
1. 데이터 리터러시
(1) Data Literacy
데이터를 통해 문제를 정의하고 해결책을 도출하는 종합적 역량
(2) Data Literacy의 핵심 역량
-
이해하기 (Understand)
데이터란 무엇이며, 그것이 문제 해결에 어떤 영향을 미치는지 이해합니다. -
찾기/수집하기 (Find/Obtain)
필요한 데이터를 어디서 찾고 어떻게 수집할지 파악합니다. -
읽기 (Read)
데이터를 해석하고 중요한 정보를 파악하는 과정입니다. -
관리하기 (Manage)
데이터를 체계적으로 정리하고 품질을 관리하는 원칙을 배웁니다. -
활용하기 (Using)
데이터를 전처리하고 분석하여 의미 있는 결과를 도출합니다. -
소통하기 (Communicate)
데이터로 도출된 인사이트를 효과적으로 전달하고 협업합니다.
(3) 데이터 윤리와 책임
데이터를 다룰 때는 단순한 기술적 역량뿐만 아니라 윤리적 고려도 중요합니다. 데이터 활용이 증가하면서 개인정보 보호, 알고리즘 편향성, 데이터 보안 등의 이슈가 부각되고 있습니다.
-
데이터 편향성(Bias): 잘못된 데이터 샘플링 또는 알고리즘 학습으로 인해 특정 그룹에 불리한 결과가 나올 수 있음
-
개인정보 보호(Privacy) : 데이터 수집 과정에서 사용자의 동의 여부 및 보호 조치를 고려해야 함 (예: GDPR, CCPA 등의 규제 준수)
-
데이터 보안(Security) : 해킹이나 유출을 방지하기 위한 암호화, 접근 통제 등의 보안 기법 필요
2. 데이터
(1) Data
이론을 세우는데 기초가 되는 사실이나 자료
- Quantitative (Structed Data) : How many / What kind
정형 데이터 : 수치, 도형 등으로 표현된 데이터 - Qualitative (Unstructed Data) : Why?
비정형 데이터 : 텍스트, 이미지, 오디오, 비디오 등 다양한 형식으로 표현된 데이터
(2) DIKW model
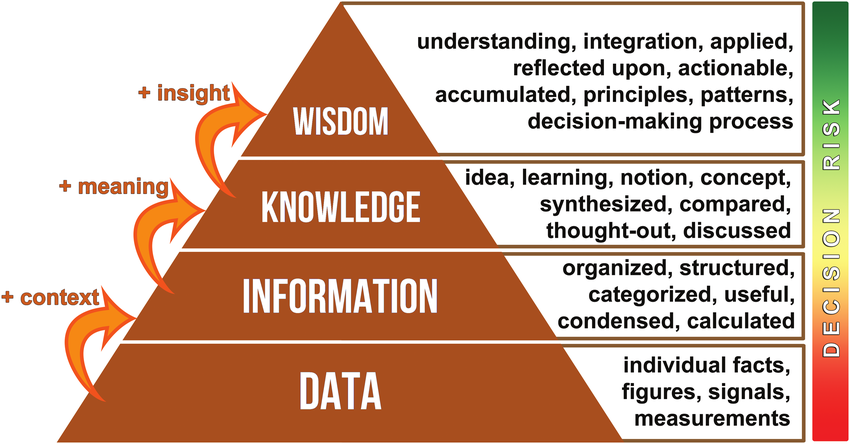
(3) 데이터의 품질 관리
데이터 품질(Data Quality)은 분석의 신뢰성을 결정하는 핵심 요소입니다.
- 정확성(Accuracy) : 데이터가 실제 현실과 얼마나 일치하는가?
- 일관성(Consistency) : 여러 소스에서 동일한 데이터를 가져왔을 때 동일한 값을 유지하는가?
- 완전성(Completeness) : 누락된 값(Missing Values)이 없는가?
- 적시성(Timeliness) : 최신 데이터를 유지하는가?
- 유효성(Validity) : 기대되는 형식, 범위, 조건을 충족하는가?
이러한 품질 지표를 관리하기 위해 데이터 정제 및 모니터링이 필요하며, ETL(Extract-Transform-Load) 과정에서 품질 기준을 적용할 수 있습니다.
3. 인공지능
(1) Data와 AI의 관계
인공지능(Artificial Intelligence)
인간의 지능적 행동을 모방하는 컴퓨터 시스템 또는 기계
데이터는 인공지능의 원료이며, 인공지능은 머신러닝과 딥러닝을 포괄하는 개념
(2) Data 중심 최적 행동 결정
-
정의: 일정한 데이터의 패턴을 학습하여 특정 의사결정 규칙을 만들어 최적의 행동을 결정하는 방법
-
특징:
- 데이터의 패턴과 통계적 특성에 기반해 규칙을 도출
- 과거 데이터를 중시하며, 사람이 사전에 정의한 규칙 기반 접근이 많음
- 통계적 회귀, 시뮬레이션, 최적화 기법 등이 사용
-
예시:
- 공급망 관리에서 과거 판매 데이터를 기반으로 수요를 예측해 최적의 재고 수준을 결정
- 마케팅에서 고객 구매 패턴을 분석해 할인 정책을 설정
→ 핵심: 데이터의 과거 패턴과 규칙 기반 모델을 통해 미래 행동을 예측하고 의사결정을 내린다.
(3) 알고리즘 중심 최적 행동 결정
-
정의: 알고리즘을 사용해 입력 데이터를 자동으로 학습하고, 이를 기반으로 최적의 의사결정 기준(모델)을 도출하는 방식
-
특징:
- 알고리즘이 데이터를 입력받아 자동으로 학습하는 과정에서 의사결정 기준을 생성
- 데이터의 복잡한 관계를 학습하기 위해 기계 학습(머신러닝)이나 딥러닝 모델이 사용
- 규칙을 사람이 명시적으로 정의할 필요 없이, 알고리즘이 반복적인 학습을 통해 최적의 기준을 스스로 학습
-
예시:
- 자율주행 차량이 센서 데이터를 받아 주변 환경을 인식하고 행동 결정
- Netflix나 Amazon의 추천 시스템에서 사용자 선호도를 기반으로 맞춤 콘텐츠 추천
- 금융에서 신용 점수를 바탕으로 대출 승인 여부를 판단하는 모델
→ 핵심: 알고리즘이 데이터를 통해 학습하여 스스로 의사결정 기준을 만들고 최적의 행동을 제시
💡 정리
- Data 중심 의사결정은 명확한 패턴이나 규칙이 있는 문제에 적합
- 알고리즘 중심 의사결정은 복잡한 데이터 관계를 학습해야 하는 상황에 효과적
(4) AI 모델의 성능 평가 지표
머신러닝과 딥러닝 모델을 최적화하려면 적절한 평가 지표를 사용
- 정확도(Accuracy) : 전체 데이터 중 올바르게 예측한 비율 (하지만 불균형 데이터셋에서는 신뢰하기 어려움)
- 정밀도(Precision) : 모델이 긍정(Positive)으로 예측한 것 중 실제 긍정인 비율 (False Positive 방지)
- 재현율(Recall) : 실제 긍정인 데이터 중 모델이 긍정으로 예측한 비율 (False Negative 방지)
- F1 Score : 정밀도와 재현율의 조화 평균 (균형 잡힌 평가를 위해 활용)
- AUC-ROC Curve: 모델의 분류 능력을 평가하는 곡선
이러한 지표를 활용해 모델을 평가하고 개선하는 과정이 중요
4. 데이터 분석 방법론
Big Data 과학 방법론 (6단계)
① 목표 설정
: 분석 목적, 이유, 비지니스에 미치는 영향, 예상 결과 등 상세한 설정
② 데이터 수집
: 기존 데이터 활용 (공공 데이터 포털, 국가 통계 포털) 및 직접 수집 (크롤링)
③ 데이터 준비
: 데이터 정제, 전처리 및 변환
④ 데이터 탐색
⑤ 데이터 모델링
: 다양한 기법으로 데이터 분석
⑥ 활용 (결과 공유 및 자동화)
: 정책 수립 및 시스템에 반영
AutoML과 MLOps 활용
- AutoML(Auto Machine Learning) : 모델 선택, 하이퍼파라미터 튜닝, 피처 엔지니어링 등을 자동화하여 분석 과정을 효율적으로 수행
- MLOps(Machine Learning Operations) : 데이터 수집부터 모델 배포 및 유지보수까지의 전 과정을 자동화하는 엔지니어링 기법
5. 데이터 엔지니어링
(1) DataBase
전자적으로 저장되고 체계적인 데이터 모음
(2) DBMS (DataBase Management Syetem)
이용자가 쉽게 데이터 베이스를 구축하고 유힐 수 있도록 하는 소프트웨어
- 관계형
- 계층형
- 네트워크형
- 객제지향형
- NoSQL
(3) SQL (Structed Query Language)
관계형 데이터베이스에서 데이터를 관리하고 조작하는데 사용되는 표준화된 프로그래밍 언어
- DDL (데이터 정의 Definition 언어)
- DML (데이터 조작 Manipulation 언어)
- DCL (데이터 제어 Control 언어)
(4) 데이터 처리 기술 & 프로세스
- Extract : 데이터 추출
- Transform : 데이터 변환
- Load : 데이터 저장 및 불러오기
(5) 데이터 파이프라인과 데이터 웨어하우스
- 데이터 파이프라인(Data Pipeline) : 데이터를 실시간 또는 배치(batch) 방식으로 처리하여 분석이 가능하도록 가공하는 자동화 프로세스
- 데이터 웨어하우스(Data Warehouse) : 여러 데이터 소스를 통합하여 저장하는 대규모 데이터 저장소 (예: Google BigQuery, Amazon Redshift, Snowflake)
6. 데이터 분석 보고서
(1) 보고서 작성 항목
-
주제 선정 및 배경
주제 선정 사유 (동기, 문제점) 기입 -
분석 내용 및 결과
자료 활용 우수성 : 연구 접근 방법, 활용 데이터 요약 -
분석 결과 도출을 위한 분석 방법 기재
자료 분석의 차별성 : 전처리 내용 등 기입 -
분석 결과 및 활용 방향
결과의 독창성 : 시사점, 정책 제안 등 핵심내용을 중심으로 분석 결과 기술
(2) 보고서 작성 전략
- 가용 데이터 고려
- UseCase 탐색 : 기존 솔루션 활용 및 과거 유사 사례 분석
- 위험요소 고려 및 사전 계획 수립
(3) 효과적인 데이터 시각화 기법
- 대시보드(Dashboard) 활용 : Power BI, Tableau, Looker 등을 사용해 데이터를 직관적으로 시각화
- 적절한 차트 유형 선택
- 시계열 데이터 → 라인 차트
- 카테고리별 비교 → 바 차트
- 비율 분석 → 파이 차트
- 분포 확인 → 히스토그램, 박스 플롯
- 스토리텔링 기법 적용
- 데이터 인사이트를 스토리로 풀어서 전달
- 핵심 메시지를 강조하고 불필요한 정보 배제
