방통대 출석과제 30점만점 받은 기념으로 작성합니다.
R
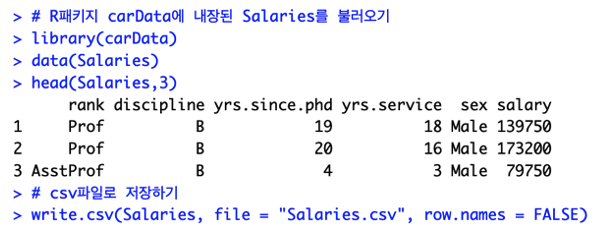
R에서 제공하는 carData 패키지 데이터를 이용합니다.
산점도
x축을 yrs.since.phd(박사학위 취득 후 경력년수)
y축을 salary (급여)
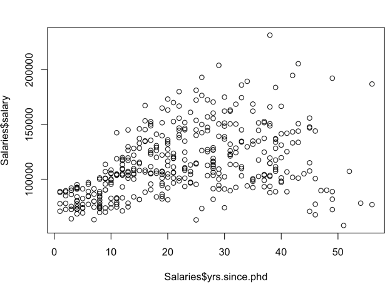
Yrs.since.phd(박사학위 취득 후 경력년수이며 이하 x축)의 시간적 흐름에 따른 Salary(급여이며 이하 y축)의 연관성을 볼 수 있다. 대체적으로 x축과 y축은 하나가 증가하면 나머지도 증가하는 양의 상관관계를 보일 수 있다.
두 축 모두 낮은 수치에서는 밀집도가 강해 보이나, 수치가 증가할 수록 밀집도가 약해 퍼져 나가는 형태이며 강한 상관관계로 보여지지는 않는다.
y축의 하단 구간 밀집도에 비하여 상단 구간의 밀집도가 차이가 나기 때문에, “박사학위 취득 후 경력년수”가 증가하는 만큼 “급여”가 증가한다고 확정 지을 수 없다.
그룹별 산점도
참고로 Salaries의 rank를 plot하기 전 unique로 먼저 입력해주고 진행합니다.
하지않을경우 범례legend에서 각 그룹에 해당하는 색상대로가 아닌 다르게 배치될 수 있습니다.

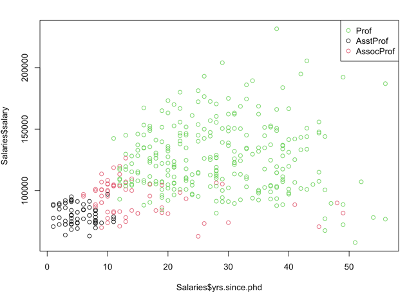
Rank별 박사학위 취득 후 경력년수에 따른 급여에 대한 산점도입니다.
① 경력년수와 급여 모두 낮은 축에 속하는 AsstProf (Assistant Professor조교수),
② 경력년수가 증가하는것에 비해 급여는 크게 증가하지 않는 AssocProf(Associate Professor 부교수),
③ 경력년수와 급여 모두 대체적으로 증가하는 Prof(Professor교수)
이렇게 구분지어 볼 수 있습니다.
Bubble Plot
위의 산점도 “yrs.service” 크기를 나타내는 bubble plot를 그려보겠습니다.

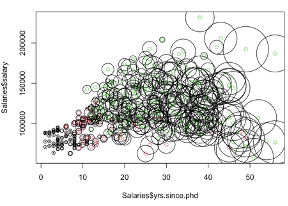
박사학위 취득 후 경력년수(x축, yrs.since.phd)에 따른 급여(y축, salary)의 산점도를 rank별로 색상 구분한 뒤, 현재 직위에서의 근무년수(circle, yrs.service)에 따라 원형 크기를 나타내는 bubble plot 입니다.
박사학위 취득 후 경력년수가 커질수록 현재 직위에서의 근무년수도 커지는 흐름입니다.
급여가 높아질수록 현재직위에서의 근무년수도 커지는 흐름입니다.
따라서 현재직위에서의 근무년수는 박사학위 취득후 경력년수와 급여에 대해 양의 상관관계를 갖고 있습니다.
Python
산점도
x축을 "yrs.since.phd" y축을 "salary" 의 산점도를 Python 으로도 그려보겠습니다.
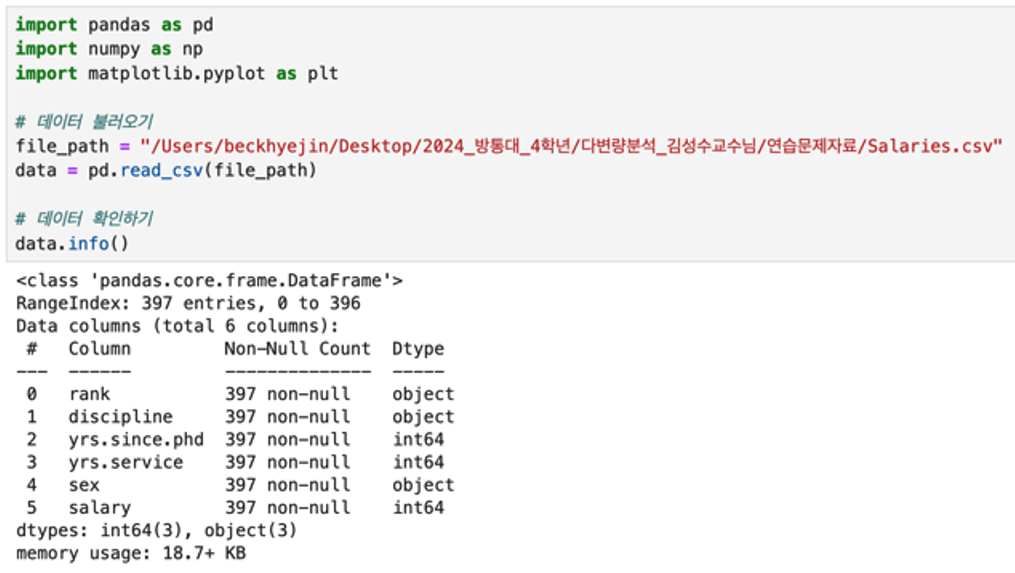

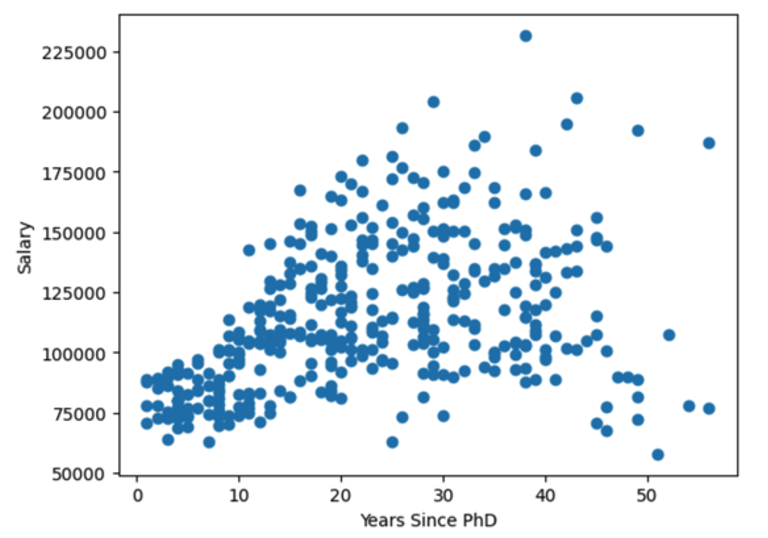
참고로 R과 Python의 산점도를 비교해보겠습니다.
왼쪽이 Python, 오른쪽이 R 로 그린 산점도입니다.
이것만 본다면 R로 그린 산점도가 제법 더 멋있는 것 같습니다.결과는 다행히 동일하게 보여집니다.
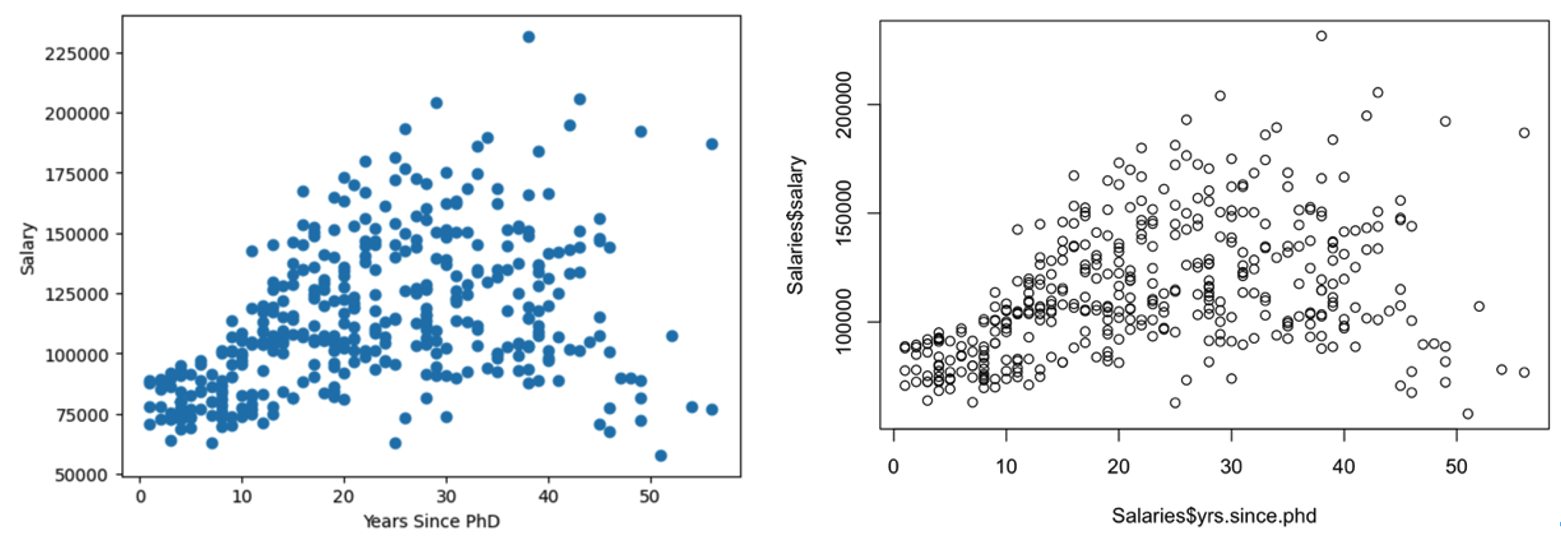
X와 y는 양의 상관관계 형태를 띄고 있으나, y축의 하단 구간 밀집도에 비하여 상단 구간의 밀집도가 차이가 나는 것으로 보아, “박사학위 취득 후 경력년수(x)”가 증가하는 만큼 “급여(y)”가 증가한다고 확정 지을 수 없습니다.
그룹별 산점도
그룹변서 rank 로 구분 후 위의 산점도에 그룹별로 시각화 해주겠습니다.
import seaborn as sns
sns.pairplot(data, hue='rank', height=2.5)
교재에 나와있는 iris산점도행렬 코드(p36)를 기준으로 sns.pairplot의 인수 중 하나인 x_vars, y_vars 로 각각 x,y축을 지정하고 hue를 통해 ‘rank’를 그룹화하여 색상으로 시각화 하는 조건인 산점도를 다시 그려보았습니다.
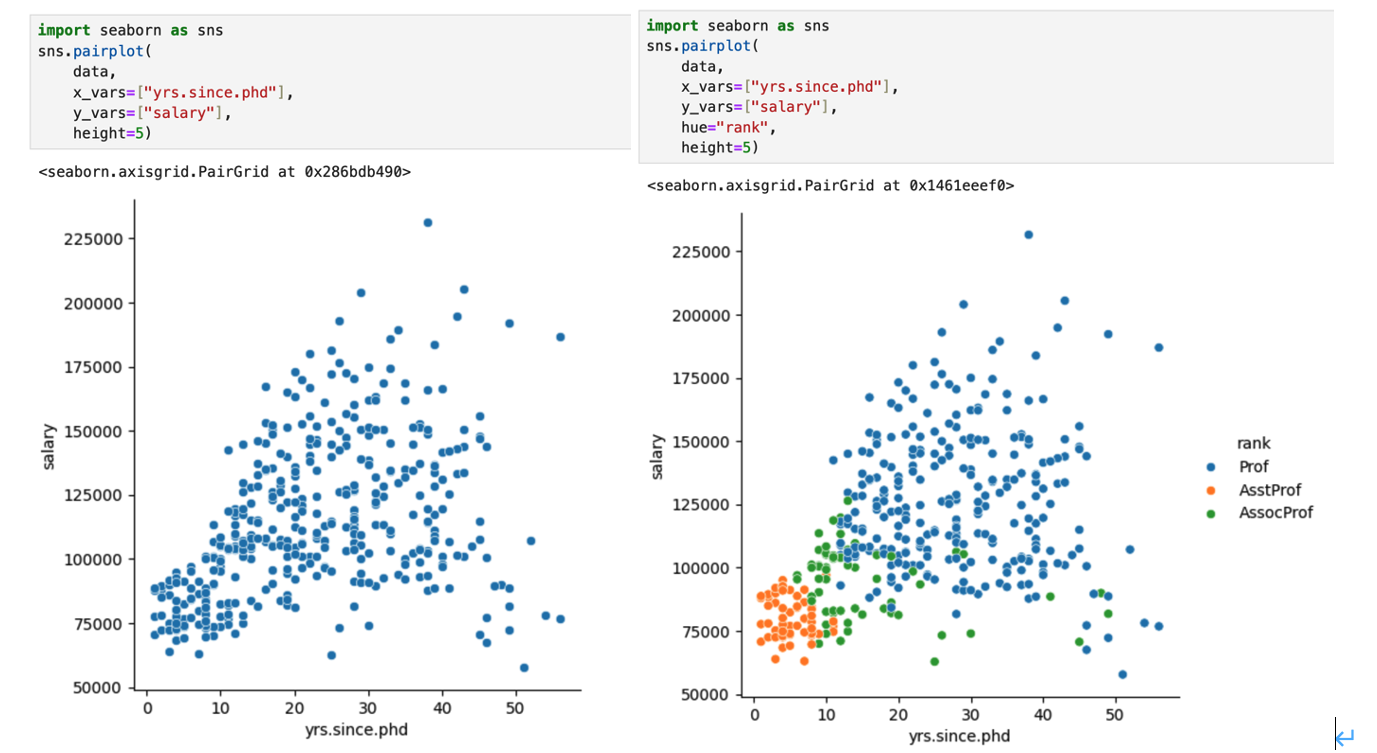
hue="rank" 만 추가했는데 그룹별 색상으로 시각화가 되었습니다.
위의 R에서의 산점도와 거의 동일하게 나왔습니다. 경력년수와 급여 모두 낮은 축에 속하는 AsstProf 조교수 , 경력년수가 증가하는 것에 비해 급여는 크게 증가하지 않는 Prof교수, 경력년수와 급여 모두 대체적으로 증가하는 AssoProf 부교수 이렇게 3가지의 색상 구분이 비교적 육안으로 보여집니다.
Bubble Plot
위의 산점도에 "yrs.service" 크기를 나타내는 bubble plot을 그려보겠습니다.
# 버블차트 그리기
# 변수값을 5가 아닌 3만 주기
data['yrs.service'] = data['yrs.service] * 3
plt.scatter(data['yrs.since.phd'], data['salary'], s= data['yrs.service'] , alpha = 0.9) 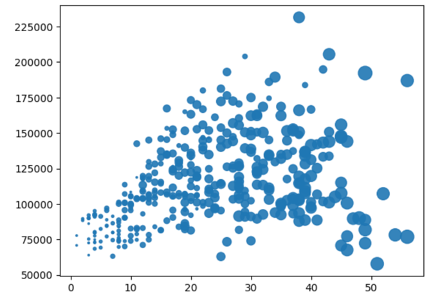
여기에 rank별로 색상 구분해야 합니다. Pairplot은 버블 플롯 사용 불가하고, scatter는 색상지정이 어려운 것 같습니다. 자꾸 오류가 나서 인터넷 검색한 결과 Seaborn의 scatterplot함수로도 산점도를 그릴 수 있기에 매개 변수인 hue와 size를 이용해 만들어보겠습니다.
sns.scatterplot(
data=data, # 데이터
x = "yrs.since.phd" # x 축
y = "salary" # y 축
hue = "rank" # 그룹별(색상)
size = "yrs.service" # 버블사이즈 변수
sizes = (10,200) # 버블사이즈 수치
legend = False # 범례 아예 안보이게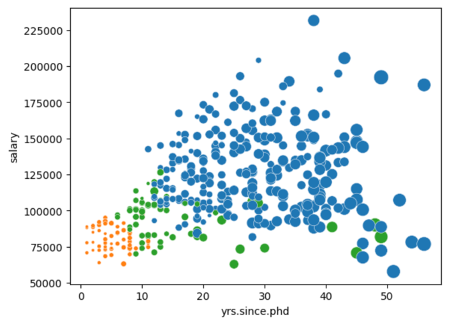
범례 안보이게 해놨기에, 별도로 가져왔습니다.

위의 주황색으로 보여지는 조교수 (AsstProf)들이 박사학위 취득 후 경력년수(yrs.since.phd), 급여(Salary), 현재직위에서의 근무년수(yrs.service) 수치가 모두 낮습니다.
그 다음으론 연두색으로 보여지는 부교수(AssocProf)들은 박사학위 취득 후 경력년수(yrs.since.phd)가 증가하더라도 급여(Salary)는 크게 증가하지 않는 것으로 보여지며, 현재직위에서의 근무년수(yrs.service)는 함께 증가하는 것으로 보여집니다.
마지막으로 파란색으로 보여지는 교수 (Prof)들은 박사학위 취득 후 경력년수(yrs.since.phd)가 증가할수록 급여(Salary)와 현재직위에서의 근무년수(yrs.service)가 함께 증가하는 것으로 보여집니다.
다른 조교수와 부교수와 비교하여 그나마 강한 양의 상관관계를 가지고 있습니다.
