
1. 결측치(Null, NaN, NA) 처리
-
결측치 처리는 대표적으로,
- 결측치 제거
- 평균값(mean), 중앙값(median), 빈도값(mode), 0으로 대체
- 예측모델을 이용하여 대체
하는 방식이 주로 이루어짐 -
가장 쉽고 좋은 방법은 결측치가 포함된 행 또는 열을 삭제하는 것
- 데이터가 많은 경우에만 사용가능하며, 데이터의 수가 충분하지 않은 경우 잘 사용하지 않음
-
결측치는 사전에 발생하지 않도록 조치하는 것이 좋음
-
결측치를 처리할 경우 도메인지식은 필수적이며, 결측치를 다른 값으로 대체할 경우 어떠한 값으로 할지에 대한 적절한 의사결정이 필요함
-
Pandas의 경우 누락된 데이터를 나타내기 위해 np.nan이라는 값을 사용하며 계산에 포함되지 안흠
- Pandas의 경우 Null과 NA를 모두 NaN 형식으로 처리
- 데이터가 NaN인 경우
isna또는notna함수를 통해서만 비교 가능 - 결측치를 삭제 :
dropna - 결측치를 치환 :
fillna(<대체값>)
# 난수를 생성하여 음수인 경우 NaN, 양수인 경우 원래값을 가지도록 데이터프레임 생성
np.random.seed(0)
df = pd.DataFrame(np.random.randn(5,5), columns = ['A', 'B', 'C', 'D', 'E'])
df = df[df>0]
df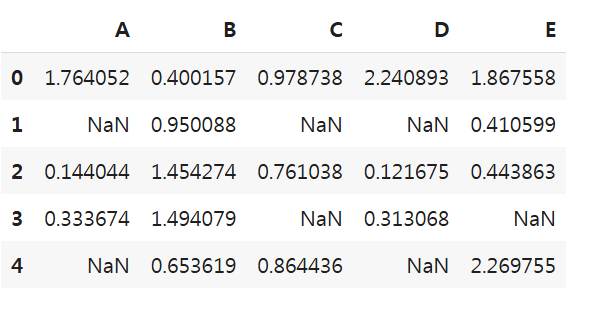
(1) isna(), isnull()
- Series 또는 DataFrame의 요소가 NaN과 같으면 True, 다르면 False 결과를 반환
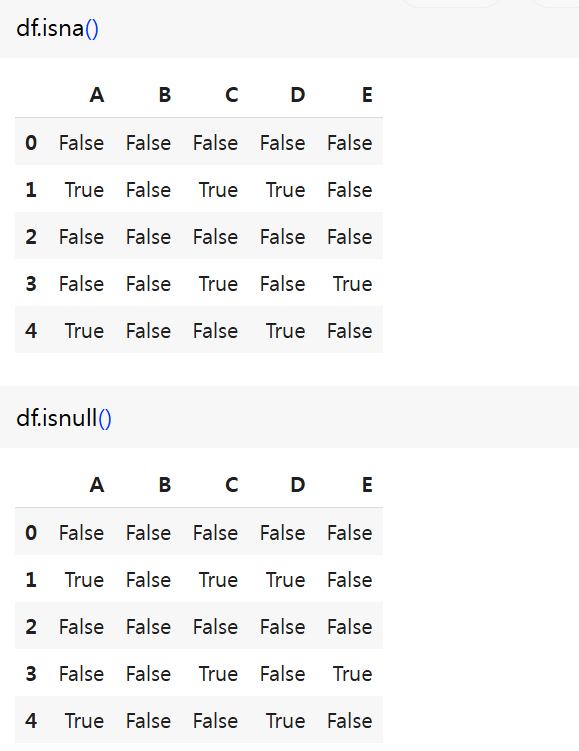
(2) notna(), notnull()
- Series 또는 DataFrame의 요소가 NaN과 같지 않으면 True, 같으면 False 결과를 반환
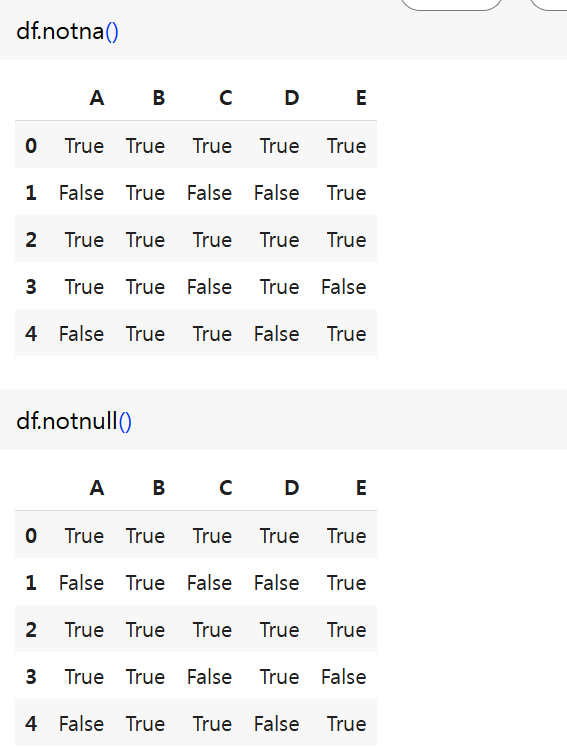
(3) 결측치 개수
- NaN을 비교하는 함수와 행 또는 열의 합을 sum함수를 이용하여 행별 또는 열별 결측치의 개수 계산 가능
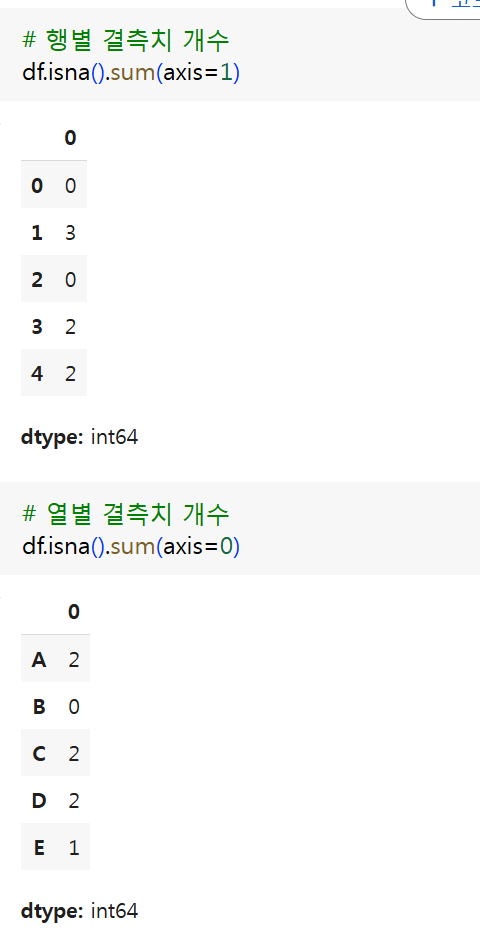
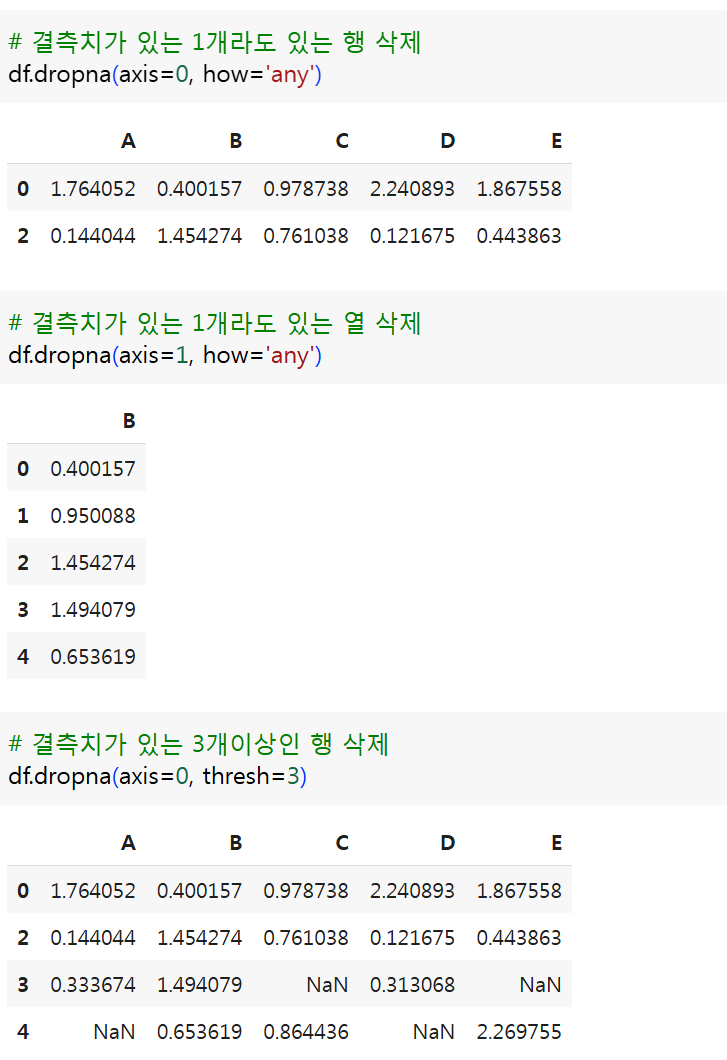
(4) dropna(axis, how, thresh, inplace) 결측치 삭제
- 결측치를 삭제
axis: 행 또는 열의 결측치를 삭제how: 삭제방법 설정any: 1개라도 NaN이 존재하는 행 또는 열을 삭제(기본값)all: 모든 NaN인 행 또는 열을 삭제
thresh: 삭제기준 설정- NaN가 아닌 데이터의 최소개수를 지정
inplace: 원본데이터 변경 여부 지정
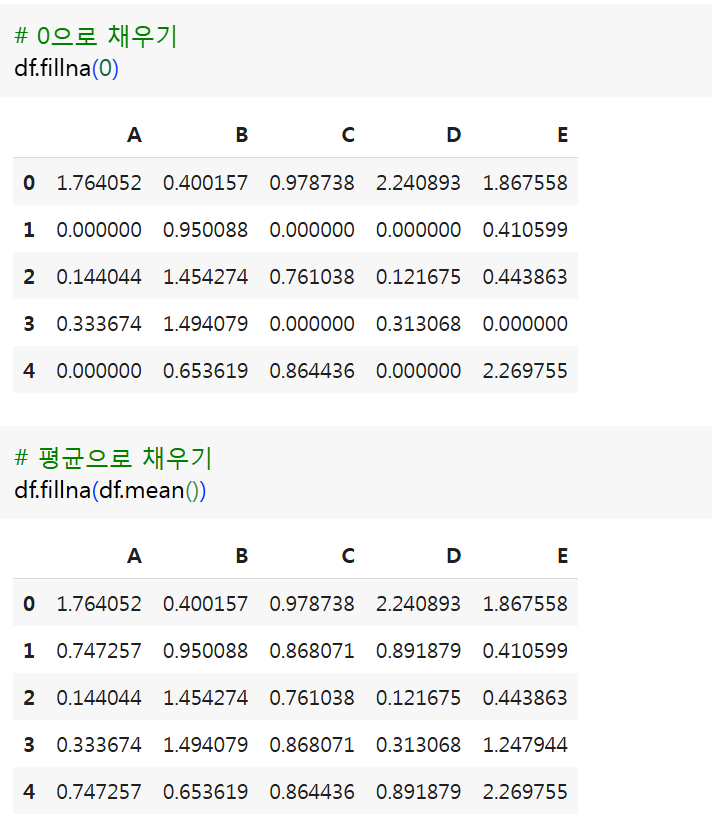
(5) fillna(value, method, inplace) 결측치 대체
- 결측치값을 치환
- 만약 1개의 값이 지정된 경우 모든 결측치를 해당 값으로 치환
- NaN을 제외한 각 컬럼의 대체값을 계산 후 각 컬럼의 평균, 중앙값, 최빈값으로 결측치 대체
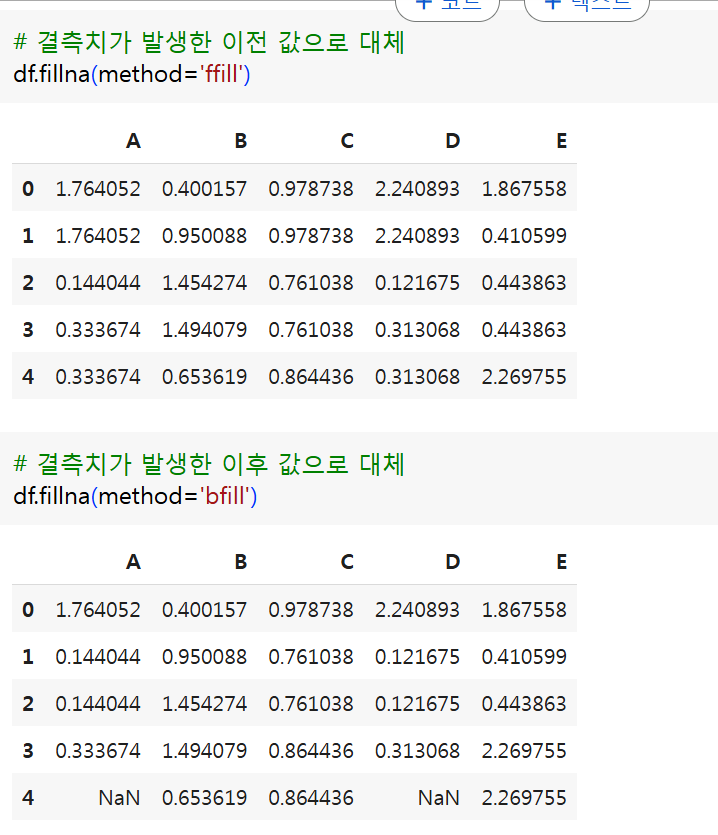
- 시계열 데이터의 경우 보간방법(method)을 설정할 수 있음
ffill: 결측치가 발생한 이전 값으로 대체bfill: 결측치가 발생한 이후 값으로 대체
2.Grouping
- 그룹분석은 자료를 집단별로 나누어 그룹 함수를 적용한 분석 방법
- 빈도 분석이 그룹별 빈도만을 산출하는 것에 비하여 그룹분석은 빈도는 물로 그룹별 특정값에 대한 합계, 평균, 표준편차, 중앙값, 최대값, 최소값 등과 같은 결과를 산출
groupby함수를 이용하여 그룹별 집계 결과를 계산groupby는 데이터를 그룹별로 분할하고(Splitting), 각 그룹별로 집계함수를 적용(Applying) 후 결과를 하나로 합친(Combining) 결과를 반환함- 그룹기준, 집계대상, 집계방법을 지정
groupby는 다양한 형태로 사용가능함
# 그룹기준이 1개인 경우
dataframe.groupby(그룹기준)
# 그룹기준이 N개인 경우
dataframe.groupby([그룹기준1,..., 그룹기준N])
# 집계대상이 1개인 경우
dataframe.groupby(그룹기준)[집계대상]
# 집계대상이 N인경우
dataframe.groupby(그룹기준)[[집계대상1,...,집계대상N]]
# 집계함수가 1개인 경우
dataframe.groupby(그룹기준)[집계대상].집계함수()
# 집계함수가 N개인 겨우
dataframe.groupby(그룹기준).agg([집계함수1,...,집계함수N])- 1개를 지정하는 경우 해당 이름(주로 컬럼명)을 지정하고, 여러개를 지정하고 싶은 경우 이름을 묶어서 저장함
df = pd.DataFrame({
'X1': ['A', 'A', 'A', 'B', 'B', 'B', 'C', 'C', 'C'],
'X2': [3, 1, 0, 1, 7, 3, 2, 1, 3],
'X3': [1, 2, 5, 6, 2, 3, 4, 1, 2]
})
df| X1 | X2 | X3 |
|---|---|---|
| A | 3 | 1 |
| A | 1 | 2 |
| A | 0 | 5 |
| B | 1 | 6 |
| B | 7 | 2 |
| B | 3 | 3 |
| C | 2 | 4 |
| C | 1 | 1 |
| C | 3 | 2 |


3.Pivoting
- Excel의 피벗테이블기능을 동일하게 Pandas에서 사용가능
- 데이터를 보다 빠르고 쉽게 분석 가능
- 행, 열 방향으로 필드를 재배치해 데이터를 한눈에 보기가 용이함
- 행으로만 지정가능한 groupby와 다르게 Pivot의 경우 열로도 지정이 가능함
pivot_table(values, index, columns, aggfunc, fill_value)values: 집계하려는 열의 Label 혹은 Label 리스트index: 피벗테이블 행의 그룹으로 묶을 열의 Label이나 그룹 키columns: 피벗테이블 열의 그룹으로 묶을 열의 Label이나 그룹 키aggfunc: 집계함수나 함수리스트 (기본값은 mean)fill_value: 누락된값의 대체값
df['D'] = ['X', 'X', 'Y', 'X', 'Y', 'X', 'X', 'Y', 'X']
df| X1 | X2 | X3 | D |
|---|---|---|---|
| A | 3 | 1 | X |
| A | 1 | 2 | X |
| A | 0 | 5 | Y |
| B | 1 | 6 | X |
| B | 7 | 2 | Y |
| B | 3 | 3 | X |
| C | 2 | 4 | X |
| C | 1 | 1 | Y |
| C | 3 | 2 | X |
# 행을 x1으로, 열을 D로 하는 그룹의 'x2', 'x3'컬럼의 합계
df.pivot_table(index='X1', columns='D', values=['X2','X3'], aggfunc='sum')
4. Merge - 연결
- 분석의 규모가 커지게 되면 여러개의 데이터 테이블을 이용
- 하나의 테이블에 모든 데이터를 기록하는 것은 좋지 않기 때문
- 데이터분석을 위해서는 여러개로 분할된 데이터 테이블을 하나로 만들어서 분석하는 것이 중요함
- Pandas의 경우 DataFrame과 DataFrame을 연결 또는 병합할 수 있음
concat(): 단순히 DataFrame을 연결(인덱스기준)merge(): 특정한 기준으로 DataFrame을 연결(열의 값 기준)
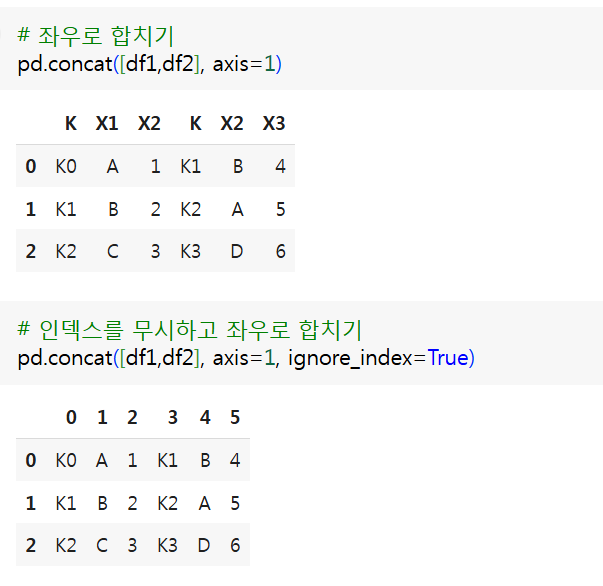
(1) concat
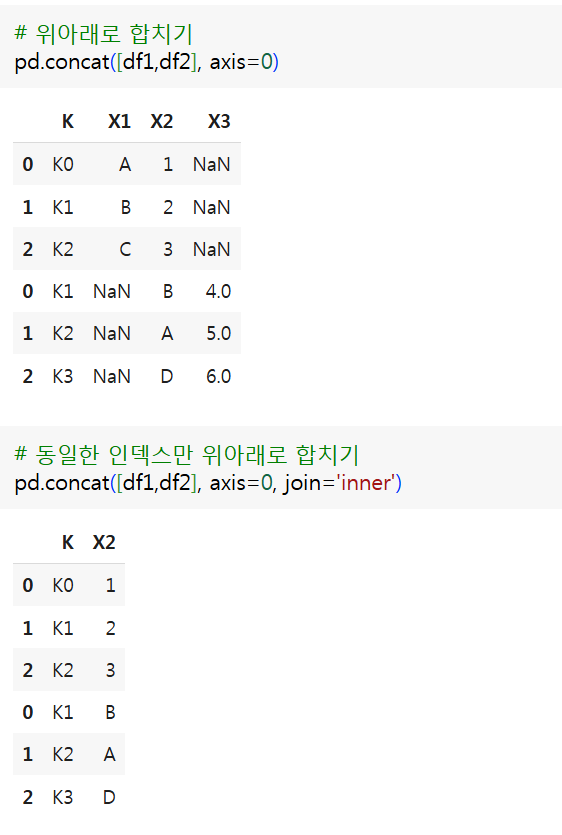
- 단순히 DataFrame을 연결하는 것으로 인덱스값이 중복될 수 있음
pandas.concat([dataframe,...dataframe], axis, join, ignore_index)axis- 상하연결(axis=0)
- 좌우연결(axis=1)
join- 동일한 이름을 가지는 인덱스가 없는 NaN값으로 대체(join='outer')(기본값)
- 동일한 이름을 가지는 인덱스만 연결(join='inner')
ignore_index- 기존의 인덱스를 무시하고 연결(ignore=True)
- df1
| K | X1 | X2 |
|---|---|---|
| K0 | A | 1 |
| K1 | B | 2 |
| K2 | C | 3 |
- df2
| K | X2 | X3 |
|---|---|---|
| K1 | B | 4 |
| K2 | A | 5 |
| K3 | D | 6 |
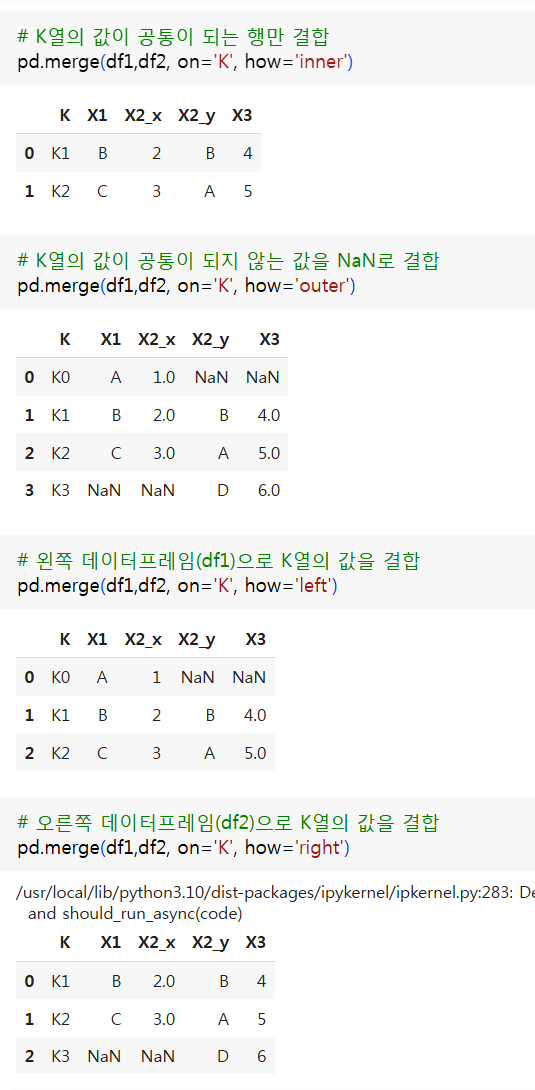
(2) merge
- 두 DataFrame의 공통 열 혹은 인덱스를 기준으로 두 DataFrame을 병합
pandas.merge(on, how)on: 기준이 되는 열, 행의 데이터를 키(Key)라고 하며, 병합기준이 될 컬럼을 on으로 설정how: 결합 방법inner: 키가 중복되어 존재하는 경우만 결합outer: 동일한 키가 없는 경우 NaN으로 대체하여 결합left: 왼쪽 DataFrame의 키를 기준으로 결합right: 오른쪽 DataFrame의 키를 기준으로 결합

hyeeun-techlog