bert의 replication study인 RoBERTa 논문을 리뷰, 정리 해보았다.
Paper :
RoBERTa: A Robustly Optimized BERT Pretraining Approach
논문의 main 컨셉
-
BERT가 나온 후 BERT 기반으로 다양한 네트워크들이 나옴
-
하지만 기존 BERT를 활용 + Training data 증대 /하이퍼 파라미터 조정/ Batch size 늘림 으로도 충분히 성능이 높아질 수 있음을 주장
-
또한, 기존 BERT에서 Pre-trained할 때 활용하는 대표적인 기술 1) masking 2) Next sentence classification 중에서 2)의 효과에 대한 의문을 제기 + 실험을 통해 확인함
-
하지만 masking의 경우 뚜렷한 효과가 있으며 기존 BERT는 3가지 TYPE으로만 마스킹을 진행하고 있으나 현 논문에서는 10가지 타입의 다양한 Masking을 도입함으로써 성능 증가를 보여줌
-
기존 BERT에서 단순히 Training data를 늘리고 batch size를 늘림으로써도 성능이 더 올라갈 수 있음을 보여줌
Abstract
BERT는 상당히 undertrained 됐다. RoBERTa로 GLUE, RACE, SQuAD nlp task에서 SOTA를 달성하였다. 이 결과는 설계에 중요성을 강조했다.
Introduction
기존의 버트에서 수정한 사항
-
training the model longer, with bigger batches over more data
데이터 16GB-->160GB / 많은데이터로 학습하는게 더 나은 성능을 보임
배치크기 256-->8000 / learning rate도 동시에 높임. 시퀀스로 사용하는 배치사이즈를 늘렸기에 step은 줄었고 성능 좋음 -
removing next sentence prediction(NSP) objective
nsp loss 제거, / 긴문맥이 있는 데이터셋에서 nlp loss를 제거하면 성능이 떨어진다고 기존의 bert가 언급. -
training on longer sequences
sentence length 늘림 -
dynamically changing the masking pattern applied to the training data
기존 bert는 static masking 사용. -
collect a large new dataset
Training Objectives
pretraining 중에, 버트는 두가지 objectives를 사용했다.
1. masked language modeling
- input이 random하게 들어가서 special token(mask)로 대체된다.
- mlm objective는 마스크 토큰을 예측하는데 cross-entropy loss이다.
- bert는 15% 토큰을 변경한다. 그 중 선택된 토큰의 80%는 mask, 10%는 안바뀌고, 10%는 랜덤으로 다른 vacabulary token으로 변환된다. 랜덤 마스킹과 대체는 처음에 한번만 수행되고 training할 때 save되어있다.
- 데이터는 fin-tuning할 때마다 복제되고, mask가 다를 수 있다.
2. next sentence prediction
- nsp는 binary classification loss로 (positive examples)연속된 다음 문장에서 다음 corpus에서 가져오고 (negative examples)다른 문서의 segment에서 가져온다. 이 두 개는 equal probability하게 sampled된다.
- nsp objective는 문장 간의 관계를 확인해 downstream task 성능을 더 높인다.
Data
버트는 위키피디아(16GB) 사용했지만 ROBERTa 는 더 많은 데이터 수집했다. (over 160GB)
- BookCorpus plus english wikipedia
- CC-news
- Openwebtext
- stories
Training Procedure Analysis
1. static vs. Dynamic Masking
기존의 bert
[static mask]
마스킹할 때 bert에서는 data preprocessing할 때 한번만 랜덤하게 마스크를 적용하고 모든 에폭에서 train input에 동일한 마스크가 반복적으로 사용되었다. 그래서 이를 피하고자 훈련 셋을 10배로 복제하여 10개의 다른 mask가 들어가도록 했다. 전체 40epoch, 따라서 하나의 방법을 4epoch씩 수행했다.
이것이 비효율적이라 생각하여 생각해낸 구조가 ~
roberta
[Dynamic Masking]
전처리에서 마스킹을 미리 하지 않고, 모델에 입력할 때마다 마스킹 작업 수행하여 매순간 새로운 마스킹 패턴이 나오게 만들었다.
2. Model input format and next sentence prediction (NSP 방법 미사용)
최근 연구에서 NSP loss 의문이 있다. 몇가지 training formats에 비교해본다.
-
SEGMENT-PAIR+NSP
-기존 bert와 동일 각각의 segment는 다수의 문장들을 포함하고 512token 이하로 이루어짐 -
SENTENCE-PAIR+NSP
-하나의 문서에서 쪼개진 인접한 문장으로 구성한다. 512 token보다 작은 사이즈로 구성되나, batch size를 키워 segment와 비슷한 크기 유지한다. -
FULL-SENTENCES
-경계를 넘을 경우 문단이 끝이 나면 다음 문단도 계속하여 탐색한다. 512 token이하의 연속된 전체 문장으로 구성하고 다른 문서 사이에 구분 토큰을 넣어준다.
-NSP 파라미터 제거 -
DOC-SENTENCES
-FULL-SENTENCES와 유사하나 다른 문서의 경계를 넘지 않는다. 512 token보다 작은 사이즈로 구성되나, batch size를 키워 FULL-SENTENCES와 비슷한 크기 유지한다.
-NSP 파라미터 제거
정확도 높은 순서
doc sentences > full sentences > segment > sentence
segment > sentence : 다수문장이 단일문장 방식에 비해 정확도가 높은 이유는 단일문장은 long range 의존성을 학습할 수 없기 때문이다.
앞의 두 개는 NSP제거하여 성능이 더 좋다. 또한 뒤에 두 개는 한문장씩 넣으면 뒤에 padd가 너무 많이 남아서 정확도가 좀 더 떨어지는게 아닌가 생각이 든다.
논문에서는 doc sentences가 full sentences보다 정확도는 높지만 배치사이즈를 다르게 설정했기에 다른 관련 모델들과 비교하기 쉽게 full sentences 사용했다.
3. training with large batches
- batch size를 키우면 학습 속도와 정확도 모두가 향상된다.
- 기존 BERT모델은 1M steps와 256 batch size에서 학습되었으나, 사이즈를 8K로 키운 결과 ppl(데이터 학습시 복잡도)가 낮아짐을 확인할 수 있다.
복잡도란 ?
확률 분포 또는 확률 모델이 표본을 얼마나 잘 예측하는지 측정 한 것으로 낮을수록 정확함을 의미함
4. text encoding
Byte-Pair Encoding(BPE)를 사용한다.
기존의 bert
전처리하고 Wordpiece tokenizing 방법 중 하나인 byte pair encoding를 실시했다(charactoer-level BPE vocabulary size 30k).
roberta
추가적인 전처리 없이 더 큰 byte-level BPE(vocabulary size 50k) 실시했다.
몇 task는에서 안좋은 성능을 보였지만 그럼에도 범용 인코딩 체계 장점으로 수행한다.
BPE 예시
1.1 띄어쓰기 기반 단어 나누기
1.2 character 기반 한 글자씩 나누기
ex) 나, 는, 사, 과, 야
1.3 맨 앞글자를 제외한 나머지 글자는 ##붙이기
ex) 나는 사과야 ==> 나, ##는, ##사, ##과, ##야
1.4 중복을 제거한 vocal 후보 만들기
ex) 나는 사과야, 나는 배야 --> 나, ##는, ##사, ##과, ##야, ##배
1.5 bi-gram pair만들기
ex) 나, ##는, ##사, ##과, ##야 --> (나,##는), (##는,##사),(##사,##과)....등등
1.6 가장 많이 나온 빈도의 pair를 best pair로 지정
1.7 best pair는 합치기
ex) (##사,##과) ==> ##사과
RoBERTa
결국에 RoBERTa는 위에 작성된 4가지 방식대로 학습이 되었다는 것
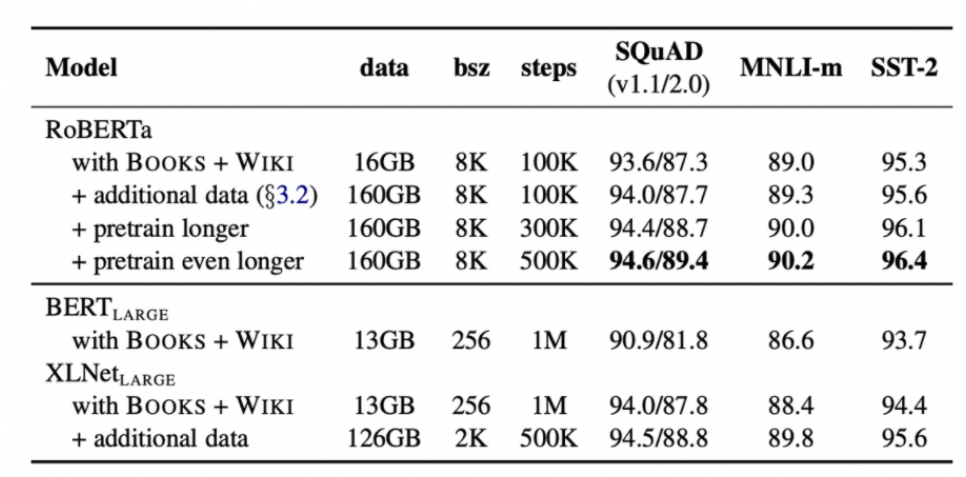
하지만 이 4가지 방식 이외에도 1) 데이터를 얼마나 학습시키느냐(epoch), 2) 데이터를 얼만큼씩 넘기느냐(batch size)도 매우 중요하다.
XLNet이 잘할 수 있었던 것은 구조 뿐만이 아니라 결국에는 이러한 특징들이 있었기 때문이다. 즉, BERT보다 batch size도 크고 오래 학습시키니 성능이 더 나올 수 밖에 없었다.
분석을 위해 기존 BERT-large에 제공된 데이터들로만 학습을 시키고 점점 데이터셋과 학습 시간을 늘려나가는 식으로 학습을 진행시켰다.
먼저, 동일한 data에 대해서 학습만 시켜도 RoBERTa식의 학습이 매우 좋은 성능을 보였고 데이터를 추가하고 더 오래 학습시킬 수록 더 높은 성능을 보이는 모습을 보였다.
Reference :
blog1
blog2
+paper
