[논문 리뷰] ConZIC_ Controllable Zero-shot Image Captioning by Sampling-Based Polishing
Paper Review
본 논문은 controllable signal을 적용한 최초의 zero-shot captioning method인 ConZIC을 소개한다.
Paper : ConZIC_ Controllable Zero-shot Image Captioning by Sampling-Based Polishing

Introduction
최근 제로샷 가능성은 딥러닝에서 중요한 이슈이다. 특히, 이미지캡셔닝에서의 기존 Supervised methods들은 많은 양의 high quality paired data에 의존하고, train data 분포에서 벗어나는 real-world에 대한 정보를 반영하기 어렵다는 한계점이 존재한다.
이에 본 논문에서는
1) Gibbs sampling과 MLM의 관계를 분석하여, 새로운 Language Model인 Gibbs-BERT를 제안하고,
2) 이를 CLIP과 결합한 Controllable Zero-shot Image Captioning method인 ConZIC을 소개한다.
Related work
이미지 캡셔닝 task를 zero-shot으로 수행하고자 하는 연구가 진행되었고, 그 중 대표적인 method가 Zerocap이다.
- Zero-shot image captioning, ZeroCap
: 거대 pre-trained 모델의 지식을 활용하여 지도학습 없이 캡션을 생성- ZeroCap 관련 정리는 이전 MAGIC 논문 리뷰에서 했으므로 간단히 언급하고 넘어가겠다.
기존에 존재하는 유일한 zero-shot captioning 모델인 Zerocap은 아래와 같은 한계점이 존재한다.
ZeroCap의 한계점
- Autoregressive generation은 한방향으로 생성되므로, 단어가 한 번 생성 되면 바꿀 수 없다. -> not flexible
- ZeroCap의 반복적인 context cache update는 계산 시간을 증가시킨다. -> inefficient
- ZeroCap은 beam search 방법으로 후보 문장을 생성하므로 (deterministic method), 생성된 캡션이 유사한 패턴을 보인다. -> low diversity
- ZeroCap에서 controllability에 대한 고려는 반영되지 않았다.
=> 이러한 한계점을 극복하는 Controllable Zero-shot Image Captioning, ConZIC을 소개한다.
Controllable Zero-shot Image Captioning, ConZIC
Main Contribution
- Gibbs-BERT를 사용하여 bidirectional하게 정보를 반영하고, 초기 생성된 캡션을 더 나은 방향으로 수정할 수 있다. -> more flexible
- ConZIC은 추가 parameter update 과정 없기 때문에, Zerocap보다 5배 빠른 속도 -> efficient
- ConZIC의 Gibbs-BERT는 generation 과정에서 flexible하게 searching 수행한다. -> higher diversity
- 네 개의 controllable signals (length, infilling, styles, and parts-of-speech)을 사용한 최초의 controllable zero-shot Image Captioning method 이다.
ConZIC의 전반적인 아키텍쳐는 다음과 같다.
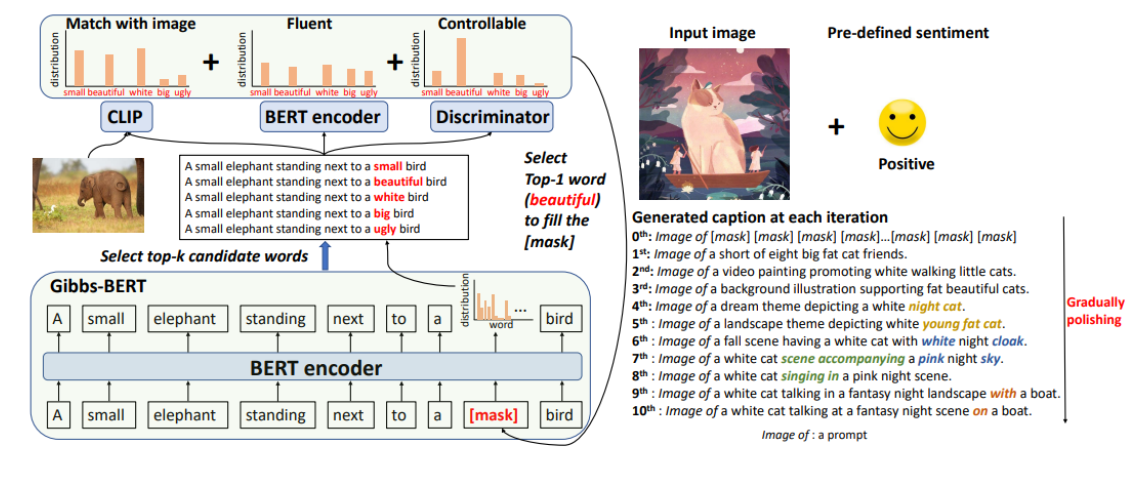
Method
ConZIC은 이미지 I와 Control signal C가 주어졌을 때,
언어 모델의 Likelihood p(x<1,n>|I,C) 를 최대화 하는 x<1,n>를 searching하며 캡셔닝을 수행하고, 목적함수를 수식으로 나타내면 다음과 같다. (According to the Bayes rule,)
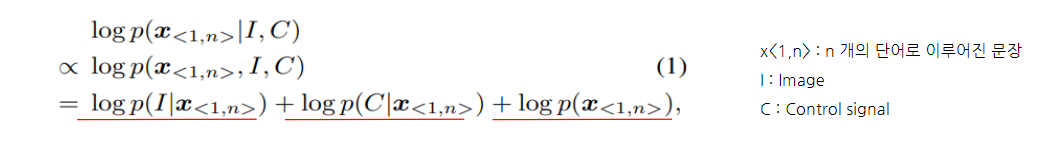
Log likelihood 각각은 1) 자연스러운 문장 생성을 유도하고, 2) image 와 캡션의 유사도를 계산하며, 3) control signal을 만족하는 캡션 생성하도록 유도한다.
1. ConZIC의 Masked Language Model
기존 Autoregressive Generation 방식은 이전까지의 토큰을 고려해 다음 토큰을 autoregressive하게 생성한다. 이는 낮은 다양성과 에러 축적의 가능성이 존재한다. (low diversity, error accumulation)
따라서, Gibbs sampling 과 Masked Language model 을 결합한 'sampling-based LM' 을 새롭게 정의한다.
** Gibbs sampling ?
- MCMC 알고리즘에 기반한 샘플링 방법
: data의 결합분포 p(x<1,n>) 로부터 반복적으로 xi 샘플링하고, 반복을 통해 조건부분포 p(xi|x−i)에 가까운 x를 샘플링한다.
(x−i : xi 제외한 다른 랜덤 변수)- 샘플링 초기에는 x-i에 크게 의존하지만, 충분히 많이 뽑고 난 뒤에는 초기 상태에 관계없이 p에 기반한 표본 수집할 수 있다.
- 또한, Gibbs sampling은 샘플링 순서가 자유롭기 때문에, mode collapse 를 벗어나 더 다양한 캡션 생성을 가능하게 한다.
- Masked LM의 목적함수는 xM 이 [MASK] 토큰 일때, MLM은 다른 단어들 x−M 로부터 xM이 나올 확률 분포를 학습하는 것이 목표이고,
이는 Gibbs sampling에서 p(xi|x−i)를 예측하는 과정과 동일하게 볼 수 있다.
t 시점의 xi 예측하는 과정


2. Image-text matching network
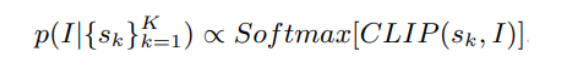
image-text 유사도 반영하기 위해 CLIP matching score CLIP(sk, I) 를 계산한다.
이때 Gibbs-BERT가
1) top-K 후보 단어 선정하고,
2) i 번째 [MASK] token 대신 K개의 후보 단어를 넣고, K개의 후보 문장을 생성한다.
3) 후보 문장들과 이미지I 간의 CLIP 유사도를 구하고, softmax 취해 최종 CLIP matching score를 얻는다.
3. Discriminator for control signal
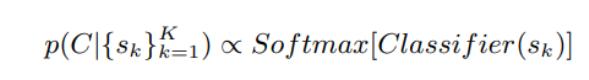
- task 에 맞는 pre-trained classifier를 사용하여 후보 문장에 대한 controllable score 를 구한다.
- length control 같은 특정 controllable task에서는 p(C|x<1,n>) 사용할 필요 없지만, style, part-of-speech와 같은 task에는 Pre-trained Classifier 필요하다.
앞서 언급한 framework1,2,3 에 따라, 최종적인 단어 예측확률은
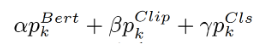
Overall Algorithm
-> 초기 캡션 : "Image of [MASK][MASK] [MASK]..."
-> Gibbs-BERT가 top-K 후보 단어 선정하여 K개의 후보 문장 sk 선별한다.
-> 후보 문장에 대한 text-image score p(I|x<1,n>) & text-control matching score p(C|x<1,n>)를 구한다.
-> 이를 Gibbs-BERT predicted distributions p(xi|x−i) 와 결합해 최종 확률분포 구함 = Final distribution
-> 확률값 가장 높은 xi 선택하는 과정을 매 time step에서 반복한다.
Experiments
1. Standard Image Captioning task
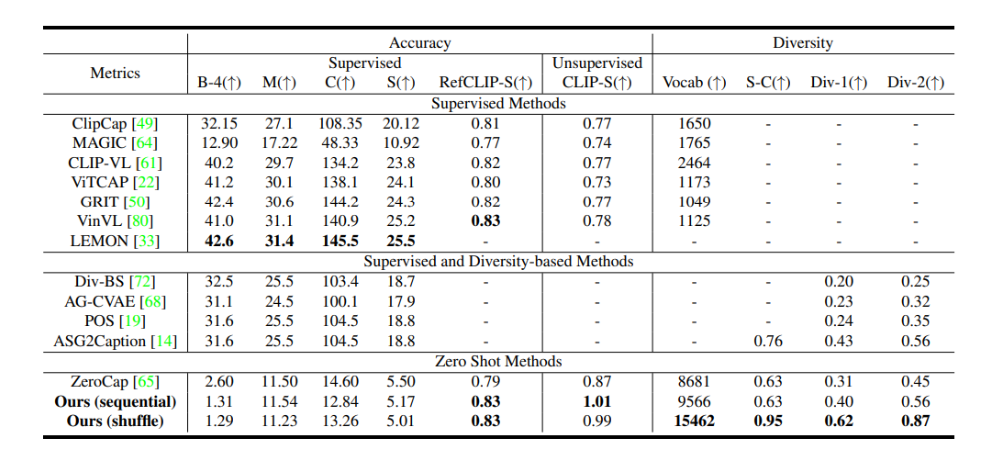
-
BLEU-4, METEOR, CIDEr, SPICE metrics에서 supervised method 보다 성능 좋지 못하다.
이유 : supervised metrics이므로 MSCOCO의 train, test data annotation에서의 유사성이 반영되었기 때문. 즉 train과 test에서 비슷한 캡션 스타일로 인해 domain bias가 생긴다.
=> supervised method는 점수는 높지만 생성된 캡션의 다양성 떨어진다. -
Diversity 측면에서 기존 Diversity-based Methods 보다 큰 차이로 좋은 성능을 보인다.
-
Semantic-related metrics 에서도 좋은 성능을 보인다.
2. Zero-shot performance
zero-shot performance를 측정하기 위해, MSCOCO로 train된 supervised method를 SketchyCOCO caption dataset으로 성능 평가를 진행했다.
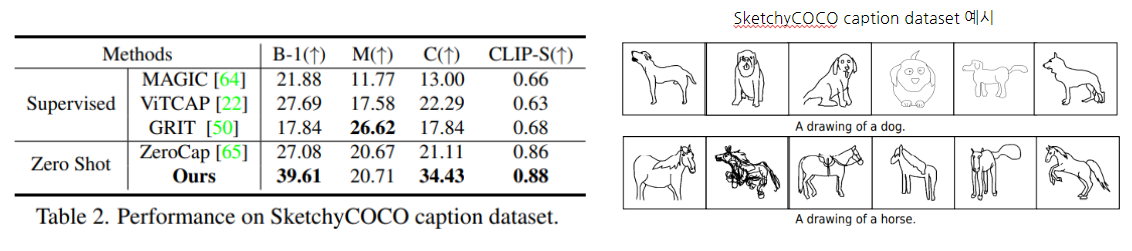
- ConZIC이 Supervised method 보다 나은 성능을 보인다.
이유: Supervised method는 MSCOCO 와 SketchyCOCO 간 domain gap 존재 -> generality 떨어짐 - ConZIC은 ZeroCap 보다도 나은 성능을 보였다.
3. Controllable Image Captioning tasks
다음으로, 네 가지 Controllable tasks에 대한 실험을 진행했다.
Length
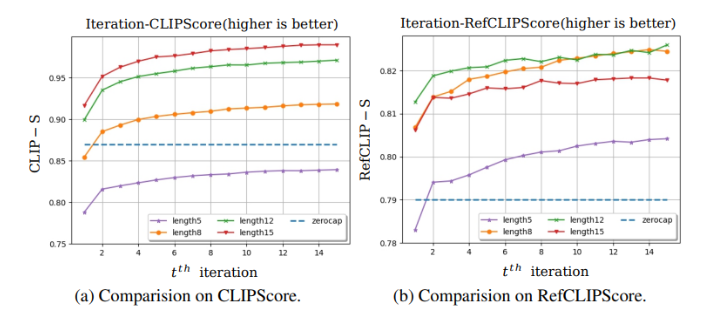
- 캡션 길이 길수록 많은 정보 담고 있어 더 높은 CLIPScore, RefCLIPScore 를 보인다.
- length 12, 8 이 5, 15일 때 보다 나은 RefCLIPScore 를 보인다.
이유 : MSCOCO 캡션 평균 length가 10이므로 생성된 캡션의 length가 10에 가까울 때 reference와의 유사도 더 높게 측정되었다.
Infilling
빈칸 채우기 task에서 image 정보와 고정된 주변 단어 정보를 모두 반영한 결과이다.
ConZIC의 Gibbs-BERT는 bidirectional attention에 기반한 모델이므로 classifier를 추가하지 않고도 task 수행이 가능하다.
( Zerocap은 autoregressive LM 사용하므로 해당 task 수행시 left context 정보만 반영 )
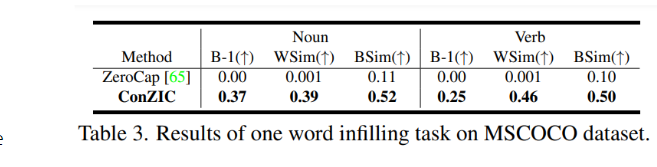
- ConZIC이 Zerocap보다 나은 성능을 보인다.
Parts-of-speech (POS)

- POS tag 템플릿 [ DET ADJ/NOUN NOUN VERB VERB ADV ADP DET ADJ/NOUN NOUN NOUN ]적용 결과, 높은 accuracy 달성했으나, METEOR (M), CIDEr (C), CLIPScore (CLIP-S) 점수는 낮아진 것을 확인할 수 있다.
이유 : 모든 이미지가 POS tags 템플릿에 맞지는 않는다.
Conclusion and future work
Conclusion
- ConZIC은 Masked Language Model과 Gibbs sampling의 관련성을 파악하여 새로운 sampling-based language model인 Gibbs-BERT를 정의했다.
- Bidirectional attention을 통해 생성 순서가 자유롭고, 다양한 캡션 생성이 가능해짐
- 반복적인 sampling을 통해 더 나은 문장을 생성한다.
- 또한, CLIP 기반 image text matching과, pre-trained discriminator를 활용하여 Control signal이 있을 때와 없을 때 모두 인상적인 zero-shot Image Captioning 성능을 보인다.
Future work
- Zerocap, ConZIC과 같은 zero-shot methods는 작은 물체에 대한 캡셔닝 한계가 존재한다. -> zero-shot captioning에 더 많은 연구가 필요해 보임
- Controllable image captioning에 더 적절한 metrics 적용할 필요가 보인다.
