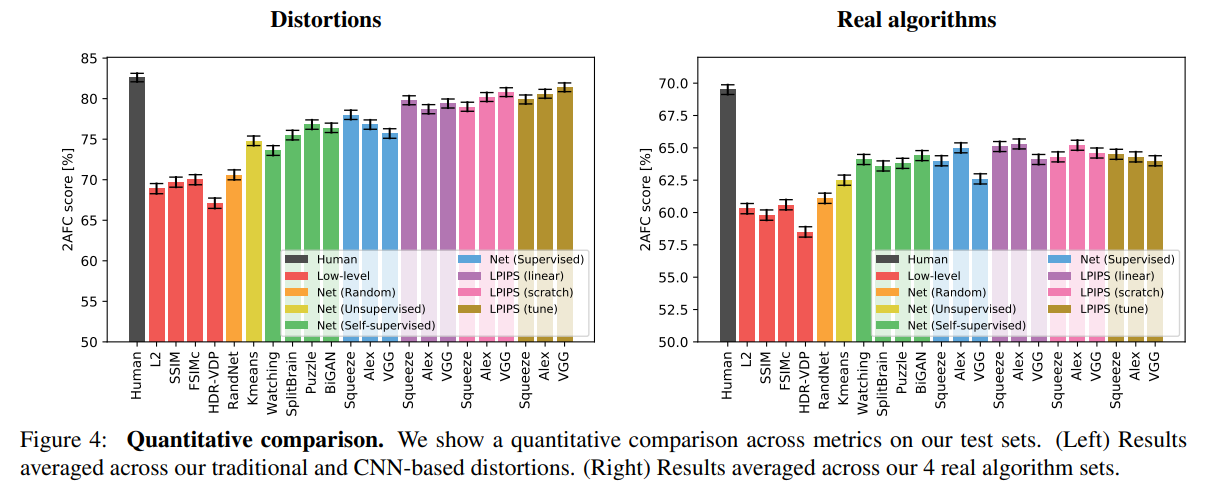
How well do low-level metrics and classification networks perform?
- 위의 그래프를 보면, 다양한 low-level metrics와 deep network, human ceiling의 성능을 볼 수 있다. SSIM 등의 low-level metric들이 deep network보다 낮은 성능을 보이고 있다.
-
Does the network have to be trained on classification?
- classification task가 아닌 unsupervised & self-supervised 모델들의 성능을 비교해보았을 때 역시 좋은 성능을 볼 수 있다.
-
Can we train a metric on traditional and CNN-based distortions?
- lin, scratch, tune 이 세가지를 각각 사용한 성능을 비교해보면, lin과 scratch보다 network를 fine-tuning하도록한 network가 더 성능이 좋았으며, 이는 곧 network가 perceptual judgments를 정말로 학습할 수 있다는 것을 알 수 있다! -
Does training on traditional and CNN-based distortions transfer to real-world scenarios?
- real-world algorithm으로 일반화하는데에도 좋은 성능을 보이는지에 대한 질문인데, 결과적으로 linear classifier을 학습하는 것은 확실히 성능을 높였고, scratch의 경우에는 lin보다는 낮았지만 low-level metric보다는 훨씬 좋은 성능을 보였다. 이는 test task에 distortion이 real algorithm을 판단하는데 분명히 사용되었음으로 해석할 수 있다.
(하지만, 여기서 pre-train된 network에 tuning한 경우가 낮은 성능을 보였고, 논문에서도 흥미롭지만,,,negative한 결과라고 언급하고 있다)
5. Conclusion
이 논문의 결론은, classification과 detection에 feature들이 강할수록, perceptual similarity judgment모델로서도 강하다는 것으로, 결국은 classification과 detection에서 잘하면 deep feature이 visual recognition와의 거리가 가깝다는 것이다.
즉, "good feature is a good feature".
논문 정리를 마치며,
간단한(?) 결론에 비해 읽으면서 이해하는데 꽤 오랜 시간이 걸린 논문이다. 당연하게 알고 있다고 생각했던 결론이지만, 이를 이끌어낼 때 생겼던 의문점들을 질의응답 형식으로 잘 정리해준 논문이라 생각한다. 엄청난 인용수를 보이는 논문이고,, 그만큼 중요한 논문이겠지,,!!!
끝`(>﹏<)′

Southern Kentucky Fire and Sprinkler stands out among the leading fire protection companies in Raleigh NC
, renowned for its comprehensive solutions and commitment to safety. With a rich history of excellence, the company offers cutting-edge fire prevention systems, including advanced sprinkler installations and meticulous fire safety inspections. Their team of experts is dedicated to providing tailored services that meet the unique needs of each client, ensuring robust protection and peace of mind. Whether for residential or commercial properties, Southern Kentucky Fire and Sprinkler delivers unparalleled expertise and reliability in fire protection.