대회와 프로젝트를 진행하며 가장 많이 사용했던 RoBERTa 모델. KLUE에서 Huggingface에 공개하기도 했고 한국어로 pre-trained가 매우 잘 되어 있어 여러 task에 fine-tuning하기 적합했다.
하지만 BERT 기반에 학습법만 다르게 했던 모델이라고만 알고 있었을 뿐 자세히는 알지 못했다. 따라서 이번 기회에 논문을 직접 살펴보며 공부해보고자 했다.
💡 요약
BERT 모델은 매우 대단한 모델이지만 학습을 부족하게(혹은 잘못) 시키고 아직 그 능력을 모르고 있다. 그래서 그 측면이 더 발현되도록 학습 방식을 발전시키고 hyperparameter등을 조정한다면 XLNet과 같이 BERT를 이긴 모델들을 압도할 수 있다.
그 방식은 아래 네 가지다.
(1) training the model longer, with bigger batches, over more data
- 모델을 더 많은 데이터로 오래 그리고 더 큰 batch로 학습
(2) removing the next sentence prediction objective
- NSP 학습을 삭제
(3) training on longer sequences
- 더 긴 문장들에 대해 학습
(4) dynamically changing the masking pattern applied to the training data
- Mask를 dynamic하게 바꿔줌(epoch마다 중복되지 않도록)
💻 Introduction
Self-training methods 방식은 대표적인 ELMo, GPT, BERT 모델들을 학습시키는 방식이다.
이렇게 학습 시킨 모델이 성능이 매우 뛰어나지만 어떤 학습의 면이 성능을 상승시켰는지 분석하는 것은 쉽지 않다.
- 분석하는 cost도 상당히 높음(모델이 크고 parameter가 많기 때문에)
그래서 이들을 뜯어보며 hyperparameter도 튜닝해보고 학습도 시켜보고 이러다가 BERT가 매우 undertrained 되었다는 것을 깨닫게 되었다.
그래서 이를 더 확실히 학습시킬 수 있는 방법론적인 것을 반영한 RoBERTa 모델을 만들게 되었다.
사실 RoBERTa는 BERT 모델을 더 잘 학습시킬 수 있는 recipe 들로 학습시킨 것에 불과하다.
학습에 바꾼 방식은 아래와 같다
(1) training the model longer, with bigger batches, over more data
- 모델을 더 많은 데이터로 오래 그리고 더 큰 batch로 학습
(2) removing the next sentence prediction objective
- NSP 학습을 삭제
(3) training on longer sequences
- 더 긴 문장들에 대해 학습
(4) dynamically changing the masking pattern applied to the training data
- Mask를 dynamic하게 바꿔줌(epoch마다 중복되지 않도록)
위의 (4)번 방식이 GPT로 대표되는 auto-regressive(AR) 모델과 BERT로 대표되는 auto-encoder(AE) 모델의 장점만을 합한 generalized AR pretraining model인 XLNet을 능가한다고 얘기함
XLNet에 대한 이해는 추후에 정리
📌 참고사안
BERT 모델을 사용했으며 그 논문에서 사용하는 방식을 그대로 사용했으며 hidden vector size도 512로 설정하고 maximum length eh 512 동일하게 사용
🧪 Experiment Setup
- Implementation
거의 모든 설정을 BERT와 동일하게 진행했다.
하지만 peak learning rate and number of warmup steps 즉, scheduling 면에서는 다르게 실행했다. 실험적인 연구에 따라 epsilon의 term과 값 등을 조정해줌
we do not randomly inject short sequences, and we do not train with a reduced sequence length for the first 90% of updates. We train only with full-length sequences.
이 과정에서 짧은 문장은 주입하지 않고 문장 길이를 조정하지 않았으며 모든 길이로 적합하게 들어갈 수 있는 문장들만 학습을 진행.
Data는 최대한 많이 사용하려 했으며 Evalutation은 GLUE, SQuAD, RACE 등 다양한 것들에 대해서 진행
🔬 Training Procedure Analysis
We keep the model architecture fixed.7 Specifically, we begin by training BERT models with the same configuration as BERTBASE (L = 12, H = 768, A = 12, 110M params).
기존의 BERT-BASE 모형을 따랐다.
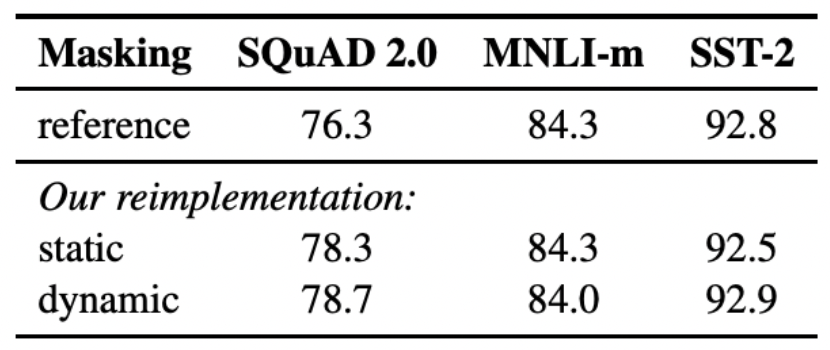
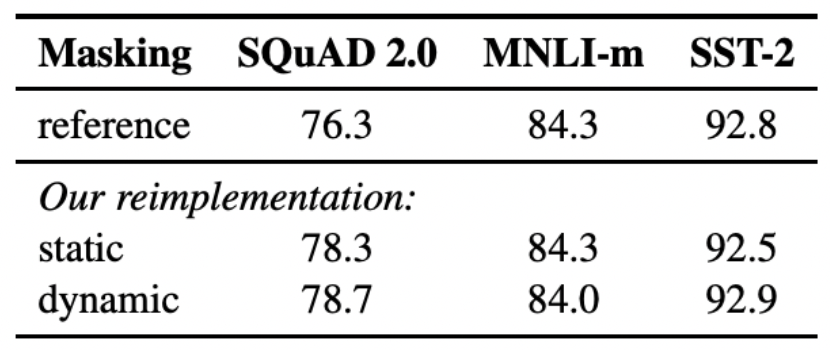
Static vs Dynamic Masking
BERT relies on randomly masking and predicting tokens.
BERT에서 사용하는 기법은 데이터를 10배 복사한 후에 그것들에 대해서 masking을 해주는 것이다. 하지만 이는 결국에 1way가 정해지고 그것을 4번 반복하므로 동일한 mask에 대해서 4번씩 학습하는 것에 불과하다.
- 즉, 데이터들을 복사하더라도 동일하게 구멍이 뚫린 세트들이 4번씩 반복된 것(40개가 다 다른 set이 아니다)
그래서 RoBERTa 연구진들은 데이터가 모델에 들어갈 때마다 masking을 새롭게 해주는 dynamic masking을 만들었다. 이렇게 해주는 것이 조금 더 성능을 늘리는데 도움이 되었다.
Model Input Format and Next Sentence Prediction
NSP를 제거하면 NLI나 QA task들에 대해서는 성능이 떨어지기는 했음
However, some recent work has questioned the necessity of the NSP loss (Lample and Conneau, 2019; Yang et al., 2019; Joshi et al., 2019).
그러나 NSP의 효용성에 대해서는 의문이 많다. 그래서 여러 가자의 set를 통해 모델 학습을 진행해보았다
-
Original = Segment-Pair + NSP
-
SENTENCE-PAIR+NSP
- part 별로 나누는 것이 아니라 온전한 문장이 들어가도록 만드는 방식
- 당연히 512 token보다 다 적으므로 batch를 더 증가시켜주었다.
- Full Sentence
문서를 따라가며 연속된 문장이 계속 들어가도록 구현해주었다. 그리고 이 과정에서 Document를 넘어서 문장이 들어갈 수 있도록 구성(그럴 때만 SEP 토큰을 넣어주었다)
- Doc Sentence 방식
Full Sentence와 기본적으로 동일하지만 하나의 문서가 끝나면 다음 문서로 넘어가지 않는다. 512보다 작은 것들이 다수 등장하게 되므로 batch size를 dynamically 하게 늘려주었다.
- 짧으면 batch를 키워주는 방식
결과!
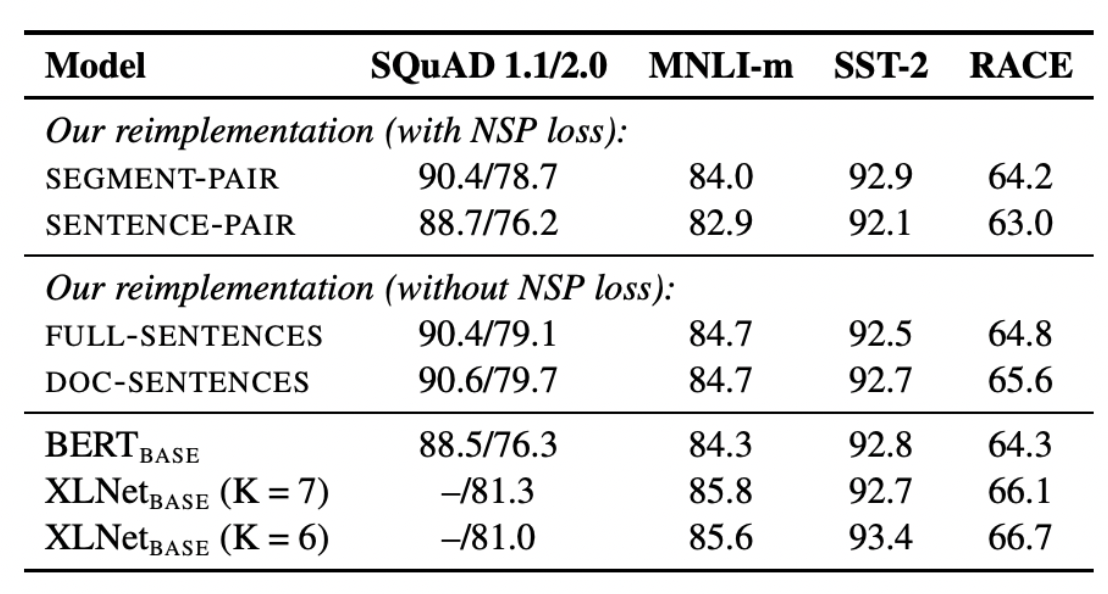
1, 2번 중에는 1번이 더 좋다(즉, 온전한 문장이고 아니고는 큰 문제 X) 모든 것 중에는 NSP를 제거한 것이 훨씬 좋다.
- 그중 다음 문서로 넘어가지 않는 방식이 더 좋지만 dynamic batch size 조정이 들어가므로 이후 실험은 3번으로 진행
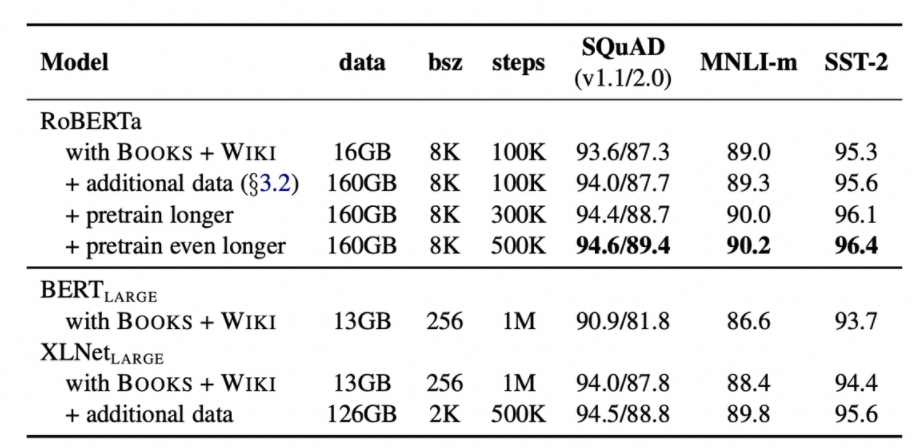
Training with large batches
large mini batches의 장점
- optimization speed increase
- end-task performance increase
- Equivalent computational cost
따라서 이를 위해 두 가지 방식으로 batch size를 다르게 해보았다.
- 기존 256 Batch를 2K로 늘리고 학습 진행
- 기존 256 Batch를 8K로 늘리고 학습 진행
결과적으로 더 큰 batch로 학습시킬 때 학습이 더 잘 되고 있음을 확인할 수 있다.
Text Encoding
기존 BERT에서 사용했던 BPE(Byte Pair Encoding)을 그대로 가져가기는 한다.
Byte-pair Encoding(BPE)는 word 단위와 character 단위의 중간에 있는 text encoding이며, 학습 코퍼스의 통계치에 의해 결정되는 sub-word unit입니다.
- 더 많이 등장하는 subword일 수록 가중치를 갖고 pair로 존재하게 된다.
Unicode characters can account for a sizeable portion of this vocabulary when modeling large and diverse corpora, such as the ones considered in this work. Radford et al. (2019) introduce a clever implementation of BPE that uses bytes instead of unicode characters as the base subword units. Using bytes makes it possible to learn a subword vocabulary of a modest size (50K units) that can still encode any input text without introducing any “unknown” tokens.
우선 훈련 데이터에 있는 단어들을 모든 글자(chracters) 또는 유니코드(unicode) 단위로 단어 집합(vocabulary)를 만들고, 가장 많이 등장하는 유니그램을 하나의 유니그램으로 통합합니다.
GPT 연구에서 BPE를 unicode 대신 bytes로 사용하는 방식을 통해 효율적으로 구현했으며 이를 차용해 RoBERTa에 대해서도 적용했다.
- 이 부분에 대한 공부도 필요할 것 같다.
별다른 전처리 없이 BPE를 학습시켰고 이 때문에 파라미터가 더 늘어나기는 했다(input으로 들어가는 것이 더 많아지기 때문)
결과적으로 몇몇 task에 대해서는 이러한 변화가 더 좋지 않은 성능을 보였으나 BPE 통일이 이후 연구에 도움이 될 것이라 판단해 그대로 진행했다고 밝혔다.
- 즉 어차피 GPT의 BPE가 더 좋으므로 이를 따른 것으로 보인다.
🚀 RoBERTa
결국에 RoBERTa는 위에 작성된 4가지 방식대로 학습이 되었다는 것
하지만 이 4가지 방식 이외에도 1) 데이터를 얼마나 학습시키느냐(epoch), 2) 데이터를 얼만큼씩 넘기느냐(batch size)도 매우 중요하다.
XLNet이 잘할 수 있었던 것은 구조 뿐만이 아니라 결국에는 이러한 특징들이 있었기 때문이다. 즉, BERT보다 batch size도 크고 오래 학습시키니 성능이 더 나올 수 밖에 없었다.
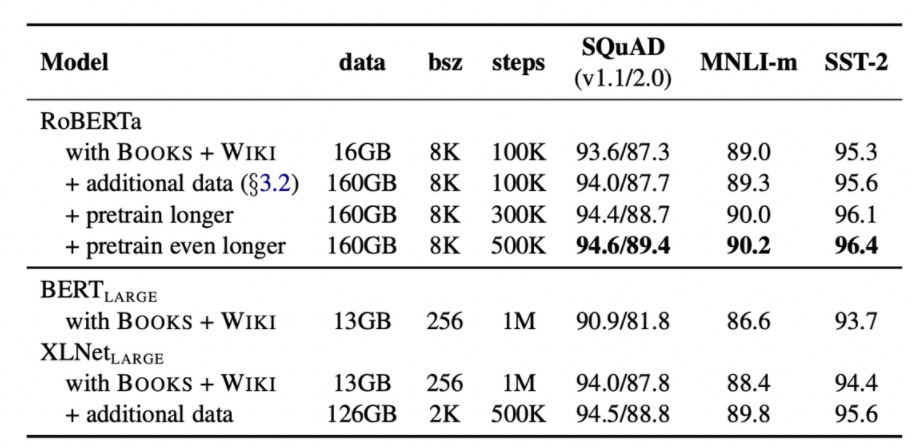
분석을 위해 기존 BERT-large에 제공된 데이터들로만 학습을 시키고 점점 데이터셋과 학습 시간을 늘려나가는 식으로 학습을 진행시켰다.
먼저, 동일한 data에 대해서 학습만 시켜도 RoBERTa식의 학습이 매우 좋은 성능을 보였고 데이터를 추가하고 더 오래 학습시킬 수록 더 높은 성능을 보이는 모습을 보였다.
✏️ 리뷰 후기
생각보다 너무 별 다른 내용이 없어서 놀랐다. BERT 논문을 워낙 많이 읽고 구조에 익숙했기에 더 읽기 적합했던 것 같다. 정말 많이 사용했던 모델을 더 깊이 알고 이를 통해 더 적합하게 사용할 수 있을 것이라는 생각이 들었다. 특히나 프로젝트를 하며 NLI를 위해 RoBERTa를 사용했었는데 그것보다는 차라리 XLNet이나 BERT를 사용하는 게 더 옳았나라는 피드백도 공부하며 얻을 수 있었다.
하지만 GPT 논문을 아직 읽지 못했기도 했고 그것의 BPE에 깊게 다룬 리뷰가 하나도 없어 너무 아쉬웠다. 이 부분에 대해 직접 논문을 읽으며 살펴봐야겠다는 생각이 들었다.
더불어, Dynamic Masking 기법이 정확히 어떻게 적용되는지 궁금해 여러 github을 뒤졌으나 자세한 내용이 없어 아쉬웠다. 연구진들의 github을 찾아보다가 발견하면 또다른 포스트로 적어야겠다.
