분산 데이터 저장 기술
- 분산 파일 시스템
- 데이터베이스 클러스터 ✅
- NoSQL
데이터베이스 클러스터
하나의 데이터베이스를 여러 개의 서버 상에 구축하는 것
- 파티셔닝과 클러스터의 효과
- 병렬처리 : 빠른 데이터 검색 및 처리 성능을 얻을 수 있다.
- 고가용성 : 파티션에 장애가 발생하더라도 서비스가 중단되지 않는다.
- 성능향상 : 성능의 선형적인 증가 효과를 가져올 수 있다.
데이터 베이스 파티셔닝
- 데이터베이스를 파티션이라는 작은 단위로 분할하는 것을 의미.
데이터 베이스 파티셔닝
데이터 베이스 클러스터링
하나의 데이터베이스를 여러개의 서버로 분할해 구축.
- 특정 하드웨터 및 소프트웨어를 요구하지 않고 병렬 서버구조로 확장이 가능.
| 공유 디스크 | 무공유 디스크 |
|---|---|
| - 각 데이터베이스 인스턴스는 자신이 관리하는 데이터 파일을 자신의 로컬 리스크에 저장, 파일들을 고유하지 않는다. | - 모든 데이터베이스 인스턴스 노드들은 데이터 파일을 논리적으로 공유, 각 인스턴스는 모든 데이터에 접근할 수 있다. |
| - 장점 : 노드 확장에 제한이 없다. | - 장점 : 하나의 노드만 살아 있어도 서비스가 가능하다. |
| - 단점 : 장애가 발생할 경우를 대비해 별도의 폴트톨러런스를 구성해야 한다. | - 단점 : 클러스터가 커지면 디스크 영역에서 병목현상이 발생한다. |
| 완전히 분리되었기 때문에 각 데이터는 소유권을 갖고 있는 인스턴스가 처리. | 모든 노드가 데이터를 수정할 수 있어 노드간 동기화 작업 수행을 위한 별도 커뮤니케이션 채널 필요. |
| 데이터 처리 요청을 받으면, 요청받은 노드는 처리할 데이터를 갖고 있는 노드에 신호를 보내 데이터 처리를 요청 | 데이터를 공유하려면 SAN(Storage Area Network)과 같은 네트워크가 있어야 한다. |
| Oracle RAC | IBM DB2 ICE, 마이크로소프트 SQL Server, MySQL |
⭐️폴트톨러런스 : 시스템에 고장이 발생하더라도 모든 기능 혹은 기능의 일부를 기존과 같이 유지하는 기술.
데이터베이스 클러스터의 종류
Oracle RAC 데이터베이스 서버
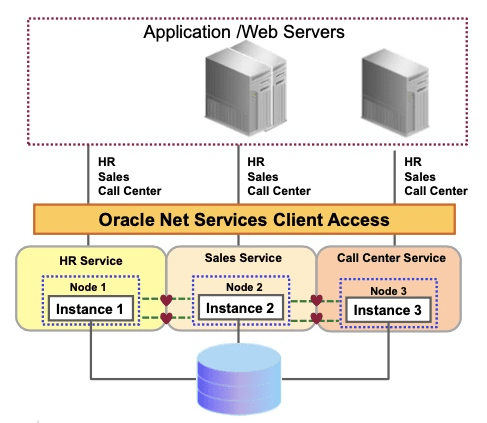
- 공유 클러스터이다.
- 특정 노드가 데이터를 소유하는 개념이 없어 파티셔닝을 할 필요가 없지만, 성능 향상을 위해 파티셔닝하는 경우가 많다.
- 장점
| 가용성 | 하나의 노드만 살아 있어도 서비스가 가능 |
| 확장성 | 응용 프로그램이나 데이터베이스를 수정할 필요없이 새 노드를 클러스터에 쉽게 추가 가능. |
| 비용 절감 | 저가형 상용 하드웨어의 클러스터에서도 효율적이므로 하드웨어 비용을 절감. |
IBM DB2 ICE
- 무공유 클러스터이다.
- 애플리케이션의 수정없이 기존 시스템에 노드 추가하고, 재분배가 가능해 시스템의 성능과 용량을 일정하게 유지할 수 있다.
- 하나의 노드에 장애가 발생할 경우 해당 노드에서 서비스하는 데이터에 대한 별도의 페일오버 메커니즘이 필요해 이때는 공유 디스크 방식을 사용해 가용성을 보장한다.
페일오버 : 데이터베이스의 최신 버전을 백업해두어 장애가 발생했을 경우 대체 시스템 작동시켜 장애 극복
마이크로소프트 SQL Server
- 연합 데이터베이스 형태이다.
연합 데이터베이스 : 공유하지 않는 독립된 서버에서 실행되는 서로 다른 데이터 베이스들 간 논리적 결합. 네트워크를 이용해 연결.
Federated Database 정리
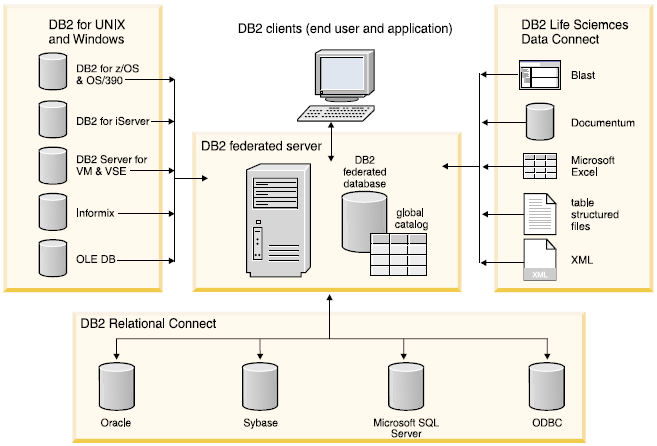
- 데이터는 관련된 서버들로 수평분할, 테이블은 논리적으로 분리
- UNION ALL을 이용해 논리적인 뷰 구성 = DPV(Distributed Partitioned View)
- 문제점
- 개발 시 파티셔닝 정책에 맞게 테이블과 뷰를 생성, 전역 스키마 정보가 없어 질의 수행을 위해 모든 노드를 액세스해야 한다.
- 노드가 많아지거나 노드의 추가/삭제가 발생하는 경우 파티션을 새로 구성
- 페일오버에 대해서는 별도로 구성
- SQL Server의 페일오버 메커니즘은 Active-Standby 방법을 사용한다.
Active-Active
로드밸런싱이라고도 불림.
Active-Standby
메인 서버와 스펙이 비슷한 예비용 서버를 준비해 운영. 메인 서버에 문제가 생기면 예비 서버로 서비스 운영
이중화
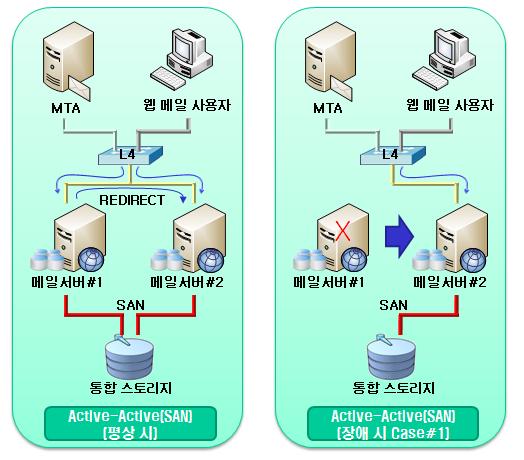
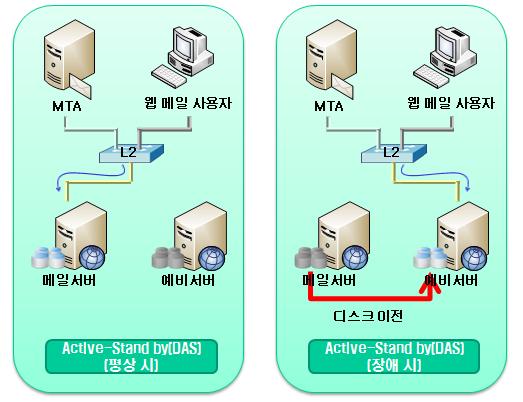
MySQL
- 비공유방식
- 데이터 가용성을 높이기 위해 데이터를 다른 노드에 복제.
- 구성
| 관리 노드 | 클러스터를 관리하는 노드. 클러스터 시작과 재구성시에만 관여 |
| 데이터 노드 | 클러스터의 데이터를 저장하는 노드 |
| MySQL 노드 | 클러스터 데이터에 접근을 지원하는 노드 |
- 가용성을 높이기 위해 데이터를 다른 노드에 복제. 장애가 발생했던 노드가 복구 후 클러스터에 투입된 경우 동기화작업이 자동으로 수행.
- 제한 사항
-
파티셔닝은 LINEAR KEY 파티셔닝만 사용 가능.
LINEAR KEY 파티셔닝
수평 파티셔닝이라고도 함.
테이블의 행이 물리적으로 다른 파티션에 할당될 수 있음.
mysql table partitioning -
클러스터에 참여한 노드 수는 255개로 제한. 데이터 노드는 최대 48개까지 가능
-
트랜잭션 수행 중에 롤백을 지원하지 않아 작업 수행 주 문제가 발생하면 전체 트랜잭션 이전으로 롤백해야 한다.
-
메모리 문제가 발생할 수 있어 여러 개의 트랜잭션으로 분리해 처리하는 것이 좋음.
트랜잭션
트랜잭션(Transaction)은 데이터베이스의 상태를 변환시키는 하나의 논리적 기능을 수행하기 위한 작업의 단위 또는 한꺼번에 모두 수행되어야 할 일련의 연산들을 의미한다.
트랜잭션 -
컬럼명은 31자, 테이블명 122자, 메타데이터는 2만 320개까지만 가능.
-
최대 생성가능 테이블 수는 2만 320개, 한 row의 크기는 8KB. 테이블 키는 32개가 최대.
-
모든 클러스터의 기종은 동일해야 한다.
-
운영 중 노드를 추가/삭제할 수 없다.
-
디스크 기반 클러스터인 경우 tablespace의 개수는 , tablespace당 데이터 파일의 개수는 , 크기는 32GB
디스크 기반 클러스터
인덱스가 생성된 칼럼은 기존과 동일하게 메모리에 유지되지만, 인텍스를 생성하지 않은 칼럼은 디스크에 저장된다. 따라서 디스크에 저장된 데이터는 모두 인덱스가 없는 데이터다.
mysql 클러스터 정리테이블스페이스
테이블스페이스(Tablespace)는 데이터베이스 오브젝트 내 실제 데이터를 저장하는 공간이다.
위키백과
