[논문 리뷰] VL-LTR_ Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition
Paper Review
본 논문은 CLIP의 visual정보와 language 정보를 모두 활용하여 long-tailed data의 tail class에서 부족한 정보량을 보충하는 방법에 대한 연구를 소개하고 있다.
Paper : VL-LTR_ Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition

Intro
: Long-tailed distribution in Real-world
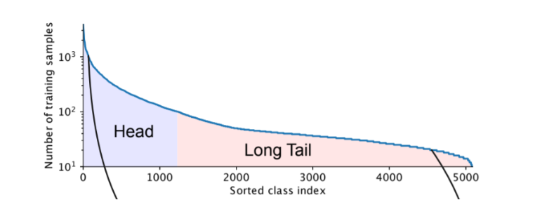
- 소수의 head class가 데이터의 대부분을 차지하고, 나머지 tail class는 데이터가 부족한 long-tailed 분포를 띈다.
- 이에 따라 데이터 수가 많은 head class에 편향이 생기고, 데이터가 적은 tail class로 인해 성능이 떨어지게 된다.
Language modality 활용 가능성
-
Image modality
- 구체적이고, low-level 특징을 표현한다. (ex. 모양, 색, 질감 ..) -
Language modality
- 추상적이고, high-level 특징까지 표현 가능하다.
- 전문가에 의한 사전지식이 포함할 수 있다.
=> class 별 표현 학습에 필요한 이미지가 충분하지 않을 때 활용해볼 수 있다!
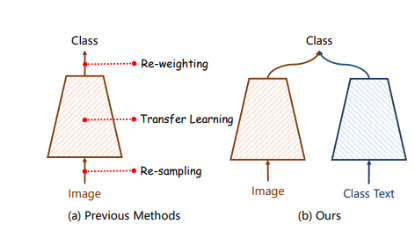
그러나, 기존의 연구는 image modality 에만 의존한 solution 이고, text modal을 불균형 문제에 통합한 시도는 거의 없다.
VL-LTR: Learning Class-wise Visual-Linguistic Representation for Long-Tailed Visual Recognition
본 논문은 long-tailed recognition을 위한 visual-linguistic framework인 VL-LTR을 소개한다.
Contribution
1) long-tailed visual recognition에서 텍스트 정보가 이미지 정보를 보충하는 새로운 방법론 제시
2) long-tailed visual recognition의 새로운 프레임워크 제시
" class-wise text-image pre-training (CVLP) + language-guided recognition (LGR) "
3) 다양한 long-tailed recognition benchmarks (ImageNet-LT, Places-LT, and iNaturalist 2018)에서 SOTA 달성
Related work
Class re-balanced Strategy
1) Data Resampling
- head나 tail의 sample 비율을 조정하여 균형을 맞추는 방식
ex) over/under sampling, smote.. - 그러나, augment 된 소수 클래스에서 overfitting 가능성 높다
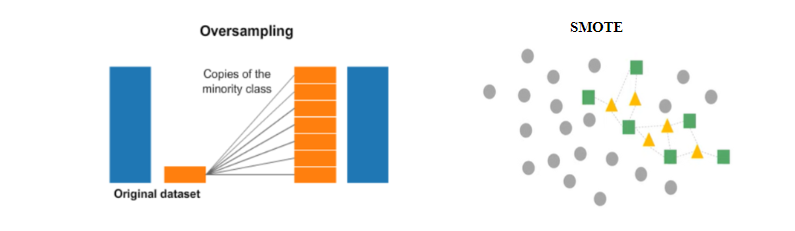
- overfitting 완화하기 위해,
다수 클래스의 feature space 에서 소수 클래스를 up-sampling 하거나,
다수 클래스의 데이터를 소수 클래스 데이터로 변형하여 소수 클래스를 up-sampling 하는 접근 방식 연구됨
2) Re-weighting loss function
- 클래스 별 반영 비율을 loss function을 통해 조정하는 방법
ex) Focal loss : 높은 probability로 예측한 sample의 loss에 가중치를 주어 어려운 sample을 보다 잘 학습할 수 있도록 돕는다.
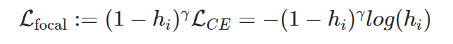
ex) LDAM loss : 속한 데이터 개수가 작은 few-shot class가 더 넓은 margin을 가지게 하여 weight를 조정한다.
3) Transfer learning
- 충분한 데이터를 포함한 head class에서 얻은 feature을 이용해, tail class의 representation learning에 이용하는 방법
세 가지 Class re-balanced strategy 모두 image modality에 한정된 rebalancing method 이다.
Methodology
VL-LTR은 two-stage 프레임워크를 갖는다.
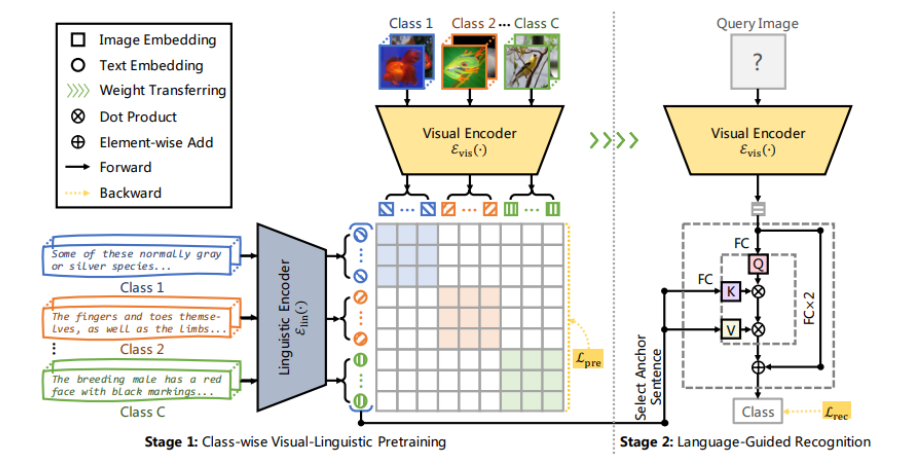
Stage 1. Class-wise visual-linguistic pre-training (CVLP)
- 클래스 별 visual-linguistic 관련성을 학습하는 pre-training 과정
- 기존의 pre-train visual-linguistic 모델과 달리, 클래스 별로 표현 학습함으로써 long-tailed visual recognition 성능을 향상시킴
- Contrastive Learning 기반 표현 학습을 활용하여 long-tailed data 에서도 효율적인 학습을 목표로 한다.
Pre-training 목표 :
Visual-Linguistic representation을 학습하여, 클래스 별 언어적 정보를 visual recognition에 활용
Pre-train Loss 함수

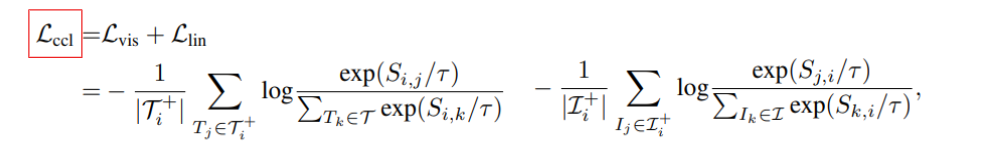
(1) L(ccl) Pre-training Process

(2) Distillation
제한된 text corpus로 인한 overfitting 방지하기 위해, CLIP에서 pre-train 된 정보를 활용한다.
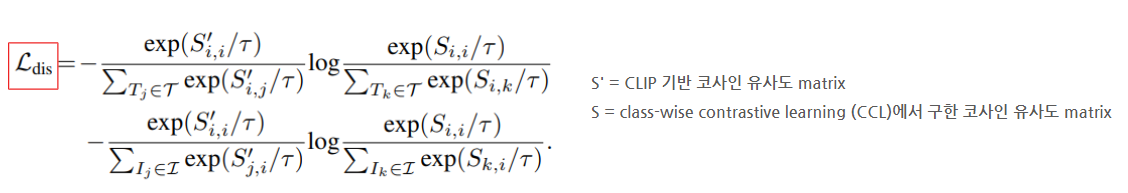
Pre-training framework 장점
- class level 이미지 샘플에 대한 text는 독립적이고, 매 반복마다 달라질 수 있다.
-> fixed image-text pair로 학습할 때보다 정규화된 모델 얻을 수 있고, noisy text에 강하다.
Stage 2. Language-guided recognition (LGR)
학습된 visual-linguistic representation 활용하여 image classification 진행할 수 있도록 fine-tuning 하는 과정
- 사전학습된 visual-linguistic 표현에 기반한 long-tailed recognition 수행
- Visual recognition에 언어 정보 활용, noisy text 에 강한 method
(1) Anchor Sentence Selection
인터넷에서 수집한 noise text는 recognition 성능 저해하므로, 가장 구별되는 중심 문장을 선별한다.
- Process

(2) Language-Guided Recognition Head
LGR Head를 optimizing 하기 위해, 이미지와 문장의 attention score를 구한다.
- Q, K, V = Attention 연산에서의 query, key, value
- Image의 Q와 Anchor sentence의 K,V 를 사용하여 attention score 연산
- G = M개의 Anchor sentences에 대한 attention score
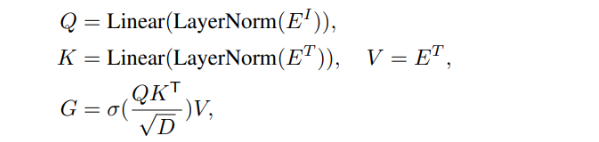
- PI, PT = Visual / Linguistic representation에 기반한 classification 확률
최종 rec loss function
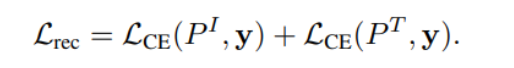
stage 2 (LGR) 에서는,
1) 앵커 문장 선택 후
2) 구한 앵커 문장과 이미지와의 attention score에 기반한 loss값을 통해 LGR Head를 optimizing 한다.
Experiments
Datasets
- 세 가지 long-tailed visual recognition benchmarks을 사용했다.
- ImageNet-LT, Places-LT, iNaturalist 2018 - 추가적으로, 세 가지 datasets 에 대한 class-level text descriptions 을 수집하였다.
- Wikipedia 에서 class 에 대한 descriptions 수집 후 전처리
Settings
- visual encoder : ResNet-50 또는 ViT-Base/16
- linguistic encoder : 12-layer Transformer
- optimizer : AdamW
- pre-training
- CLIP의 pre-trained weights 사용 ( 50 epochs, mini-batch size = 256 ) - fine-tuning
- class 마다 64 sentences 선별 ( 50 epochs, mini-batch size = 128 )
Results (ImageNet-LT)
1. 대표적인 long-tailed recognition methods 와 비교
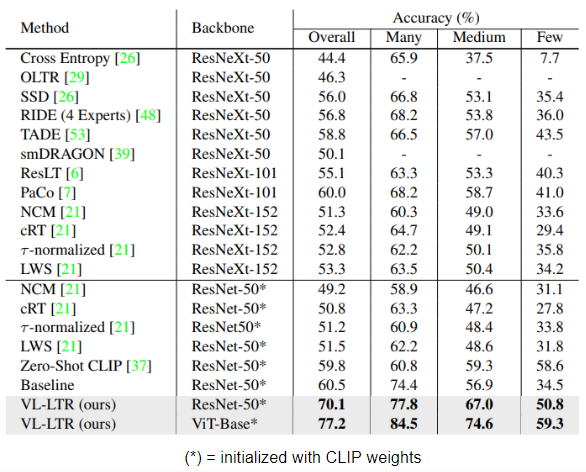
- ResNet-50 backbone 적용 시(70.1%),
- baseline(60.5%) 보다 9.6% 나은 성능 보임
- 기존 best model PaCo(60.0%) 보다 10.1% 나은 성능
- few-shot 에서 baseline 보다 16.3% 나은 성능 보임
- ViT-Base/16 backbone 적용 시 77.2%
- ImageNet-LT 에서 SOTA 달성
2. baseline과 비교했을 때, class 별 성능 개선도
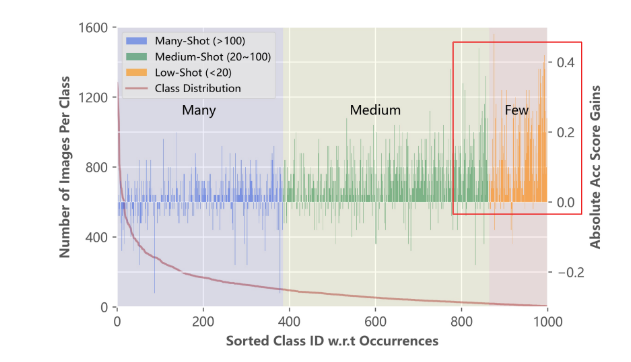
- baseline = VL-LTR method 에서 visual modality 정보만 반영한 버전
- tail classes에서 더 좋은 accuracy 점수 달성
-> class별 text descriptions 사용이 Long-tailed 문제를 완화하는데 기여했다고 볼 수 있다.
Ablation Study
1. Class-wise Visual-Linguistic 사전학습을 수행하지 않았을 때의 결과와 비교하는 실험을 진행했다.
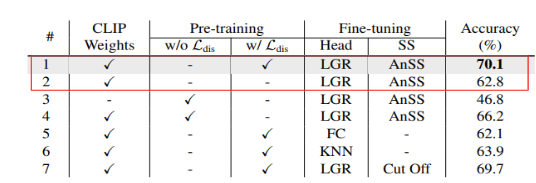
- CVLP framework 제거했을 때 성능이 떨어지는 것을 확인할 수 있다.

- VL-LTR vs CLIP
rare 한 컨셉을 인식할 때, (ex. "spot", "stick"), class level에서 pre-train 한 VL-LTR이 CLIP보다 잘 맞추는 것을 확인할 수 있다.
2. CLIP Pre-trained Weights & Distillation Loss
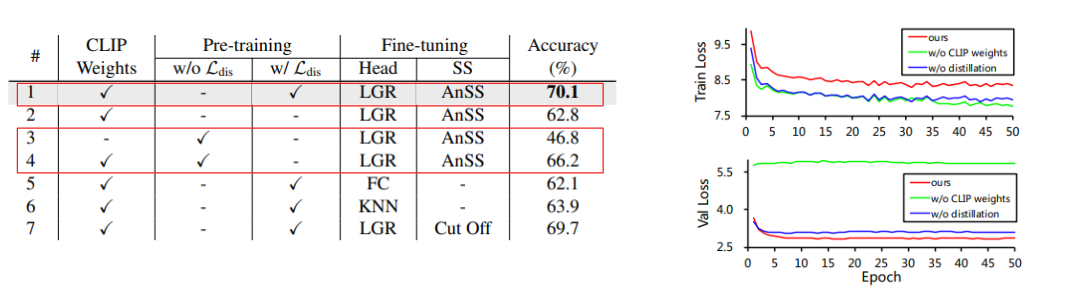
- CLIP의 pre-trained weights를 적용한 VL-LTR 모델의 성능이 더 좋은 것을 확인 (#1, #3)
- Distillation을 수행한 모델의 성능이 더 높음 (#1, #4)
- training 과 validation loss 비교 (오른쪽 그림)
- Fine tuning 단계에서 CLIP pre-trained weights와 Distillation Loss가 overfitting을 완화시킨다.
- ImageNet-LT의 text description 만으론 text corpus가 제한적이기 때문
Conclusion
요약
1) class-level visual-linguistic pre-training (CVLP)
=> 이미지와 설명텍스트를 class level에서 matching시켜서 학습한다.
2) language-guided recognition (LGR) head
=> Visual recognition에 visual-linguistic representation을 활용한다.
- image, text 두 modal을 사용하여 class imbalance 문제를 해결한 새로운 접근 방식으로, 다양한 long-tailed recognition benchmarks 에서 기존의 vision-based methods 보다 좋은 성능 달성했다.
Limitations
- 언어적 표현 학습시킬 때 기존의 pre-trained model (CLIP)에 의존해야 하므로 Text corpus가 제한적이다.
- Two-stage LTR method를 발전시켜, end-to-end 학습 방법에 대한 연구가 필요해보인다.
