해당 포스팅은 QA와 관련된 논문 스터디를 진행 중에 공부했던 'Question Answering on SQuAD 2.0' 이라는 논문을 정리해보면서,
1) 기존 non-PCE method인 'BIDAF'모델과, 해당 논문에서 실험을 위해 사용한 'modified BiDAF model'을 비교 분석 해보고,
2) QA 구현 과정을 요약/정리 하였다.
논문 리뷰
1. Introduction
Q&A는 NLP에서 가장 도전적인 task 중 하나이다. 이 프로젝트의 목적은 Q&A task에서 RNN NLP 모델의 성능을 연구하는 것이다.
-
ELMo나 BERT 같은 PCE(Pre-trained Context Emeddings) 방법이 Q&A task에서 많이 사용되었고, BERT의 수정버전은 SQuAD v2.0에서 sota를 달성한다.
-
Non-PCE 모델은 PCE 모델만큼 잘 작동하진 않지만, 주어진 한정된 연산 자원 내에서 향상되는데 더 효율적이기 때문에 non-PCE 모델인 BiDAF를 baseline model로 선정했다.
-
성능 향상을 위해 실험에서는 baseline model에서 임베딩 layer에 character-level embedding, word features를 추가했고, self-attention layer를 적용했으며, RNN layer의 타입, optimizer, learning rate를 변경했다.
2. Related Work
PCE methods
- 문맥 주변의 정보를 포함한 더 나은 word embedding 제공하며, 대규모 신경망을 finetuning 함
- ELMo : 대량의 말뭉치에서 two-layer bidirectional LSTM으로 학습하고, 사전 학습된 layer는 다양한 NLP task에서 embedding layer로 사용 가능
- BERT : Transformer의 장점을 사용해 EMLo를 능가하고, Q&A를 포함한 많은 NLP task에서 sota 달성
BiDAF
BiDAF는 쿼리를 알고있는 문맥(Query-aware context representation)을 얻기 위한 양방향 Attention flow로, Q&A를 위한 양방향 네트워크이며, 여러 수준의 세분성(글자/단어/문맥)을 갖는 질문과 문맥사이의 상호작용을 표현한다.
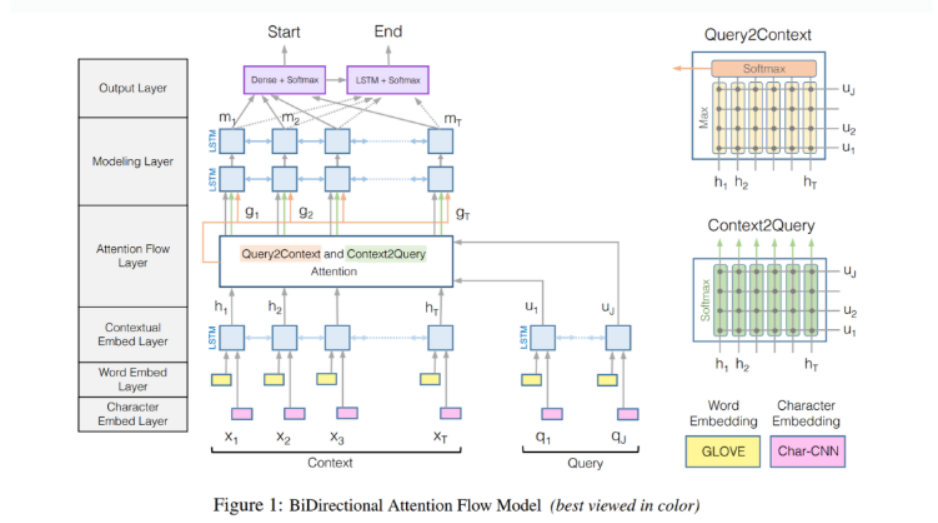
기본적으로 위의 6가지 layer를 갖고 있다.
본 논문에서는 R-Net의 self-matching attention layer와 DrQA의 Encoder Block을 적용 했다. 이 두 가지 모두 BiDAF에서 쉽게 적용될 수 있고, SQuAD에서 좋은 결과를 보여준다.
DrQA
DrQA는 위키피디아를 자원으로 활용한 Q&A task를 위한 모델이다. DrQA는 가장 빈번한 질문 단어를 fine-tuning하거나, word embedding과 정확히 일치하는 feature를 추가하는 등 결과 향상을 위한 여러 아이디어를 제시한다. 해당 논문에서의 모델 수정 과정은 DrQA에 영감을 받았다.
3. Approach
3.1 Baseline Model - BiDAF
- 단어 임베딩 레이어는 벡터 표현의 GloVe를 제공한다.
→ 임베딩된 단어 벡터는 숨겨진 상태를 얻기 위해 양방향 LSTM 인코더 계층으로 공급된다. - 질문과 텍스트는 동일한 인코더 계층을 공유한다.
→ 질문과 문맥의 숨겨진 상태는 질문과 문맥을 결합하는 Attention Layer로 이동한다. - Attention Layer에서 결합된 질문과 문맥의 정보는 다른 양방향의 LSTM 인코더로 전달된다.
- 인코더의 output hidden state는 마지막 출력 계층으로 전달된다.
- 출력 계층에서는 fully-connected layer와 softmax layer를 사용하여 시작 포인터의 위치를 예측하고, 다른 LSTM 인코더를 사용하여 마지막 포인터의 위치를 예측한다.
→ 임베딩된 단어 벡터는 숨겨진 상태 상태를 얻기 위해 양방향 LSTM 인코더 계층으로 공급된다.
3.2 Modified BiDAF Model Overview
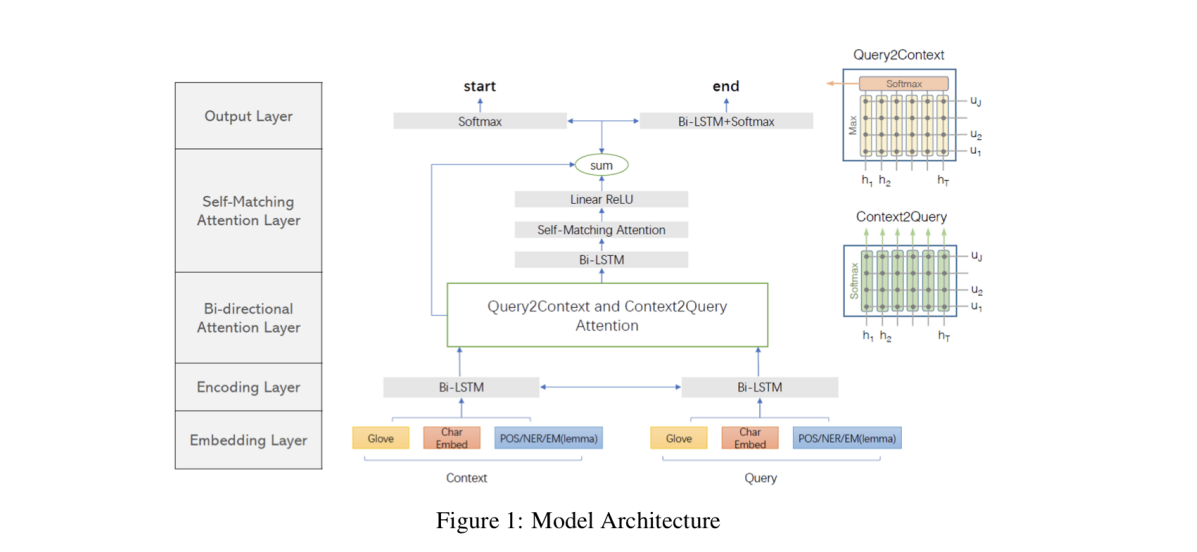
character level embedding, word features, self-attention layer을 추가하여 기존의 BiDAF 모델을 수정하였다.
3.3 Word Level and Character Level Embedding

character-level word embedding
-
단어의 의미를 더 명확하게 하고, 모르는 단어를 더 효율적으로 처리하며, BiDAF 논문에서도 제시됨
-
단어에 대해서가 아닌 각 단어에 해당하는 '문자'를 임베딩한다. 예를 들어 단어 'eat'을 'e', 'a', 't'과 같이 문자 단위로 분리 후 임베딩을 수행한다.
-
이후 CNN layer와 max pooling을 적용하여 character-level word embedding을 수행.
-
이렇게 얻은 스칼라 값들을 이용하여 character-level embedding과 word-level embedding을 연결하여 단어에 대한 새로운 표현 획득한다.
-
word level embedding과 character level embedding은 최종 표현으로 함께 연결되어 Highway 인코더에 공급
Word Features
- POS : 품사 분석 (동사인지, 명사인지 등등)
- NER : 개체명 인식 (사람인지, 장소인지 등등)
- EM(lemma) : 문맥의 단어가 해당하는 질문의 단어와 정확하게 매칭될 수 있으면 1, 아니면 0으로 지정
3.4 Encoding Layer

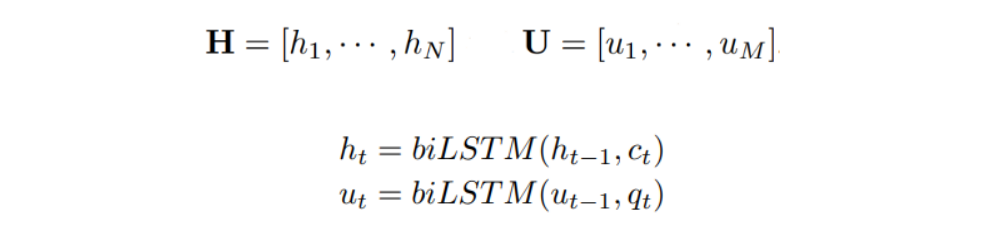
- Encoding Layer은 각각 임베딩된 질문(Q)과 문맥(C) 벡터를 양방향의 LSTM 인코더를 사용하여 새로운 표현으로 인코딩한다.
(단, N은 문단의 최대 단어 길이, M은 질문의 최대 단어 길이를 의미함.)
3.5 Bidirectional Attention Layer
-
Attention Layer은 인코딩된 H와 U 벡터를 입력으로 받는다.
-
먼저 i번째의 문맥의 단어와 질문의 단어 사이의 유사성 행렬 S를 얻는다.
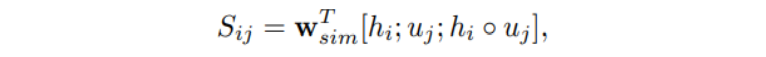
-
이후 문맥에 대한 질문 attention(C2Q)과 질문에 대한 문맥 attention(Q2C)을 계산한다.
-
C2Q attention
Attention distribution을 얻기 위해 유사성 행렬 S 열에 행마다의 softmax 연산을 수행한다.
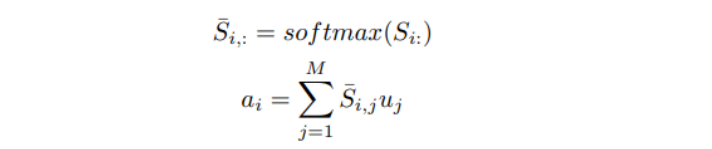
-
Q2C attention
Attention 출력값을 결합하여 질문을 인식할 수 있는 표현을 생성한다.
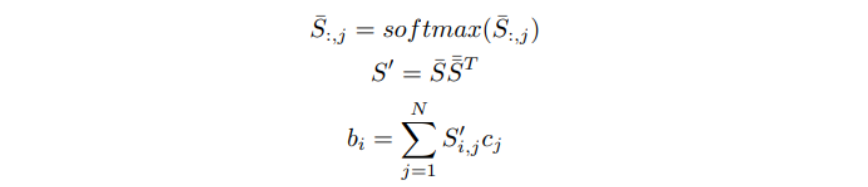
-
Attention 출력값을 결합하여 질문을 인식할 수 있는 표현을 생성한다.
3.6 Self-Matching attention Layer
- C2Q 및 Q2C 레이어를 사용하여 질문 인식 표현을 생성하지만 장기적인 의존성을 학습 하기에는 충분하지 않기 때문에 셀프 매칭 레이어를 추가한다.
- self-maching attention layer
먼저 양방향의 LSTM을 사용하여 벡터의 순서를 세분화하고, 단어가 자신과 일치할 경우 큰 수를 빼고 softmax를 적용하여 대각선의 유사성이 0에 근접한 유사성 행렬을 생성한다.
이후 Attention 벡터를 계산하고 질문과 자기 인식 표현을 종합한다.
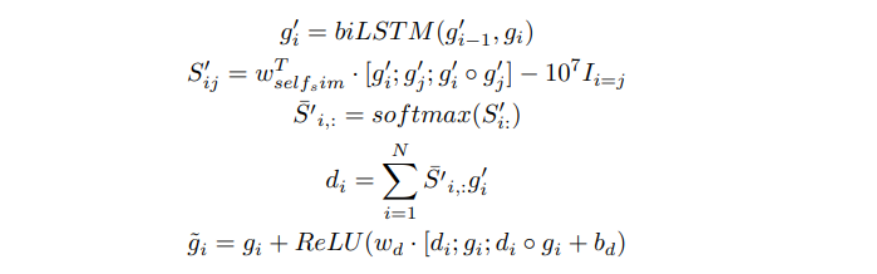
3.7 Output Layer
-
출력 계층에서는 양방향의 LSTM을 사용하여 표현을 세분화하고 응답 span의 확률을 계산한다.
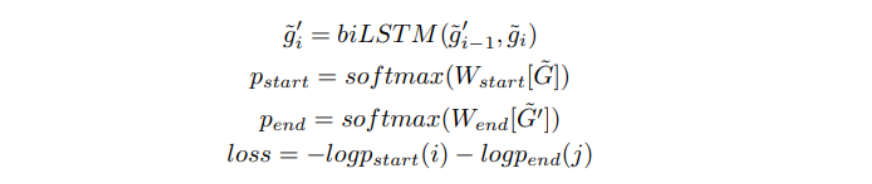
-
Adadelta optimizer을 사용하여 최적화를 수행하고 손실을 최소화한다.
4. Experiment
-
모델을 기존 BiDAF 모델과 비교
-
layer와 feature의 효과 분석
-
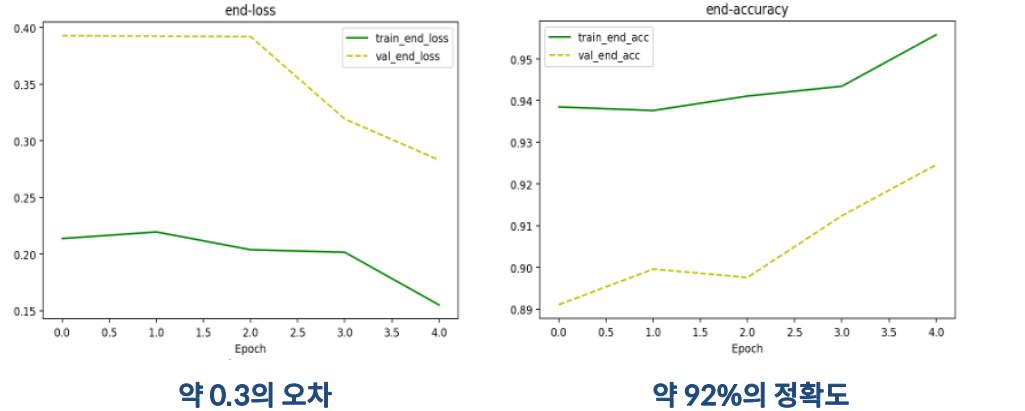
모델의 훈련 곡선 시각화
-
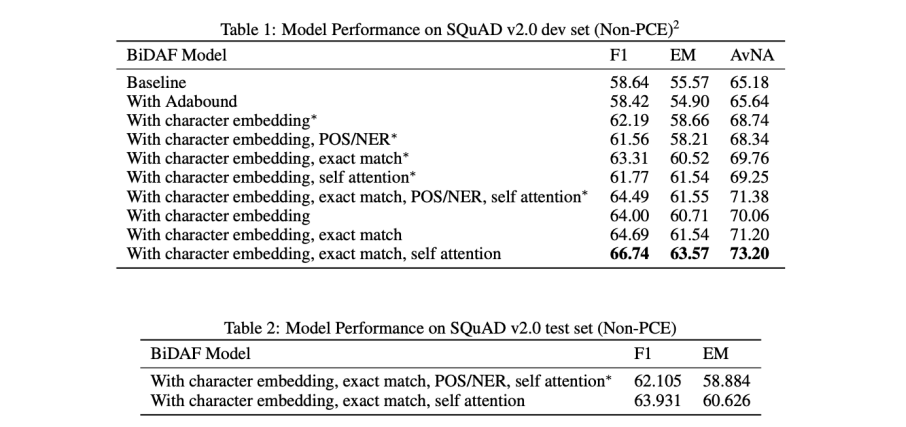
F1, EM, AvNA를 사용하여 table 1의 모델 평가
- 전체 기능을 갖춘 모델은 F1 : 66.74, EM: 63.57, AvNA : 73.20
- 이는 검증 데이터의 기준 모델인 F1 : 63.931, EM: 60.626 보다 약 8% 향상
- 수정된 모델이 기존 BiDAF 능가
- self attention 과 추가적인 word features를 받아들인 접근이 효과적
-
모델의 세부 성능을 추가로 탐색하기 위해 답변 길이 및 질문 유형과 함께 F1, EM 점수 요약
- 답의 길이가 길어지면 F1 점수가 급격히 하락 → 하지만 global F1 점수로 보아 명확하지 않음
- 대부분의 질문에는 짧은 답이 있기 때문에 긴 답변에 대한 예측은 전체 성과에 큰 영향 미치치 않음
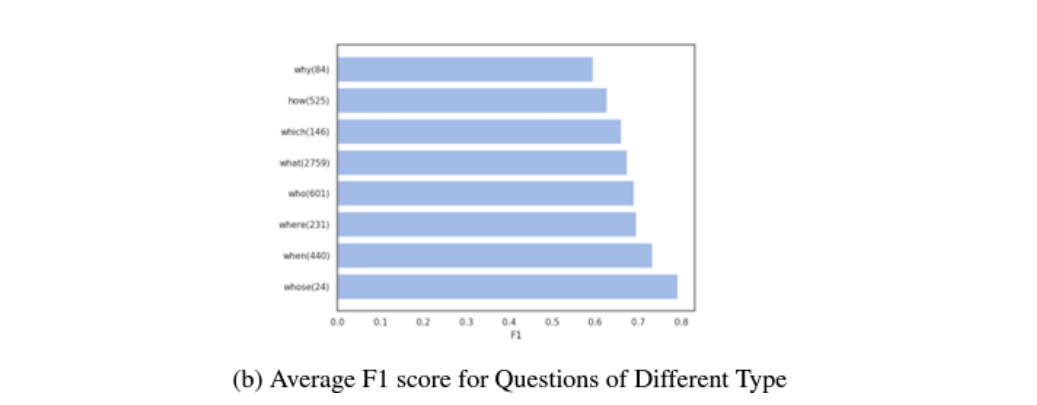
-
‘Whose’와 ‘When’이 더 높은 F1 Score로 시작
POS/NER 기능을 통해 단어의 유형을 인식할 수 있으며, 시간과 사람의 이름과 관련된 질문에 답하는데 도움 -
반면에 ‘why’, ‘how’ 문항은 상대적으로 낮은 F1 score 기록
이러한 유형 문항들이 문단에 대한 더 깊은 이해를 요구하기 때문
5. Conclusion
-
SQuAD 2.0에 non-PCE Question Answering model 구현
-
기존 BiDAF 모델과 비교하여 몇 가지 향상 달성
1) Character Embedding, Word features (POS/NER/exact match in lemma form), Self-attention layer 들을 추가하여 베이스라인 모델을 수정
2) 다양한 optimizer, 드롭아웃 비율, hidden layer 차원, RNN의 alternate 타입들도 시도
-
추가적으로 아래와 같을 때 모델 잘 수행 ❌
1) question ≈ context
2) answer 이 context 에 없고 논리적 추론이 요구될 때 -
향후 연구는
context와 다른 키워드에 패널티를 부여
self-attention 레이어를 더 추가하여 더 깊은 네트워크를 구축
구현 실습
논문에서 소개한 모델을 그대로 구현하고 싶었으나, 구성원 모두가 qa 모델을 처음 구현해보는 것이었기 때문에 기본 BERT 모델에 AIhub 에서 제공하는 일반상식 데이터를 적용해보며 QA 데이터셋과 기본적인 모델 구현과정을 익히는 것을 목표로 하였다!
AI hub의 일반상식 데이터
-
한국어 위키백과내 주요 문서 15만개에 포함된 지식을 추출한 데이터이다. (KorQuAD 와 유사)
-
위키백과 본문내용과 관련한 질문과 질문에 대응되는 위키백과 본문 내의 정답 쌍으로 구성되어 있다.
-
질문-답 쌍 데이터셋은 Context, question, answer를 각각 포함한다.
-
Paragraphs는 가장 상위의 클래스이며 질문-답 세트와 질문-답 세트의 근거 단락인 contex를 하위 클래스로 가진다.
-
Answer_start는 Context에서 정답이 위치하는 글자 인덱스를 의미한다.

Token embedding
- Token Embedding BERT는 텍스트의 tokenizer 로 Word Piece 모델이라는 subword tokenizer를 사용한다.
- tokenizer를 통해서 입력 문장을 토큰단위로 쪼개고, 해당 토큰을 vocab에 매칭하여 id(숫자)로 입력한다.
- vocab의 사이즈는 보통 5만정도를 사용하고있고, 이것을 직접 입력하여 BERT 모델을 구축하면 학습해야하는 파라미터의 수가 엄청나게 많아지기 때문에 차원을 낮추기 위해서 embedding layer를 사용한다.
다운로드 받은 Pretrained model 로드
Fine-Tuning
Pre-train된 BERT 모델을 이용해 수행하고자 하는 task를 추가 학습하는 것을 의미한다. 전이학습은 BERT의 언어 모델의 출력에 추가적인 모델을 쌓아 만든다.
조정 내용
-
BERT의 각 토큰마다 개별 Fully Connected layer를 붙여 한국어 용으로 미세 조정하기 위한 모델 클래스를 정의
-
작은 실습 환경에 맞춰 크기 조정
- 레이어 : 12 -> 6
- hidden neuron : 768 -> 512
-
pretrained model을 활용해서 입력에 대한 답변을 생성하는 함수를 정의한 후 결과 및 성능을 확인

- 토큰화된 단어 단위의 정답을 제대로 유추하였다는 것을 확인

-
토큰화된 단어에서 subword segmentation 되지 않은 정답을 추측하였다는 것을 확인 (작은 실습환경으로 인해 충분한 학습이 이루어지지 않은 것으로 추측됨)