
1. 통계의 개념
- 통계학이란? 과학적 방법에 의해 자료를 수집하고 목적에 맞는 적절한 방법에 의해 정리, 분석하는 학문
(1) 기술통계 & 추론 통계
-
기술 통계 (Descriptive Statistics)
- 자료의 특성을 표, 그림, 통계량 등을 사용하여 쉽게 파악할 수 있도록 정리, 요약하는 방법을 다루는 분야
- 평균, 중앙값, 최빈값, 분산, 표준편차, 백분위수(Percentile)
-
추론 통계 (Inferential Statistics)
- 관찰 불가능한 모집단의 여러 특성에 대해 관찰 가능한 표본 자료의 정보를 분석하여 과학적으로 추론하는 방법을 다루는 분야
- 불확실성과 오류를 고려하여 통계적 추론을 수행
- 합리적인 의사결정을 위한 근거를 제공하는 것이 목적
-
기술통계는 데이터 샘플에 대하여 요약, 시각화하는 것을 의미하며 샘플의 특징을 파악하는 관점인 반면,
추론통계는 샘플을 통해서 가설 검정 등을 통해 모집단을 추론하는것
(2) 모집단과 표본
- 모집단(Population) : 관심의 대상이 되는 개체의 전체 집합, 수집 가능한 모든 관측 값
- 표본(Sample) : 모집단에서 추출된 관측 값의 부분 집합
(3) 통계적 가설검정 (Statistical Hypothesis Testing)
통계적 가설검정은 표본 데이터를 이용하여 모집단에 대한 주장이 참인지 검증하는 과정입니다.
- 귀무가설 (Null Hypothesis, H₀): 검정하고자 하는 기본 가설로, 보통 "차이가 없다"는 가정을 의미
- 대립가설 (Alternative Hypothesis, H₁): 귀무가설을 기각할 경우 채택하는 가설로, "차이가 있다"는 의미
- 유의수준 (Significance Level, α): 귀무가설을 기각하는 기준값으로, 일반적으로 0.05(5%) 사용
- p-value: 귀무가설이 참이라는 가정하에서 현재 데이터를 얻을 확률. 일반적으로 p < 0.05이면 귀무가설을 기각
(4) 주요 가설검정 기법
- Z-검정(Z-test): 모집단의 분산이 알려진 경우 평균 비교
- t-검정(t-test): 모집단의 분산이 알려지지 않은 경우 평균 비교
- 카이제곱 검정(χ²-test): 범주형 데이터 간의 독립성 검정
- ANOVA(분산분석): 두 개 이상의 그룹 간 평균 차이를 비교
2. 확률과 확률 분포
(1) 확률 변수와 분포함수
- 표본공간 : 모든 가능한 사건의 결과를 포함하는 집합 ( )
- 확률변수(Randon Variable) : 표본공간에서 특정 값으로 변환되는 함수 ( S X,Y,Z )
- 이산형 확률변수 : 확률변수가 취할 수 있는 모든 값은 하나씩 셀 수 있으며, 모두 유한개 또는 가산무한개인 경우
- 연속형 확률변수 : 주어진 구간에서 모든 값을 취할 수 있어 그 값의 수가 무한개인 경우
- 확률분포(Probability Distribution) 또는 분포함수(Distribution Function) : 확률변수 가 취할 수 있는 값 와 확률을 대응시키는 관계
(2) 이산형 확률변수와 확률질량함수(Probability Mass Function, PMF)
- 확률변수가 X가 이산형인 경우 X가 취할 수 있는 값 x1, x2,...의 각각에 대하여 확률을 대응시켜주는 관계를 X의 확률질량함수라고 하며 p(x)로 표기
- 모든 i에 대해
- 모든 i에 대한 확률의 합은 1 →
(3) 연속형 확률변수와 확률밀도함수(Probability Density Function, PDF)
- 확률변수가 가 연속형인 경우 가 가질 수 있는 구간 위에서의 함수가 가다음을 만족할 때, 이를 의 확률밀도함수라고 함 →
- 모든 a,b에 대해
- 특정 값이 될 확률은 0, 전체 범위에 대한 확률은 1
→ ,
(4) 누적분포함수(Cumulative Distribution Function, CDF)
- 확률밀도함수의 그림이 아래와 같이 주어졌을 때 f(x)는 x값에 대한 확률 밀도 함수의 값 자체가 되고,
F(x)는 인 모든 X에 대한 f(x)의 적분 값이 됨
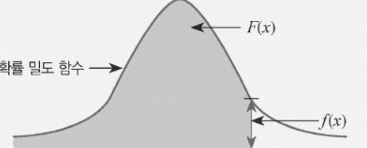
(5) 베이지안 확률과 신뢰 구간
-
베이지안 확률 (Bayesian Probability)
베이지안 확률은 사전 정보(Prior)와 새로운 데이터(Evidence)를 결합하여 사후 확률(Posterior)을 갱신하는 방식 -
베이즈 정리(Bayes’ Theorem)
- ( P(A) ) : 사건 A의 사전 확률
- ( P(B | A) ) : 사건 A가 주어졌을 때 사건 B가 일어날 확률
- ( P(B) ) : 사건 B가 발생할 전체 확률

hyeeun-techlog