1. 데이터 파악
한 백화점에서 명품을 구매하는 고객들의 속성과 구매데이터를 군집화(clustering)해보고, 명품을 구매하는 고객들에는 어떤 고객군이 있는지 분석합니다.
데이터1: 고객정보
(id, Weekdays주말방문수, Weekends주중방문수, Age나이, Parking time주차시간, 성별)
데이터2: 구매정보
(id, category, sales, amount)공통으로 id가 있기 때문에, id기준으로 합쳐주면 좋을 것 같습니다.
군집화 방법
1. k-means Clustering :
- 변수간의 거리를 기준
2. 군집변수 :
- 연령
- 평균 주차 시간
- 주중 내방 일수
- 주말 내방 일수
- 명품 구매 금액
- 비명품 구매 금액
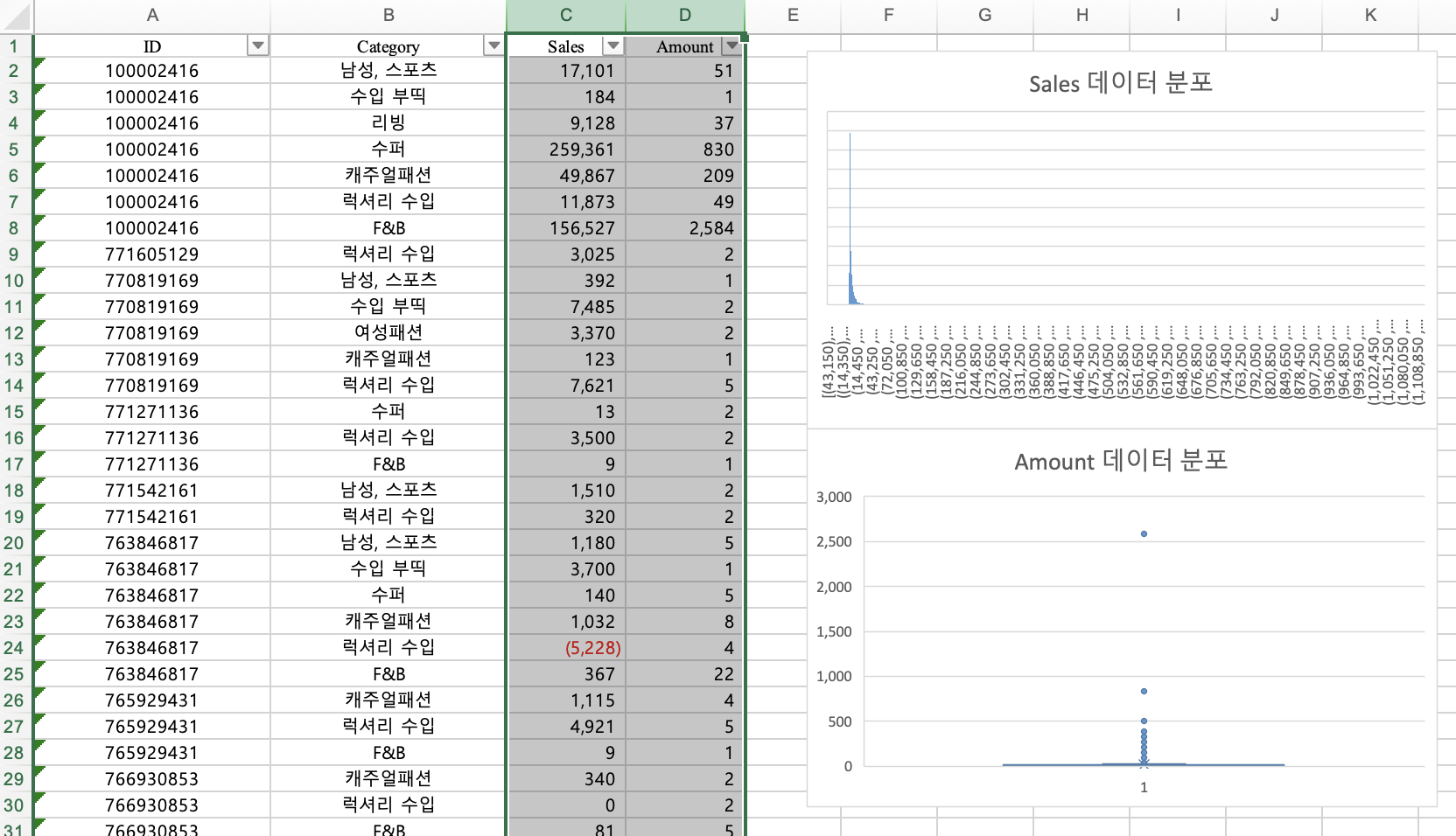
2. 전처리
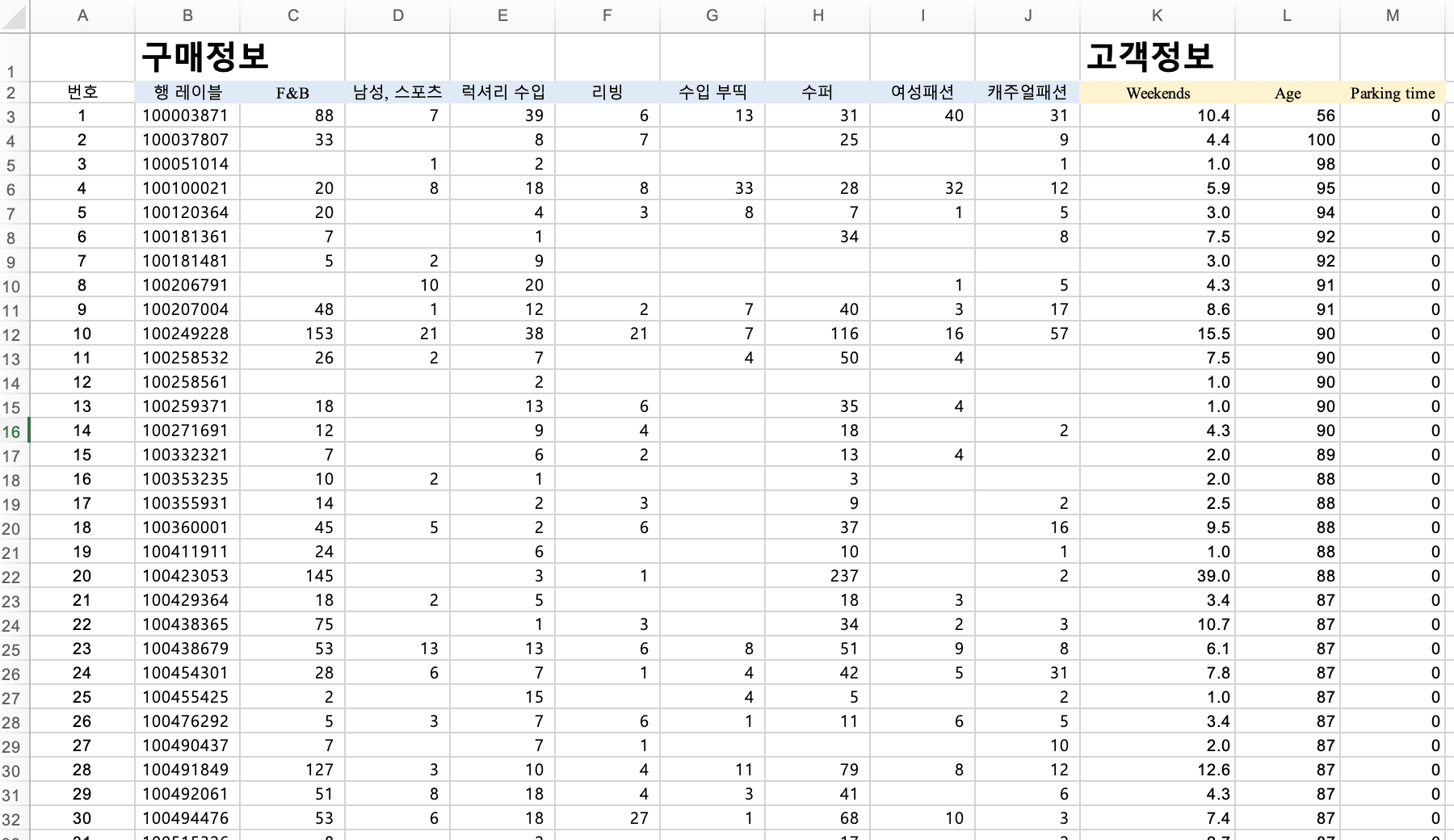
두 데이터 병합
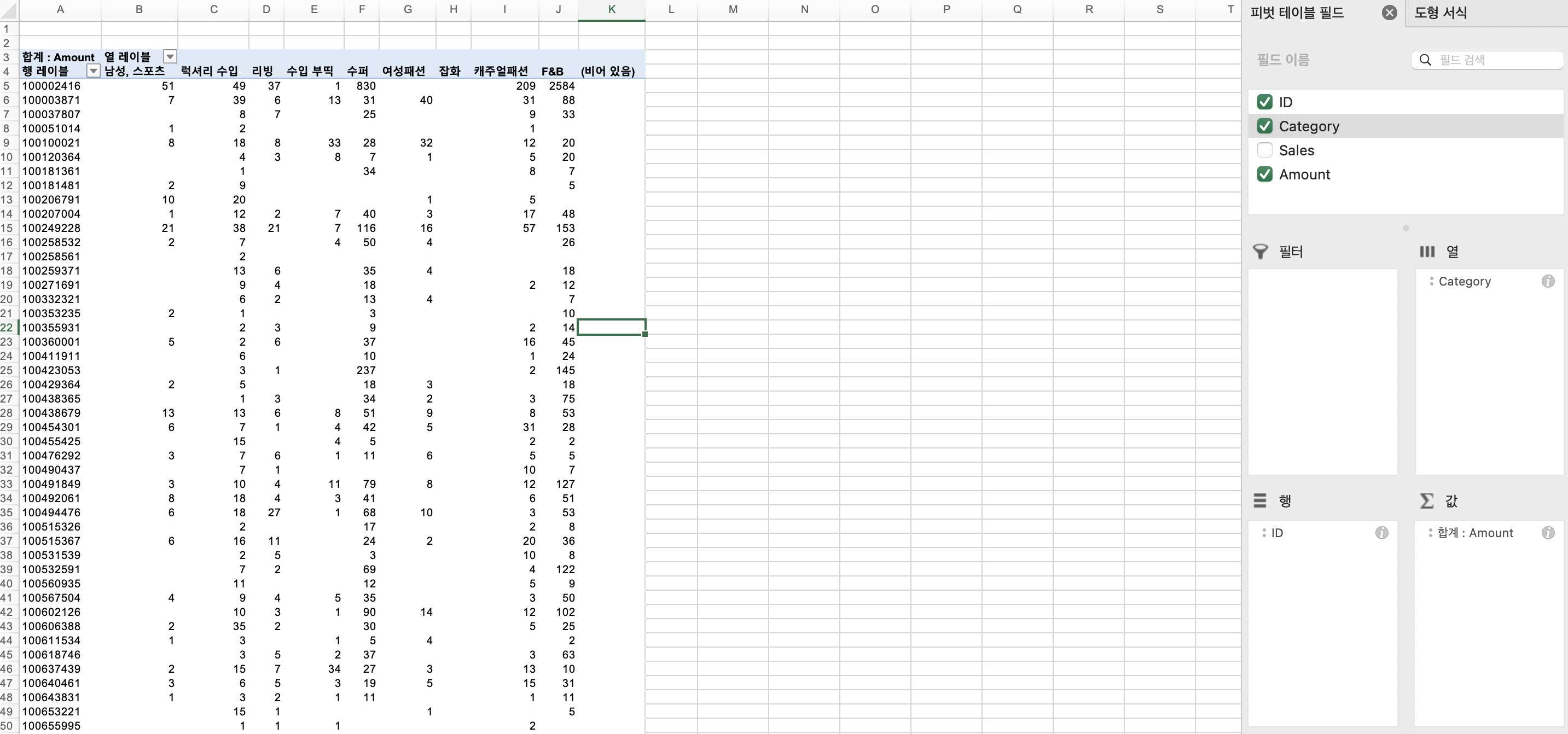
일단 구매 데이터를 피벗 테이블로 만들어 줍니다.
고객(id)별 각 카테고리에 대한 구매금액을 만들어주겠습니다.
- 행 : id
- 열 : category
- 값 : Amount 합계
- 총합계 제외
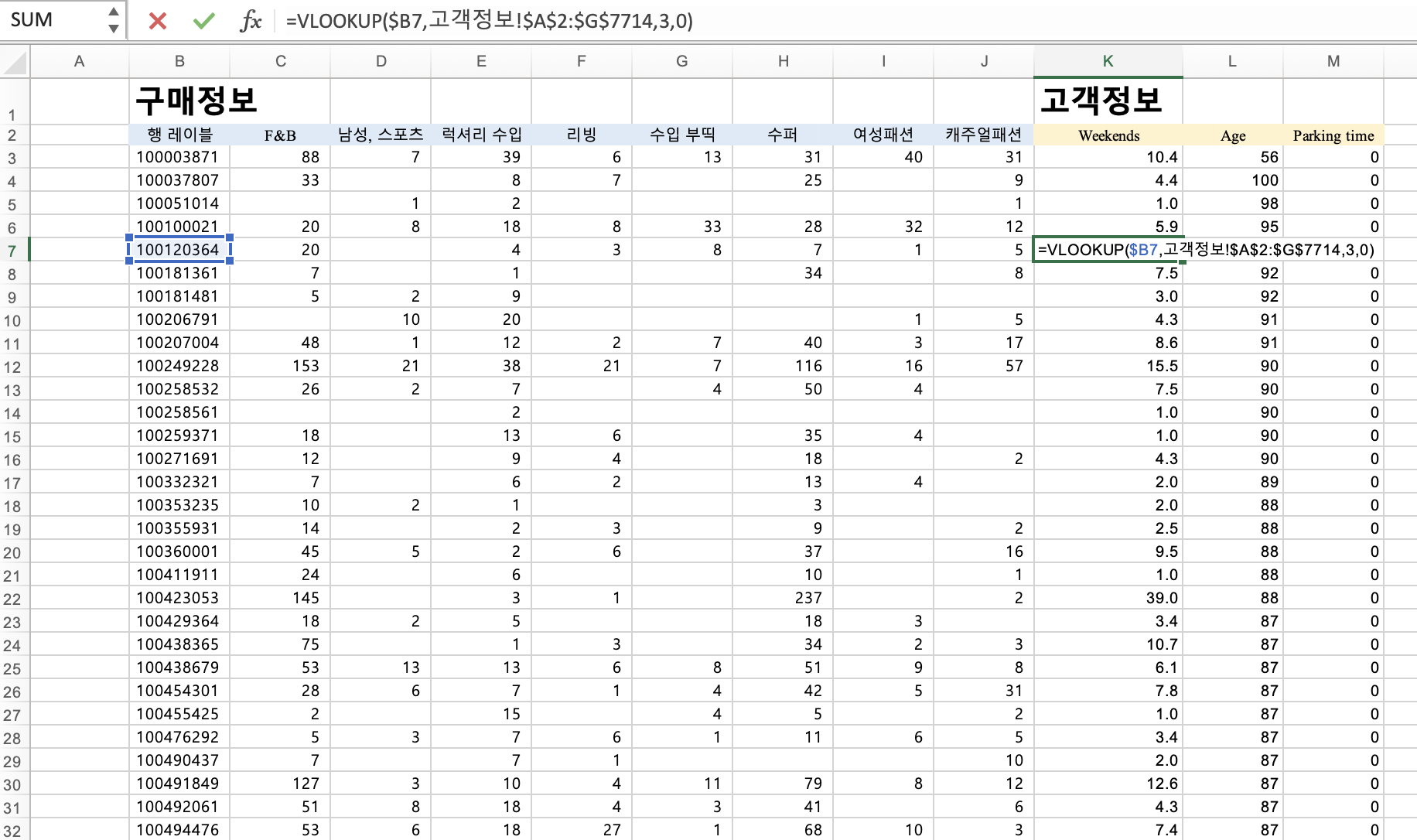
그리고 값 복사 붙혀넣기를 새로운 시트에 해줍니다.
구매정보 id를 기준으로 vlookup을 하여 고객정보에서 불러오고 싶은 컬럼명을 생성해줍니다.
=vlookup(기준셀, 찾는범위, 범위내 몇번째열, False
=VLOOKUP($기준셀,$찾는$범위:$찾는$범위, 숫자, FALSE)
그리고 번호칸 열을 추가하겠습니다.
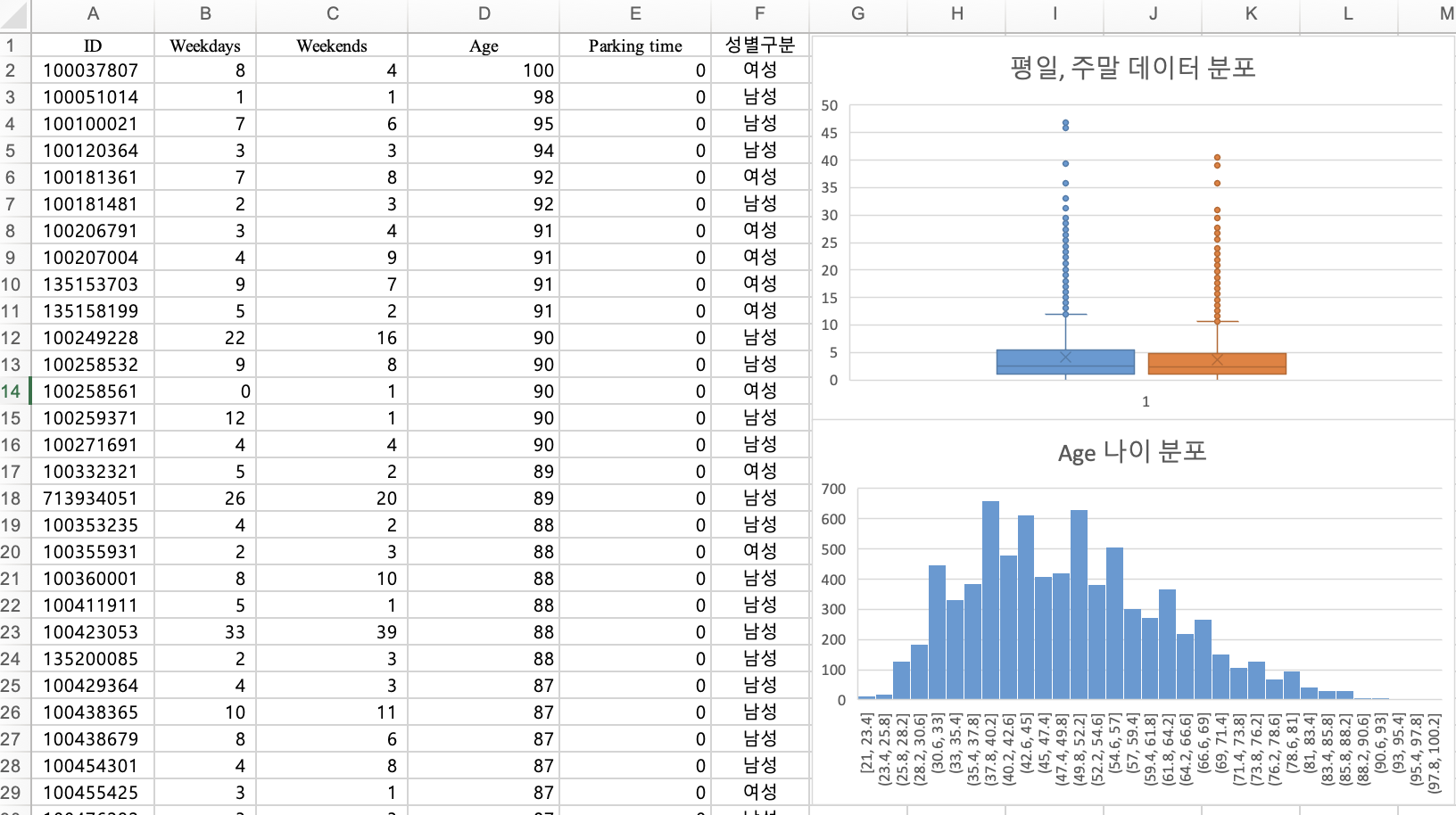
3. 전처리 (표준화)
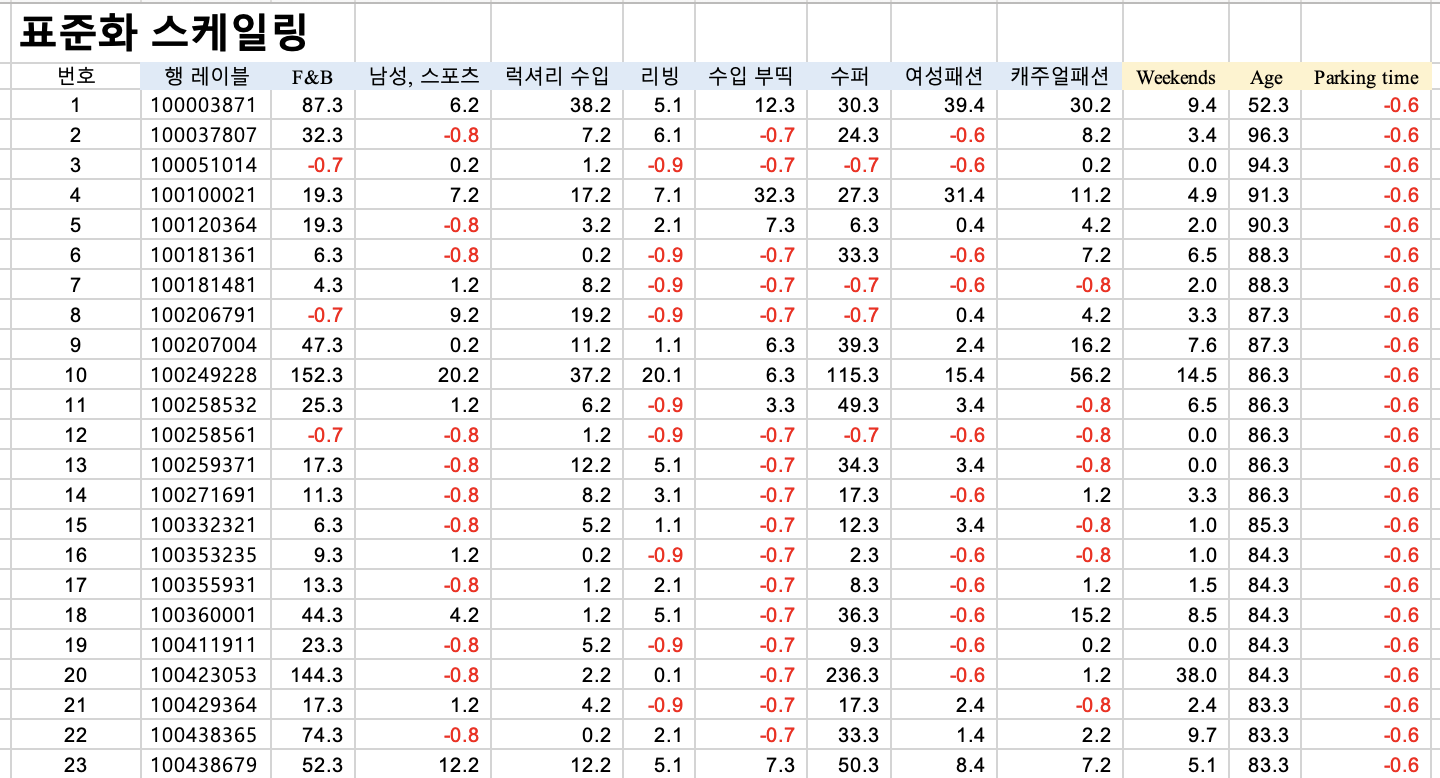
각 컬럼별 수치가 다르기때문에, 스케일링이 필요합니다.
평균, 표준편차 구하기
각 컬럼별 평균과 표준편차를 구해줍니다.
평균 =average()
표준편차=stdev.s()
표준화 스케일링
=실제값 - 평균 / 표준편차
=실제값 - 평$균 / 표준$편차
=C3-P$3/P$4
숫자 값들에만 고정시켜줍니다.
그래야 복사붙혀넣기 할때 적용되니깐요.

4. 군집화(clustering)
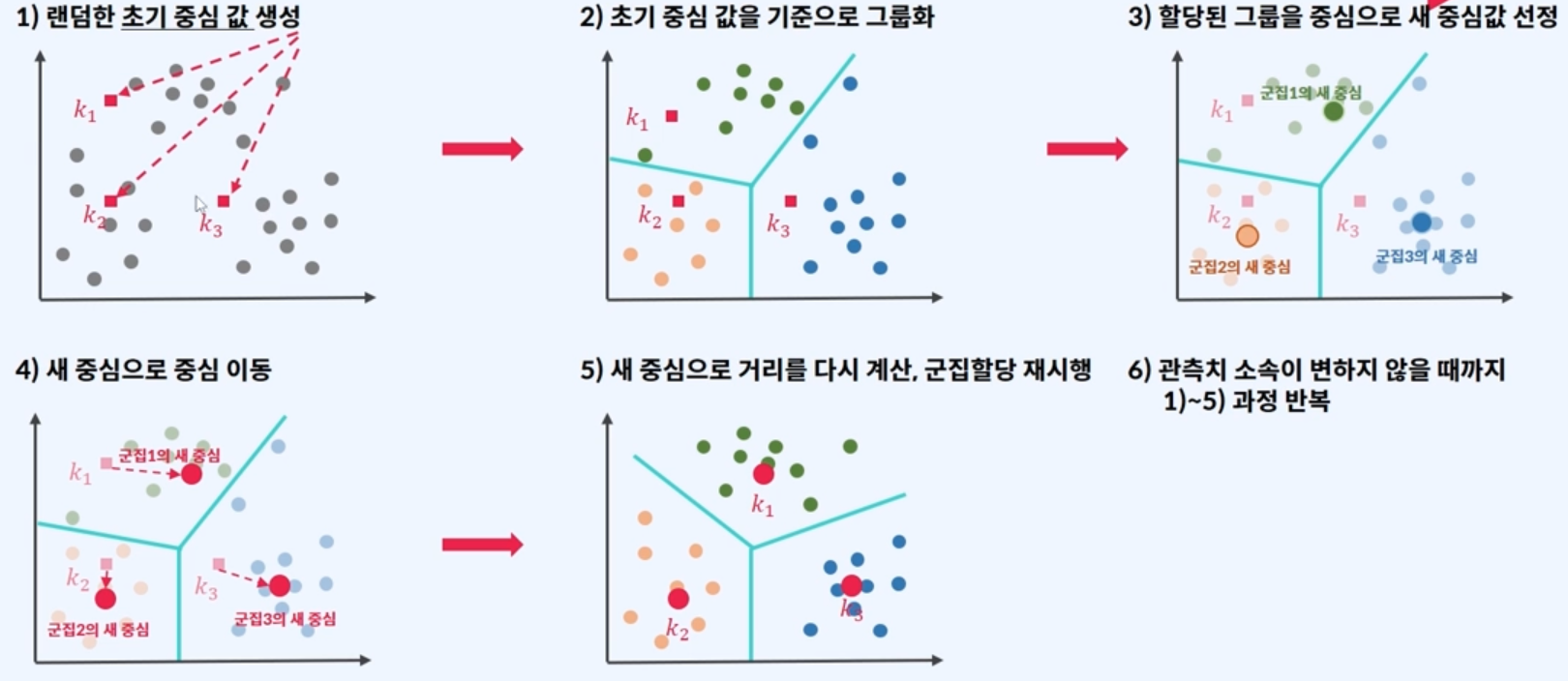
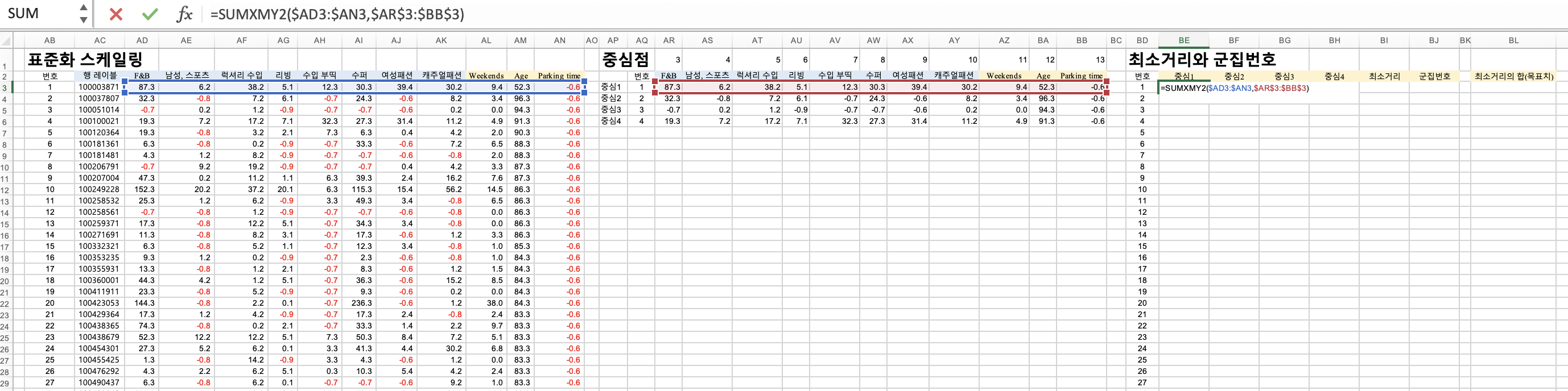
중심점계산
초기 랜덤중심값 4개를 먼저 생성해줍니다.
=vlookup(기준번호, 찾는범위, 몇번째열인지,0)=vlookup($기준번호, $찾는$범위, 몇번째$열인지,0)
중심점계산을 기준으로 그룹화
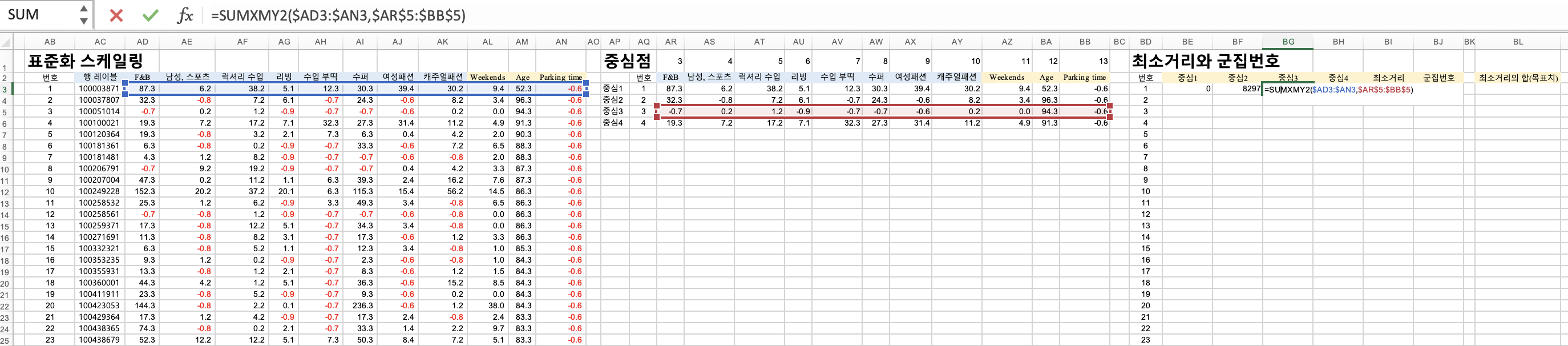
=sumxmy2() 를 통해, 각각의 중심1~4 값으로부터 얼마나 거리가 있는지 알아봅니다.
x - y제곱의 합
x minus y 2
=sumxmy2(x , 랜던값y)
여기서 x는 표준화스케일링의 하나의 row
여기서 y는 초기랜덤값 4개의 각 row
=sumxmy2($범위 , $범$위)
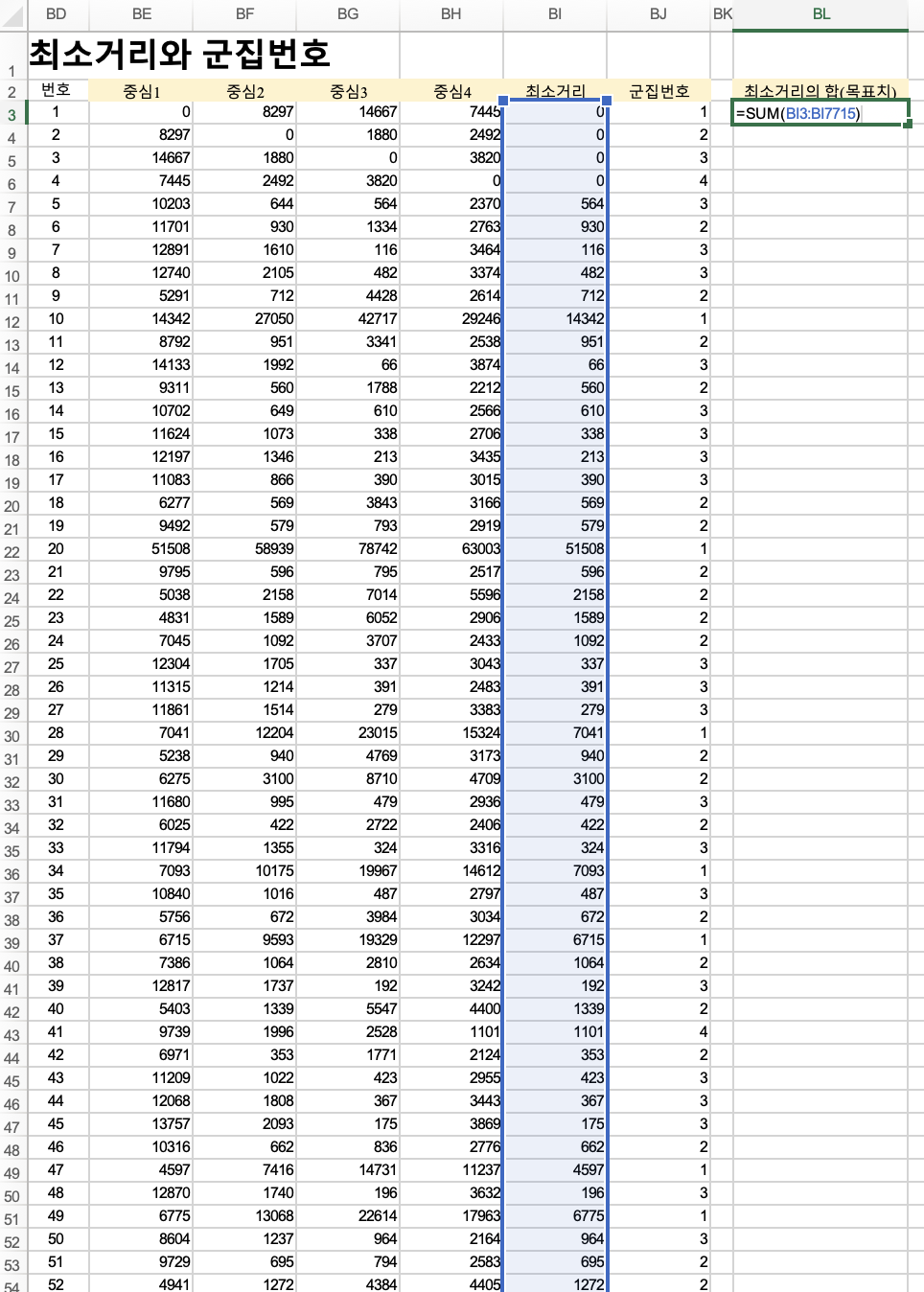
최소거리
=min()를 이용해서 랜덤1~4로부터 구해준 x-y2 값들을 지정해줍니다.
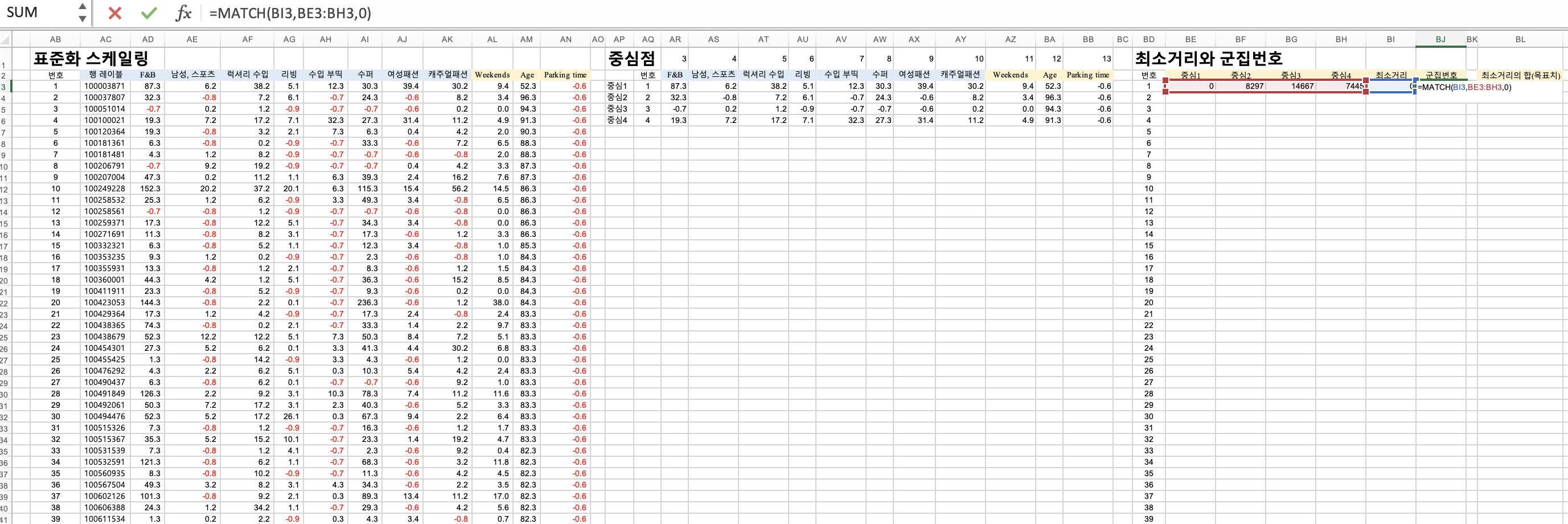
군집번호
=match()를 이용해서 군집번호를 할당해줍니다.
=match(최소거리, 랜덤1~4의 x-y2값, 0)
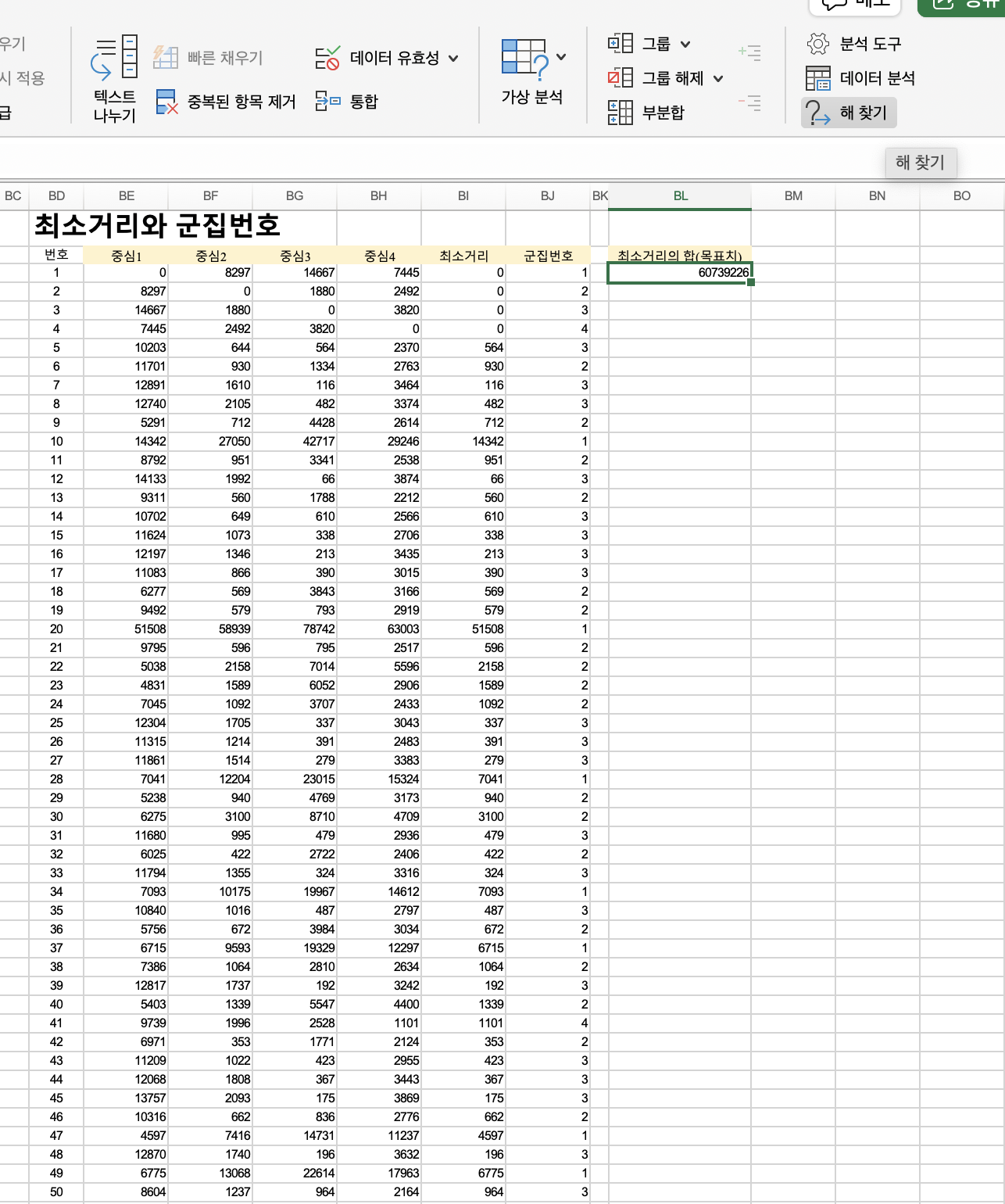
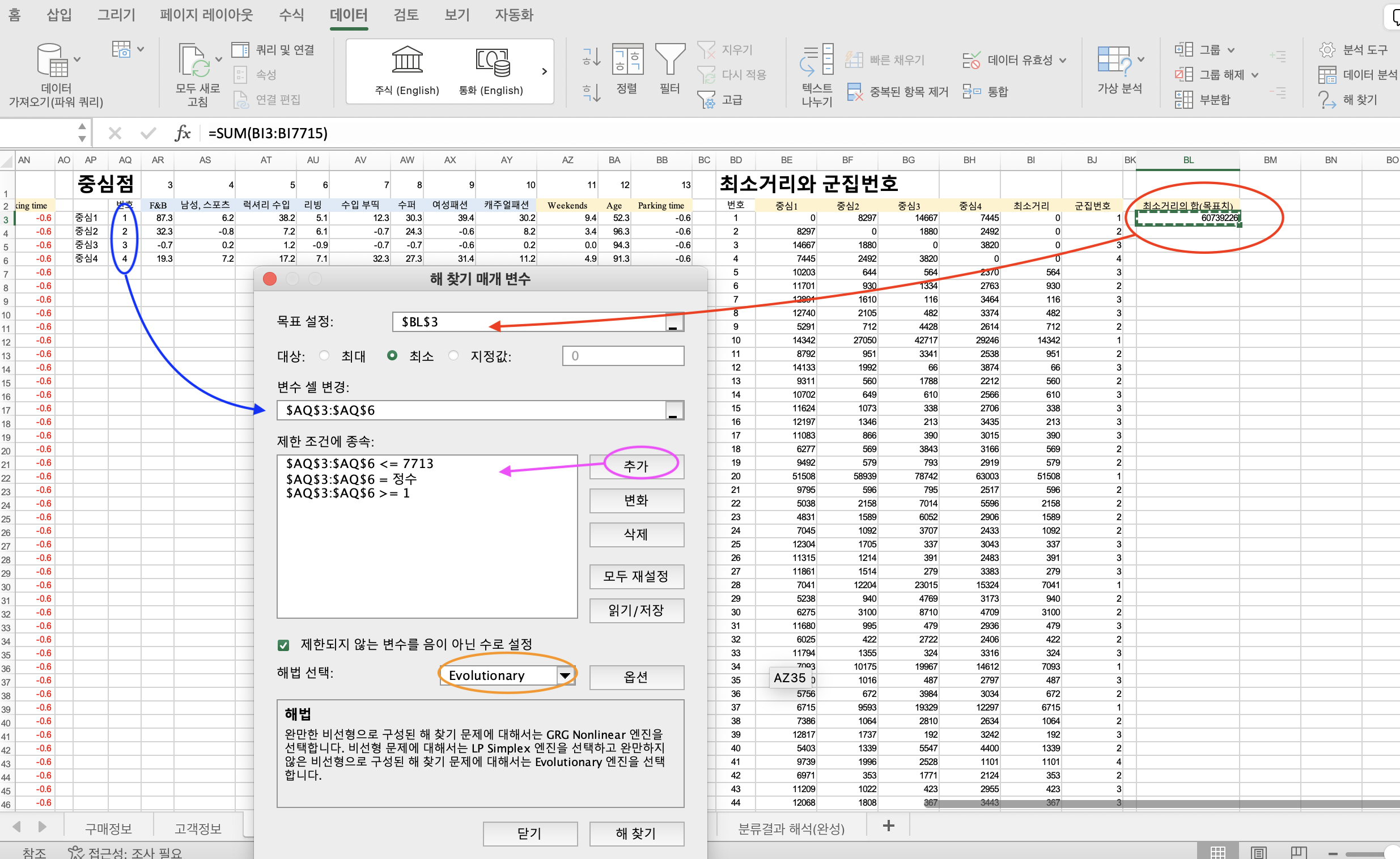
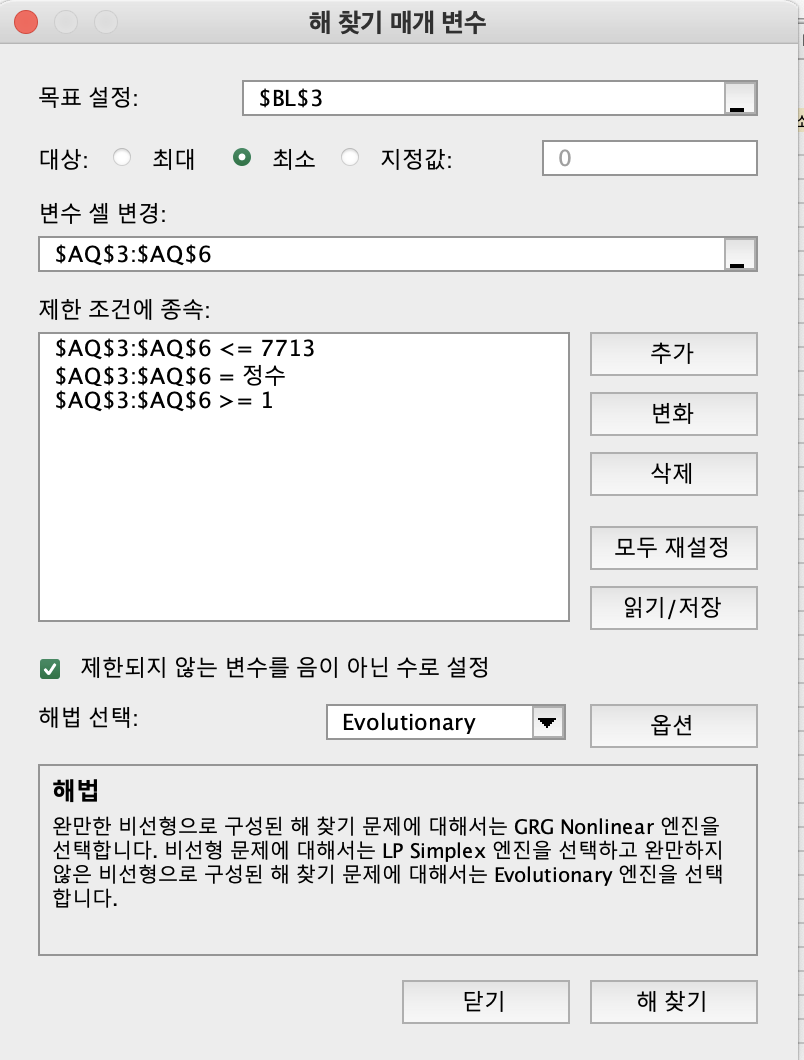
목표: 최소거리의 합을 가장 작게
중심(랜덤중심값)이 어디있어야, 최소 거리들의 합이 가장 작아질 지 구해야합니다.
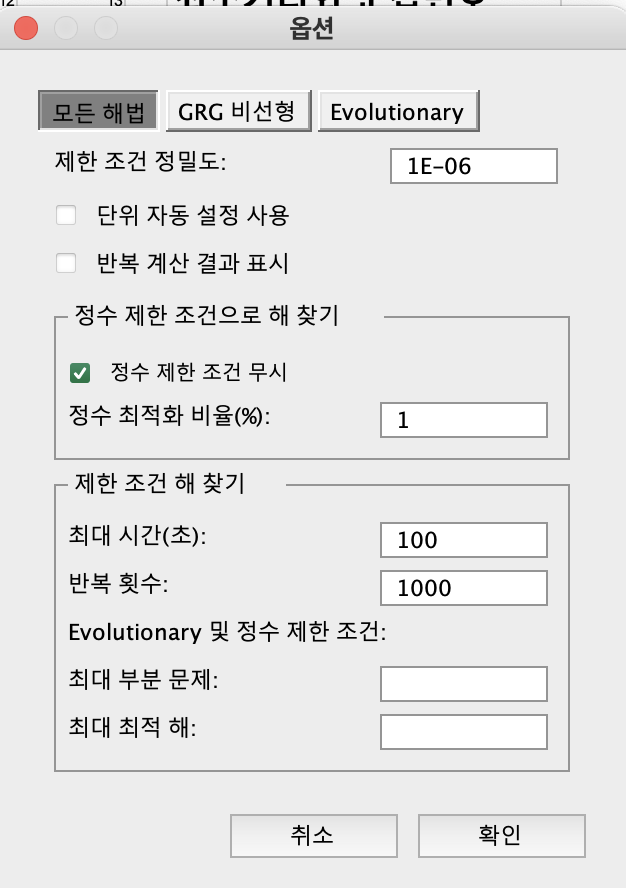
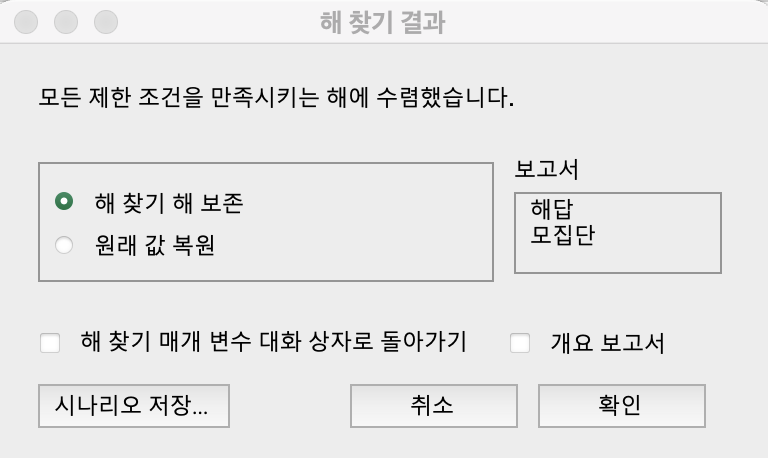
해찾기
데이터 > 해찾기
- 조건1 : 1~4(중심1~중심4)가 int정수여야 합니다.
1.2 또는 2.4 이렇게 소숫점으로 나오면 안되니깐요. - 조건2 : 1보다 같거나 커야 합니다.
- 조건3 : 표준화의 행 레이블에서 가장 최소값 보다 작거나 같아야 합니다.
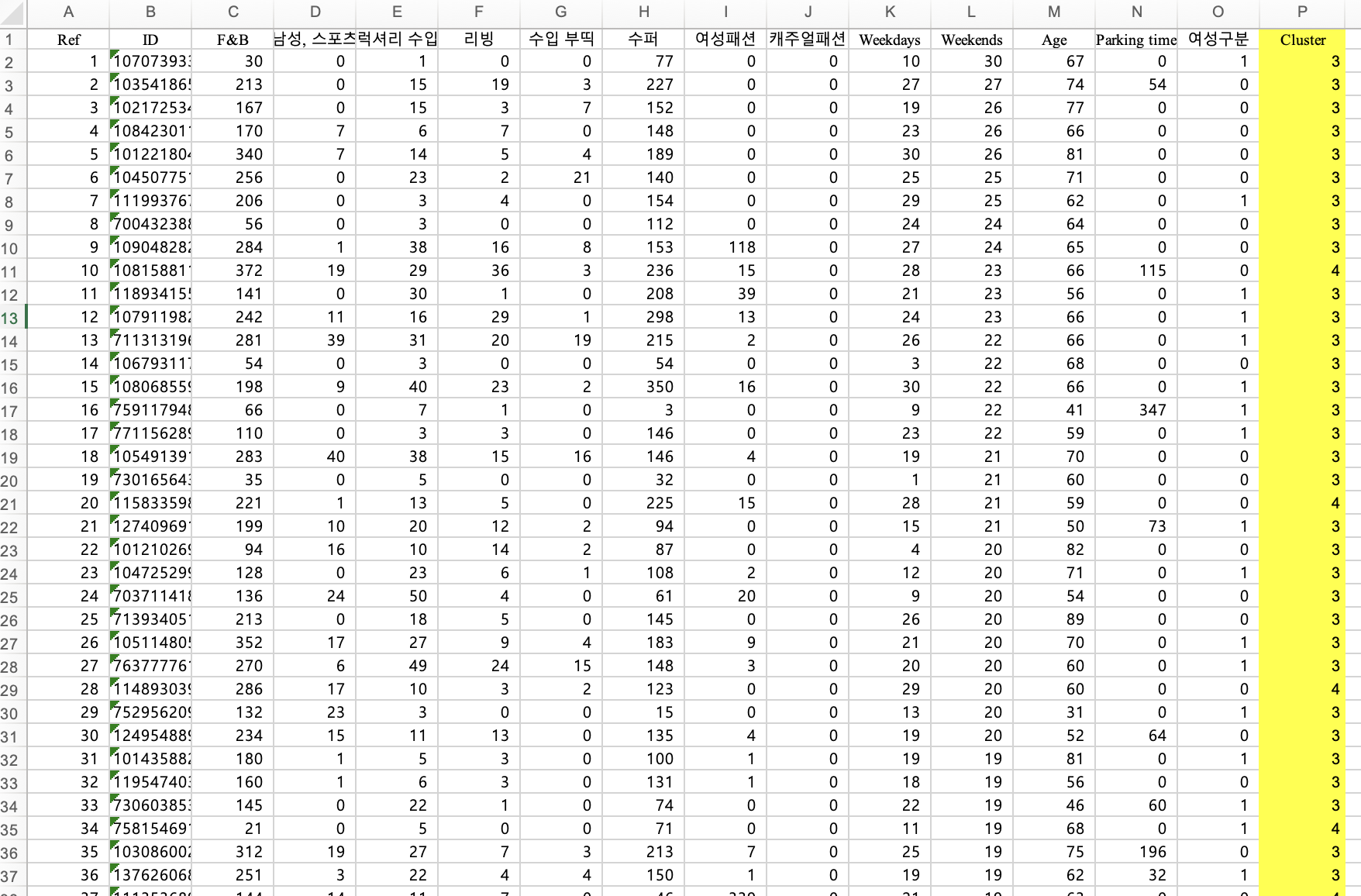
만들어진 군집번호 확인


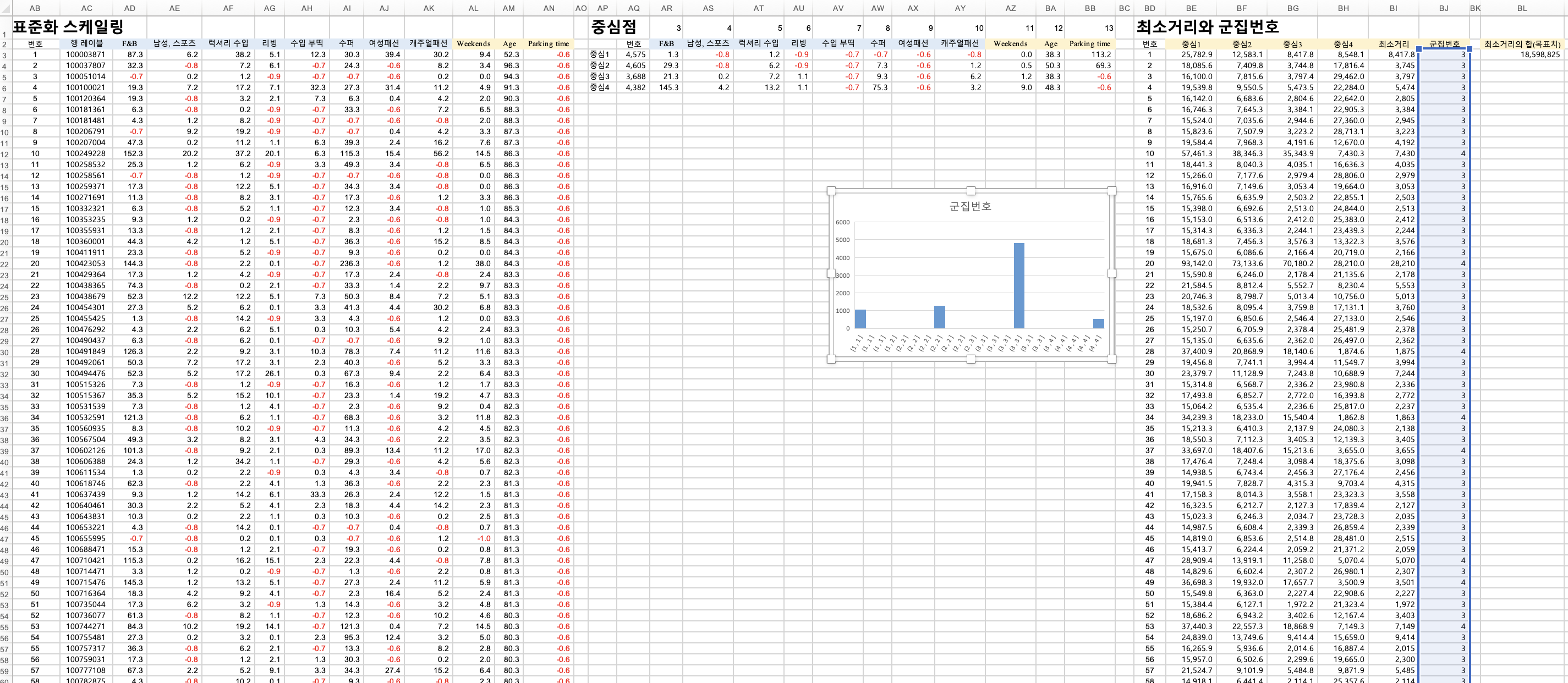
결과분석
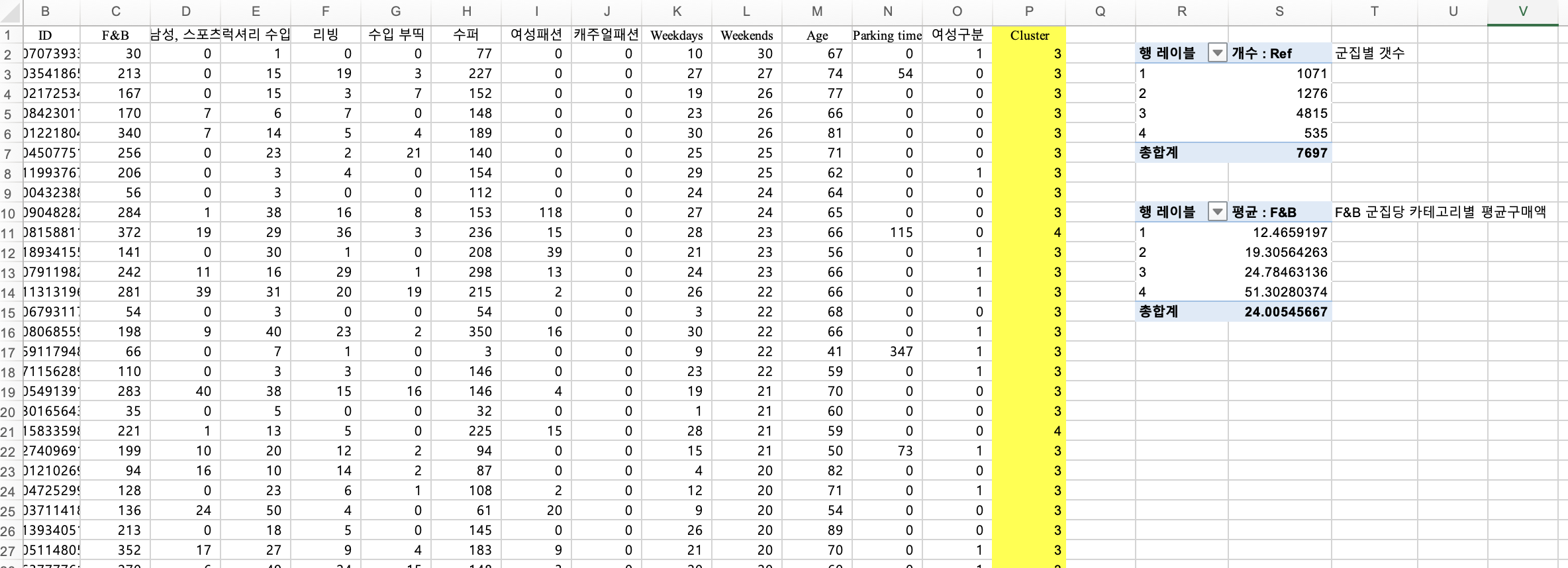
새 창에 다시 깔끔하게 복붙해줍니다.
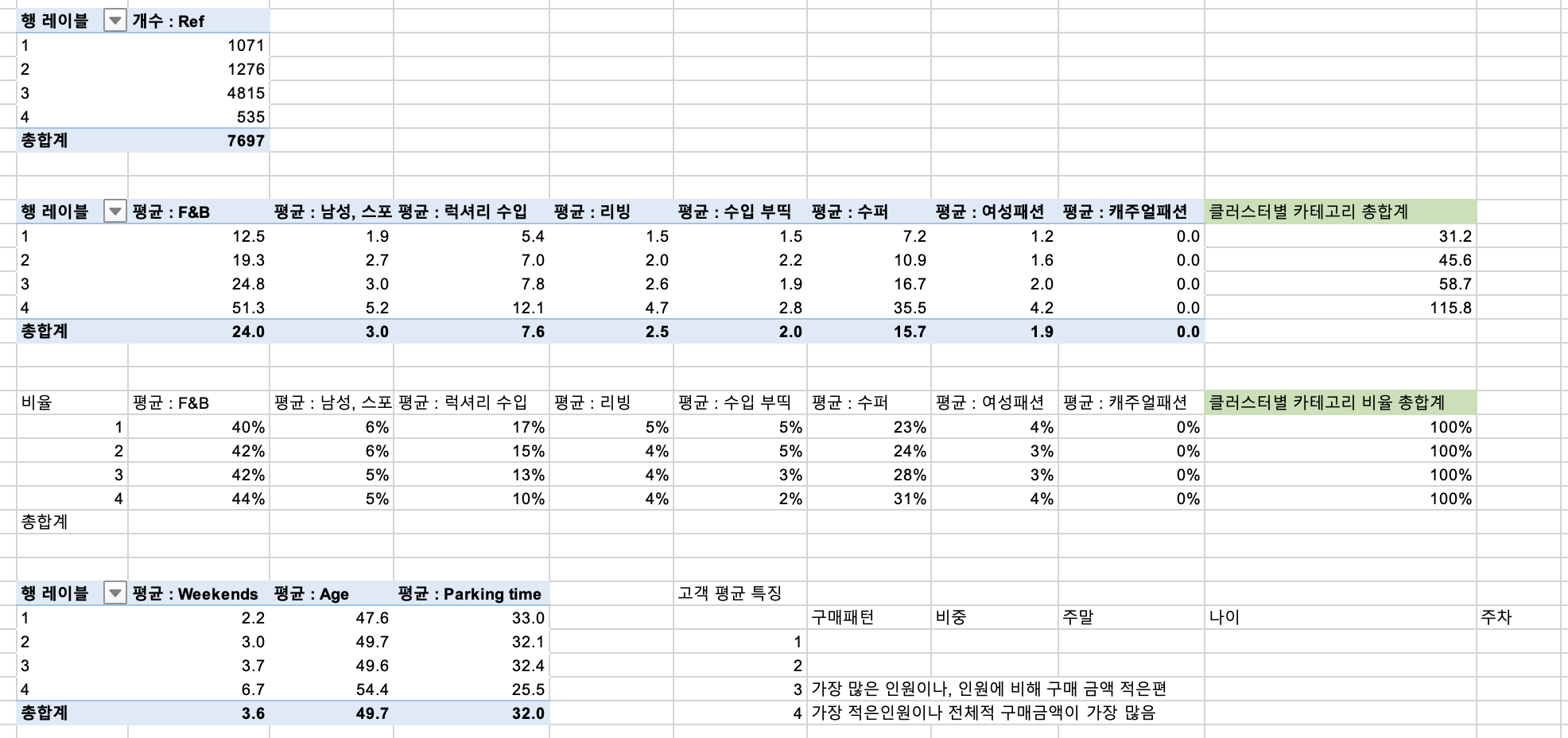
여기에 피벗테이블을 만들어서 각 군집번호당 몇 개씩 군집화 되었는지 확인해줍니다.
- 행 : 군집번호
- 값 : ref 갯수
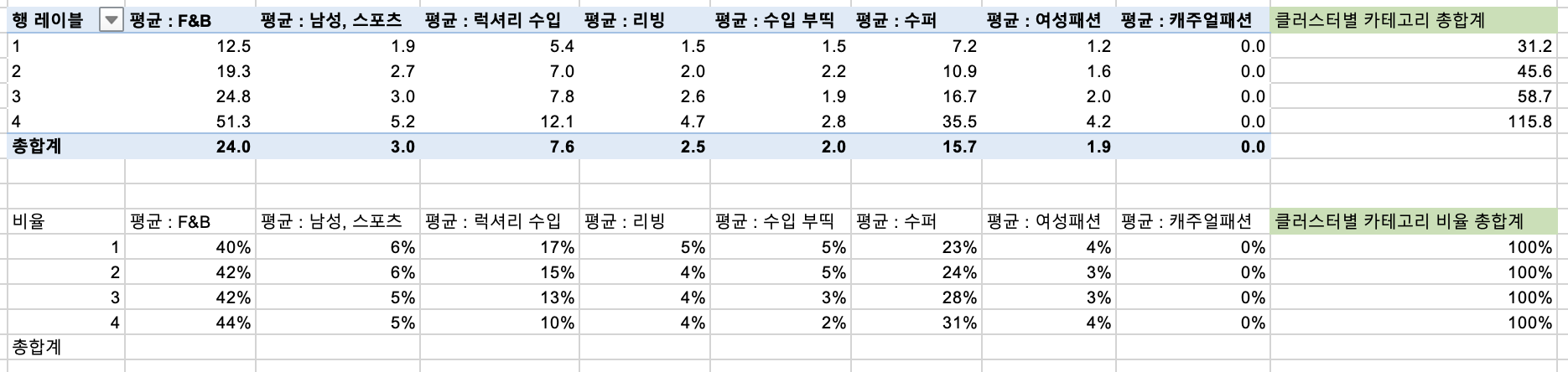
이렇게 각 카테고리별 평균 건수를 확인해보겠습니다.
또한 각 클러스터별 모든 카테고리의 평균금액을 합쳐보겠습니다.
그리고 구한 값들의 비율을 확인해보겠습니다.
해당 클러스터의 각 카테고리별 평균금액 / 해당 클러스터의 총 평균 금액
대체로 F&B, 슈퍼에 대한 모든 클러스터가 높게 나왔습니다.
특히 4번 클러스터의 비율이 높게 나왔습니다.
주말, 나이, 주차시간의 평균 매출금액도 확인해보겠습니다.
이렇게 구별된 고객그룹(클러스터)별 특징을 간단히 메모해둡니다.