분산 데이터 저장 기술
- 분산 파일 시스템
- 데이터베이스 클러스터
- NoSQL ✅
NoSQL
- Not Only SQL : 비관계형 데이터베이스 관리 시스템이지만 SQL 계열 쿼리도 사용가능.
- 분산 데이터베이스 기술로 확장성, 가용성, 높은 성능을 제공
- 저장되는 데이터 구조에 따라 key-value모델, Document모델, Graph모델, Column모델로 구분.
- Key와 Value의 형태로 자료를 저장
- Join 연산을 지원하지 않아 대용량 데이터 처리와 대규모의 수평적 확장성을 제공.
구글 빅테이블
- 구글이 개발한 분산 데이터 관리 저장소.
- 공유 디스크 방식.
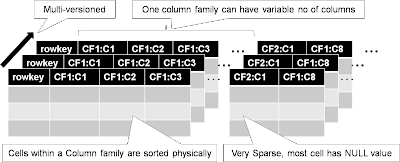
데이터 모델
- 테이블 내 모든 데이터는 row-key의 사전적 순서로 정렬, 저장.
- row는 n개의 column-family를 가질 수 있고, column-family에는 column-key, value, time stamp 형태로 데이터를 저장.
- 동일한 column-key에 대해 타임스탬프가 다른 여러 버전이 존재할 수 있고, 타임 스탬프는 컬럼 값 버전을 관리하기 위해 사용한다.
- 하나의 데이터의 키 값 또는 정렬 기준은 'rowkey + columnkey + timestamp'이다.
페일오버
- 장애가 발생할 경우, 빅테이블의 마스터는 장애가 발생한 노드에서 서비스되던 Tablet을 다른 노드로 재할당.
(Tablet은 파티셔닝 된 단위) - 빅테이블의 SPOF는 마스터다.
SPOF(Single Point Of Failure)
시스템의 구성 요소 중 동작하지 않으면 전체 시스템이 중단되는 요소. - 분삭 락 서비스를 제공하는 Chubby를 이용해 Master를 계속 모니터링 하다가 마스터에 장애가 발생하면 가용한 노드가 마스터 역할을 수행하도록 한다.
- Chubby는 폴트톨러런스 지원 구조이기에 장애가 발생하지 않는다.
AppEngine
- AppEngine에서는 사용자가 수행하는 쿼리를 분석하여 자동으로 인덱스를 생성해준다.
- AppEngine에서 생성한 인덱스도 빅테이블의 특정 테이블 또는 테이블 내 컬럼으로 저장된다.
아파치 HBase
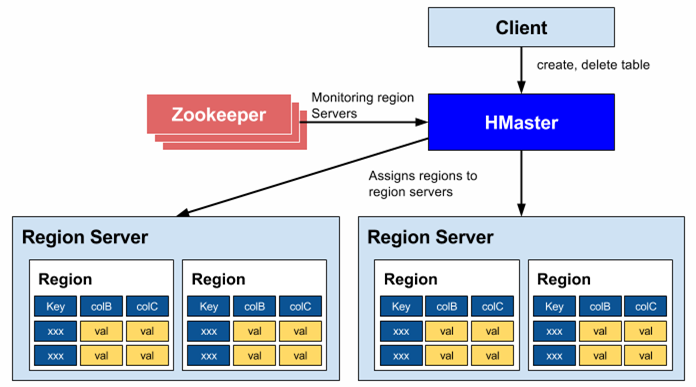
- 하둡 분산 파일 시스템기반, 컬럼 기반 분산 데이터베이스
- 관계형 구조가 아니여서 SQL을 지원하지 않음.
- 대규모의 데이터에서 실시간 읽기/쓰기 작업이 필요할 때 사용
- 선형으로 확장이 가능한 구조를 가지고 있으며, 클러스터를 통한 데이터의 복제 기능을 제공.
- Row key에 대한 인덱싱만을 지원. Zookeeper을 이용해 고가용성을 보장한다.
Zookeeper
분산 시스템을 설계 하다보면, 가장 문제점 중의 하나가 분산된 시스템간의 정보를 어떻게 공유할것이고, 클러스터에 있는 서버들의 상태를 체크할 필요가 있으며 또한, 분산된 서버들간에 동기화를 위한 락(lock)을 처리하는 것들이 문제로 부딪힌다.
이러한 문제를 해결하는 시스템을 코디네이션 서비스 시스템 (coordination service)라고 하는데, Apache Zookeeper가 대표적이다.
출처: https://bcho.tistory.com/1016 [조대협의 블로그]
아마존 SimpleDB
- 데이터의 실시간 처리를 지원한다.
- 하나의 데이터에 여러 개의 복제본을 유지하므로 가용성을 높임.
- 트랜잭션 종료 후 데이터가 모든 노드에 즉시 반영되지 않고 초 단위로 지연 동기화(Eventual Consistency)
- 관계형 데이터 모델과 표준 SQL은 지원하지 않고 전용 쿼리 언어를 이용해 데이터를 조회.
- 스키마가 없는 구조
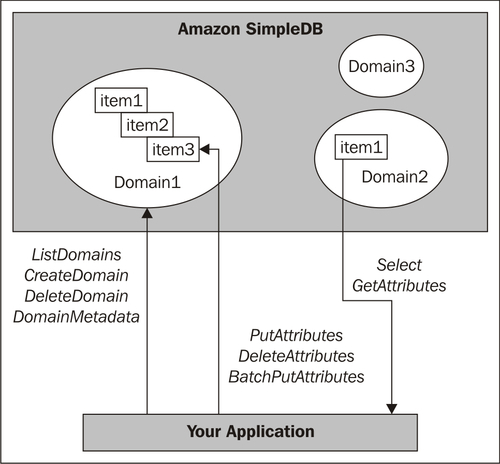
| 도메인 (Domain) | - 관계형 데이터베이스의 테이블과 동일한 개념 - 최대 10GB의 데이터를 저장, 사용자는 100개의 도메인을 가질 수 있음. (사용자는 최대 1,000GB의 데이터 저장 가능) |
| item | - 관계형 데이터베이스의 레코드와 동일한 개념 - item은 독립적인 객체를 나타냄. - 1개~256개 Attribute를 가진다. |
| attribute | - 관계형 데이터베이스의 컬럼과 동일한 개념. 미리 정의할 필요 없음. - item의 특정 attribute에는 여러 개의 값을 저장할 수 있다. |
- 한번에 하나의 도메인에 대해서만 쿼리를 수행
- 두 개의 도메인으로부터 데이터를 조회할 경우 쿼리가 여러 번 수행되어야 한다.
- 클라이언트는 SOAP 또는 REST 프로토콜을 이용해서 SimpleDB 이용 가능
제공하는 API
구분 내용 CreateDomain 도메인 생성 DeleteDomain 도메인 삭제 ListDomains 모든 도메인 목록 가져옴 PutAttributes Item 생성하고 Attribute에 값 추가 DeleteAttributes Attribute 값 삭제 GetAttributes Attribute 값 조회 Query 쿼리를 이용해 조건에 맞는 여러 개 item 조회.
마이크로소프트 SSDS
- Sql Server Data Service
데이터 모델
컨테이너 - 테이블과 유사한 개념
- 하나의 컨테이너에 여러 종류의 엔티티 저장 가능엔티티 - 엔티티는 레코드와 유사한 개념
- 하나의 엔티티는 여러 개의 property를 가질 수 있다.
- property는 name-value 쌍으로 저장.
- SSDS는 컨테이너의 생성/삭제, 엔티티의 생성/삭제, 조회 쿼리등 API 제공, SOAP/REST 기반의 프로토콜 지원
