BERT 모델을 복습하고자 해당 페이지에 정리해보았다!
BERT를 이해하기 위해 우선 Transformer 구조부터 알아야한다.
Transformer
Paper: Attention is all you need
인코더, 디코더 구조를 지닌 딥러닝 모델.
기존의 seq2seq 모델은 인코더에서 마지막의 hidden state, 즉 fixed-size context vector에 모든 정보가 압축된다. 이를 이용해 디코더가 예측을 하게 된다면, 입력 시퀀스의 길이가 길어지면서 정보 손실의 가능성이 생긴다.
이를 해결하기 위해 Attention 개념을 활용한다. 이를 이용해, seq2seq를 아예 대체하는 encoder-decoder 모델을 구현할 수 있고, 이를 Transformer(트랜스포머) 구조라고 한다.
전통적인 RNN based인 encoder, decoder는 순차적으로 계산한다. 문맥벡터가 고정된 크기여서 책과 같은 긴 입력값은 처리가 어렵다. 하지만 transformer는 병렬화, 즉 RNN을 사용하지 않고 일을 한번에 처리한다. 또한, 고정된 크기의 문맥벡터를 사용하지 않고 인코더의 모든 상태값을 활용한다.
- Encoder : 입력값을 양방향으로 처리
- Decoder : 왼->오른쪽으로 단방향으로 처리
- RNN을 적용하지 않는데, 단어의 위치 및 순서를 어떻게 알까?
-> positional encoding을 통해 상대적 위치 정보 알려준다. 함수로는 sin,cos 사용한다.
- 왜 sin, cos 함수를 사용할까?
- 함수의 출력값은 입력값에 따라 달라지기에 출력값으로 입력값의 상대적인 위치를 알 수 있다.
- 함수는 규칙적으로 증가 감소하기에 딥러닝모델이 이 규칙을 사용해서 입력값의 상대적위치를 쉽게 이용가능하다.
- 출력값은 –1에서 1사이이기 때문에 무한대 길이의 입력값도 출력 가능하다.
- positional encoding
class PositionalEncoding(nn.Module):
"""
compute sinusoid encoding.
"""
def __init__(self, d_model, max_len, device):
"""
constructor of sinusoid encoding class
:param d_model: dimension of model
:param max_len: max sequence length
:param device: hardware device setting
"""
super(PositionalEncoding, self).__init__()
# same size with input matrix (for adding with input matrix)
self.encoding = torch.zeros(max_len, d_model, device=device)
self.encoding.requires_grad = False # we don't need to compute gradient
pos = torch.arange(0, max_len, device=device)
pos = pos.float().unsqueeze(dim=1)
# 1D => 2D unsqueeze to represent word's position
_2i = torch.arange(0, d_model, step=2, device=device).float()
# 'i' means index of d_model (e.g. embedding size = 50, 'i' = [0,50])
# "step=2" means 'i' multiplied with two (same with 2 * i)
self.encoding[:, 0::2] = torch.sin(pos / (10000 ** (_2i / d_model)))
self.encoding[:, 1::2] = torch.cos(pos / (10000 ** (_2i / d_model)))
# compute positional encoding to consider positional information of words
def forward(self, x):
# self.encoding
# [max_len = 512, d_model = 512]
batch_size, seq_len = x.size()
# [batch_size = 128, seq_len = 30]
return self.encoding[:seq_len, :]
# [seq_len = 30, d_model = 512]
# it will add with tok_emb : [128, 30, 512]작동 원리
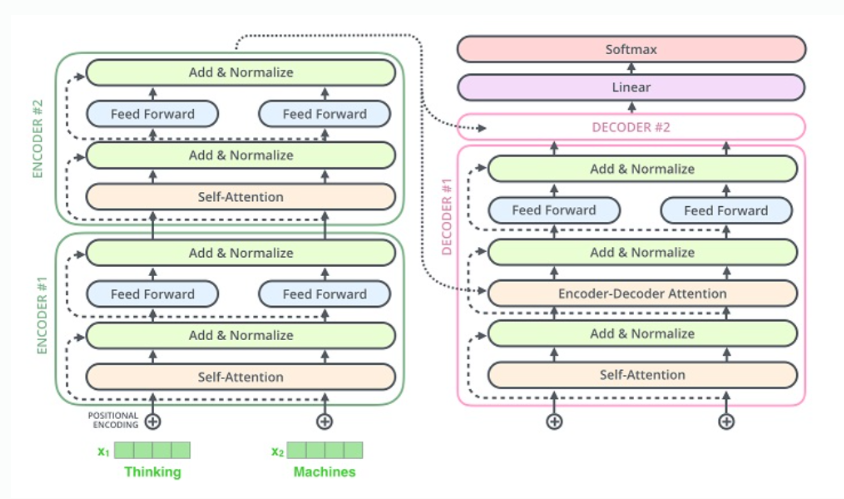
인코더
-
입력값이 인코더에 입력되면 토큰들은 포지셔닝 인코더와 더한다.
단어들을 병렬로 만든 후, 어떠한 행렬과 곱하여 query, key, value값이 생성된다. 이때 행렬은 weight metrics로 딥러닝 모델학습 과정에서 최적화된다.
(query, key, value값은 벡터의 형태) -
셀프 어텐션 연산을 해준다.
- self attention : 인코더에서 이루어지는 어텐션 연산
- 과정 -
현재의 단어는 Query, 어떤 단어와의 상관관계를 구할 때 어떤 단어의 key값을 구한다. query와 key를 곱한 경우 attention score 가 된다. 이는 숫자가 높을수록 단어의 연관성이 높다. attention score를 0~1사이로 만들기 위해 softmax함수를 사용한다. softmax의 결과 값은 key값에 해당하는 단어가 현재 단어의 어느정도 연관성이 있는지 나타낸다.
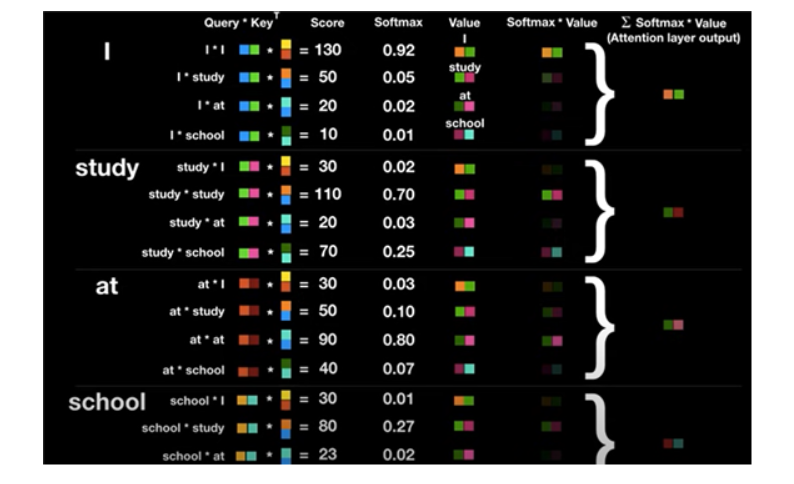
예를 들어,
'I'는 자기자신 'I'와 92%의 연관성을 갖는다. 각 key에 맞는 value값과 연관성을 곱해주면 연관성이 별로 없는 value값은 희미해진다. 이렇게 되면 최종 벡터 I는 단어 하나의 I가 아닌, 문장 속에서 전체적인 의미를 지닌 벡터 I가 된다.
모든 단어에 대해 어텐션 연산은 행렬곱으로 한번에 처리할 수 있다.
-> 병렬 처리의 장점!
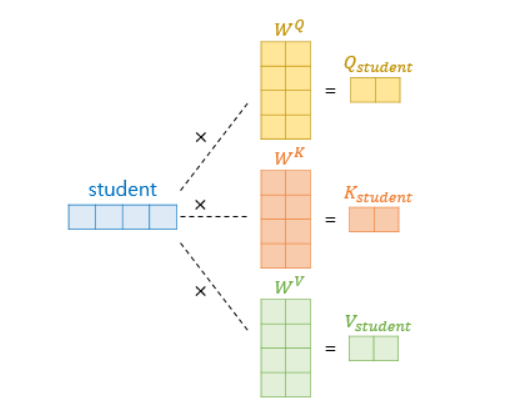
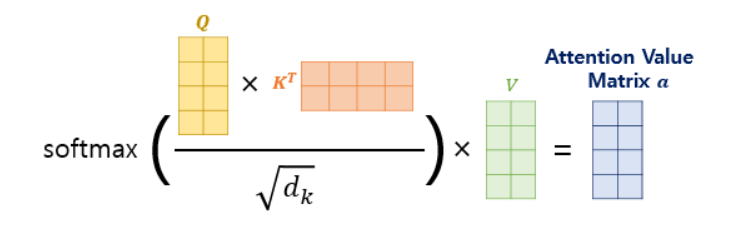
위의 결과를 통해 실질적으로 트랜스포머 논문에 나와있는 수식이 도출된다.
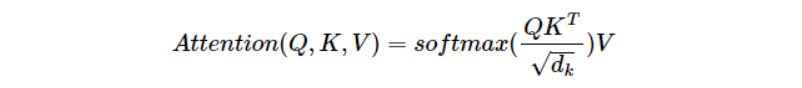
- multi head attention (병렬처리된 attention layer)
기계번역에 큰 도움을 준다. 한 개의 어텐션으로 모호한 정보를 충분히 인코딩하기 어렵기에 멀티 헤드 어텐션을 사용해서 연관된 정보를 다른 관점에서 수집해서 이 점을 보완할 수 있다.
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, n_head):
super(MultiHeadAttention, self).__init__()
self.n_head = n_head
self.attention = ScaleDotProductAttention()
self.w_q = nn.Linear(d_model, d_model)
self.w_k = nn.Linear(d_model, d_model)
self.w_v = nn.Linear(d_model, d_model)
self.w_concat = nn.Linear(d_model, d_model)
def forward(self, q, k, v, mask=None):
# 1. dot product with weight matrices
q, k, v = self.w_q(q), self.w_k(k), self.w_v(v)
# 2. split tensor by number of heads
q, k, v = self.split(q), self.split(k), self.split(v)
# 3. do scale dot product to compute similarity
out, attention = self.attention(q, k, v, mask=mask)
# 4. concat and pass to linear layer
out = self.concat(out)
out = self.w_concat(out)
# 5. visualize attention map
# TODO : we should implement visualization
return out
def split(self, tensor):
"""
split tensor by number of head
:param tensor: [batch_size, length, d_model]
:return: [batch_size, head, length, d_tensor]
"""
batch_size, length, d_model = tensor.size()
d_tensor = d_model // self.n_head
tensor = tensor.view(batch_size, length, self.n_head, d_tensor).transpose(1, 2)
# it is similar with group convolution (split by number of heads)
return tensor
def concat(self, tensor):
"""
inverse function of self.split(tensor : torch.Tensor)
:param tensor: [batch_size, head, length, d_tensor]
:return: [batch_size, length, d_model]
"""
batch_size, head, length, d_tensor = tensor.size()
d_model = head * d_tensor
tensor = tensor.transpose(1, 2).contiguous().view(batch_size, length, d_model)
return tensor참고
인코더는 출력벡터의 차원이 입력벡터와 동일하다. 따라서 여러 개 붙일 수도 있다. 각각의 인코더는 가중치를 공유하지 않고 따로 학습한다. 실제 transformer는 encoder block을 6개 붙임!
- Position-Wise Fully Connected Feed-Forward Network
attention 연산으로 구한 벡터값들은 두 개의 선형 layer와 relu 활성화 함수로 이루어진 Feed-Forward Network를 거친다.

class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, hidden, drop_prob=0.1):
super(PositionwiseFeedForward, self).__init__()
self.linear1 = nn.Linear(d_model, hidden)
self.linear2 = nn.Linear(hidden, d_model)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(p=drop_prob)
def forward(self, x):
x = self.linear1(x)
x = self.relu(x)
x = self.dropout(x)
x = self.linear2(x)
return x- 딥러닝을 수행할 때, 역전파로 인해 position encoding이 손실될 수 있다. 이를 보완하기 위해 residual connection으로 다시 한번 더하고 layer normalization으로 학습 효율을 증진시킨다.
-
ResNet (residual connection)
모델의 layer가 너무 깊어질수록 gradient vanishing(미분값이 작아져 weight정도가 작아지는 것) 문제 때문에 오히려 성능이 떨어지는 현상이 발생한다.
Input은 그대로 가져오고, 나머지 잔여 정보인 F(x)만 추가적으로 더해주는 단순한 형태로 만들어 학습한다. 즉 output에 이전 레이어에서 학습했던 정보를 연결함으로써 해당 층에서 추가적으로 학습해야 할 정보만을 학습하게 된다. 이는 구현이 간단하며, 학습 난이도가 매우 낮아진다. 복잡도와 성능을 더 개선시키고 깊이가 깊어질수록 높은 정확도 향상을 보인다. -
layer normalization
각 샘플에 대해서, 모든 피처에 대해 평균과 분산을 구해 정규화하는 것이다.
class LayerNorm(nn.Module):
def __init__(self, d_model, eps=1e-12):
super(LayerNorm, self).__init__()
self.gamma = nn.Parameter(torch.ones(d_model))
self.beta = nn.Parameter(torch.zeros(d_model))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim=True)
var = x.var(-1, unbiased=False, keepdim=True)
# '-1' means last dimension.
out = (x - mean) / torch.sqrt(var + self.eps)
out = self.gamma * out + self.beta
return out인코딩 과정을 정리해보면,
워드임베딩 -> position embedding 추가 -> multi head attention->feed forward(순방향 신경망) -> residual connection
- 최종적인 인코더 구현 코드
class EncoderLayer(nn.Module):
def __init__(self, d_model, ffn_hidden, n_head, drop_prob):
super(EncoderLayer, self).__init__()
self.attention = MultiHeadAttention(d_model=d_model, n_head=n_head)
self.norm1 = LayerNorm(d_model=d_model)
self.dropout1 = nn.Dropout(p=drop_prob)
self.ffn = PositionwiseFeedForward(d_model=d_model, hidden=ffn_hidden, drop_prob=drop_prob)
self.norm2 = LayerNorm(d_model=d_model)
self.dropout2 = nn.Dropout(p=drop_prob)
def forward(self, x, src_mask):
# 1. compute self attention
_x = x
x = self.attention(q=x, k=x, v=x, mask=src_mask)
# 2. add and norm
x = self.dropout1(x)
x = self.norm1(x + _x)
# 3. positionwise feed forward network
_x = x
x = self.ffn(x)
# 4. add and norm
x = self.dropout2(x)
x = self.norm2(x + _x)
return x디코더
디코더 순서
masked multi head attention -> multi head attention -> feed forward layer (순방향 신경망)
- 디코더 입력
디코더 입력은 ① 인코더 마지막 블록에서 나온 소스 단어 벡터 시퀀스 ② 이전 디코더 블록의 수행 결과로 도출된 타깃 단어 벡터 시퀀스이다. - masked인 이유: 디코더에서 지금까지 출력한 값에만 attention을 적용하기 위해 붙여졌다. 아직 출력되지 않은 미래에 단어에 attention을 적용하면 안되기 때문이다.
디코더는 첫 단어부터 순차적으로 단어를 출력한다. 디코더 또한 어텐션 병렬처리를 활용한다. 현재까지 출력된 값에 어텐션을 적용한다. 디코더는 디코더의 현재 상태를 query로 인코더의 최종 출력값을 key, value 값으로 사용한다. 현재 상태를 Query로 인코더에 질문하고 인코더에 출력값에서 중요한 정보를 key, value로 획득해서 decoder에 다음 단어에 가장 적합한 단어를 출력하는 방식이다.
그 뒤는 인코더와 마찬가지로 feed forward를 거쳐 벡터로 출력한다.
벡터를 어떻게 실제 단어로 출력할까?
linear layer(softmax입력값으로 들어갈 로짓 생성)와 softmax layer(확률값 출력-가장 높은 확률값을 지닌 단어가 다음 단어가 된다.)를 이용한다. 마지막으로 label smoothing을 이용한다.
-
label smoothing
출력값을 0~1 내에서 정답에 가까우면 1에 가까운 값 오답은 0에 가까운 값으로 변환시킨다. (단 0과 1이면 안됨.) 이는 모델 학습 시에 모델이 학습데이터에 너무 치중하여 학습하지 못하도록 보완하는 기술이다.
레이블이 noise 한 경우, 즉 같은 입력값인데 다른 출력값이 학습데이터에 많을 경우 도움이 된다. 예를 들면, 원핫인코딩 사용시 고맙다와 감사합니다는 의미는 같은데 상이한 다른값이 되지만 smoothing을 통해 두 단어는 보다 가까운 벡터가 되고, 차이도 줄어들기에 효율적으로 학습할 수 있다. -
디코더 코드 구현
class Decoder(nn.Module):
def __init__(self, dec_voc_size, max_len, d_model, ffn_hidden, n_head, n_layers, drop_prob, device):
super().__init__()
self.emb = TransformerEmbedding(d_model=d_model,
drop_prob=drop_prob,
max_len=max_len,
vocab_size=dec_voc_size,
device=device)
self.layers = nn.ModuleList([DecoderLayer(d_model=d_model,
ffn_hidden=ffn_hidden,
n_head=n_head,
drop_prob=drop_prob)
for _ in range(n_layers)])
self.linear = nn.Linear(d_model, dec_voc_size)
def forward(self, trg, src, trg_mask, src_mask):
trg = self.emb(trg)
for layer in self.layers:
trg = layer(trg, src, trg_mask, src_mask)
# pass to LM head
output = self.linear(trg)
return outputBERT
: bidirectional encoder representations from transformers
Paper : BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
기존 GPT1 한계점
왼->오른쪽으로 단방향 처리는 문장이해에 약점이 있을 수 있다. 또한, 한번 학습시키는데 엄청난 시간이 든다.
BERT는,
-
양방향으로 이해해서 숫자의 형태로 바꿔주는 형태이다.
-
동일한 문장 그대로 학습하되, 가려진 문장 예측하도록 한다.(masked token)
-
한 문장말고 질의 및 응답 같은 두 문장도 받을 수도 있다. 질문과 응답 같이 주어진 질문에 적합하게 대답해야하는 문제에 해결가능하다. 양쪽 방향으로 처리하기에 질의 및 응답 구조 예측 가능한 것이다. 문장 간의 상관관계도 파악이 가능하여 문장 주제 찾기 또는 분류하기 가능하다.
-
Transformer의 Encoder 구조를 중점적으로 사용한 모델이다.
decoder를 사용하지 않고, encoder를 학습시킨 후에(pre-training) 특정 task의 fine-tuning을 활용하여 결과물을 얻는 방법으로 사용된다. -
self attention layer를 여러 개 사용하여 문장에 포함되어 있는 token 사이의 의미 관계를 파악한다.
전이학습 모델
구글의 Devlin(2018)이 제안한 BERT는 사전 학습된 대용량의 레이블링 되지 않는(unlabeled) 데이터를 이용하여 언어 모델(Language Model)을 학습하고 이를 토대로 특정 작업( 문서 분류, 질의응답, 번역 등)을 위한 신경망을 추가하는 전이 학습 방법이다.
사전 학습 모델
대용량의 데이터를 직접 학습시키기 위해서는 매우 많은 자원과 시간이 필요하지만 BERT 모델은 기본적으로 대량의 단어 임베딩 등에 대해 사전 학습이 되어 있는 모델을 제공하기 때문에 상대적으로 적은 자원만으로도 충분히 자연어 처리의 여러 일을 수행할 수 있다.
BERT의 임베딩
pre-training 과정에서 세가지 임베딩을 사용한다.
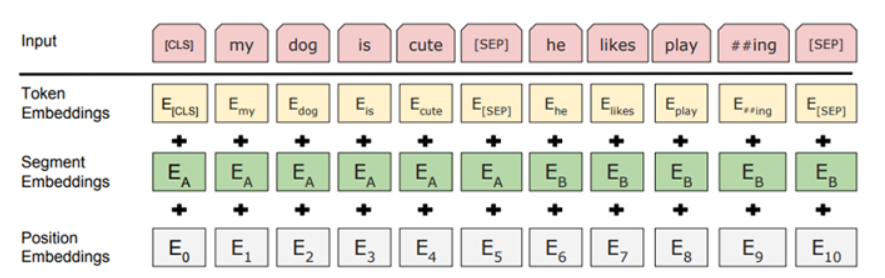
-
token embeddings
wordpiece embedding으로 분리한다. 단어 의미로 분리가 아닌, 예를 들면 playing이란 단어를 play와 ing로 분류하는 방법이다. 장점 : 두 가지의 의미를 명확히 전달 가능하다. 신조어나 오탈자가 있는 단어도 학습단계에서 흔치않은 단어에 대한 예측이 향상된다.
Special Classification token(CLS)은 모든 문장의 가장 첫 번째(문장의 시작) 토큰으로 삽입된다. 이 토큰은 Classification task에서는 사용되지만, 그렇지 않을 경우엔 무시된다. -
segment embeddings
두 문장이 입력될 때, 각 문장에 서로 다른 숫자를 더해주는 것, 딥러닝 모델에 두 개의 다른 문장이 있다는 것을 알려주기 위해 사용되는 임베딩이다.
Special Separator token(SEP)을 사용하여 첫 번째 문장과 두 번째 문장을 구별한다. 여기에 segment Embedding을 더해서 앞뒤 문장을 더욱 쉽게 구별할 수 있도록 도와준다. 이 토큰은 각 문장의 끝에 삽입된다. -
position embeddings
각 토큰의 상대적 위치 정보 알려준다. 함수로는 sin,cos 이용한다.
-> 최종 input으로 세 가지 임베딩을 더한 임베딩을 사용한다.
BERT의 문장표현 학습 방법
문장 표현을 학습하기 위해 두가지 unsupervised 방법을 사용한다.
Masked Language Model
문장에서 단어 중의 일부를 [Mask] 토큰으로 바꾼 뒤, 가려진 단어를 예측하도록 학습한다. 이 과정에서 BERT는 문맥을 파악하는 능력을 기르게 된다. 추가적으로 더욱 다양한 표현을 학습할 수 있도록 80%는 [Mask] 토큰으로 바꾸어 학습하지만, 나머지 10%는 token을 random word로 바꾸고, 마지막 10%는 원본 word 그대로를 사용하게 된다.
Next Sentence Prediction
다음 문장이 올바른 문장인지 맞추는 문제를 통해 두 문장 사이의 관계를 학습하게 된다.
문장 A와 B를 이어 붙이는데, B는 50% 확률로 관련 있는 문장 또는 관련 없는 문장을 사용한다.

위의 그림과 같이 BERT는 [SEP] 특수 토큰으로 문장을 분리한다.
학습 중에 모델에 입력으로 두 개의 문장이 동시에 제공된다.
50%의 경우 실제 두 번째 문장이 첫 번째 문장 뒤에 오고, 50%는 전체 말뭉치에서 나오는 임의의 문장이다.
그런 다음 BERT는 임의의 문장이 첫 번째 문장에서 분리된다는 가정 하에 두 번째 문장이 임의의 문장인 여부를 예측한다.
이를 위해 완전한 입력 시퀀스는 Transformer 기반 모델을 거치며,
[CLS] 토큰의 출력은 간단한 분류 계층을 사용하여 2x1 모양의 벡터로 변환된다.
IsNext-Label은 softmax를 사용하여 할당된다.
BERT는 손실 함수를 최소화하기 위해 MLM과 NSP을 함께 학습한다.
""" BERT pretrain """
class BERTPretrain(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.bert = BERT(self.config)
# classfier
self.projection_cls = nn.Linear(self.config.d_hidn, 2, bias=False)
# lm
self.projection_lm = nn.Linear(self.config.d_hidn, self.config.n_enc_vocab, bias=False)
self.projection_lm.weight = self.bert.encoder.enc_emb.weight
def forward(self, inputs, segments):
# (bs, n_enc_seq, d_hidn), (bs, d_hidn), [(bs, n_head, n_enc_seq, n_enc_seq)]
outputs, outputs_cls, attn_probs = self.bert(inputs, segments)
# (bs, 2)
logits_cls = self.projection_cls(outputs_cls)
# (bs, n_enc_seq, n_enc_vocab)
logits_lm = self.projection_lm(outputs)
# (bs, n_enc_vocab), (bs, n_enc_seq, n_enc_vocab), [(bs, n_head, n_enc_seq, n_enc_seq)]
return logits_cls, logits_lm, attn_probs
Reference
https://jalammar.github.io/illustrated-transformer/
https://github.com/dhye1/transformer-evolution
https://velog.io/@sjinu/Transformer-in-Pytorch
+Papers
