
이커머스 서비스에서는 선착순, 할인 등의 이벤트가 발생하면 순간 트래픽이 매우 높아진다. 케타포도 가끔 이벤트를 열었는데 그때마다 서비스에 장애가 발생했다. 여러가지 원인이 있었는데, 주요원인 중 하나인 재고 증감 기능을 개선한 이야기를 써보려 한다. 이 글을 통해 이커머스 서비스에서 재고 관리 기능을 개발하는 법을 알 수 있다.
1. 문제 상황
케타포는 원래 거대한 모놀리식 애플리케이션이었고 모든 데이터는 하나의 RDB에 저장되었다. 이런 구조는 순간 트래픽이 높아졌을 때 치명적인 장애를 유발했는데, 특히 쓰기DB의 부하가 문제가 되었다. 리더 DB가 1개인 Leader Based Replication 방식을 사용했기 때문에 읽기DB는 스케일 아웃을 통해 트래픽을 분산시킬 수 있었지만, 쓰기DB는 스케일 아웃을 할 수 없었다. 이벤트가 열리면 주문 생성, 재고 차감과 같은 쓰기 요청이 평시 몇십 배의 규모로 쓰기DB에 전달되었고 쓰기DB의 CPU 사용률은 순식간에 100% 가까이에 도달했다. 케타포의 레거시 서비스에서는 읽기 API 또한 쓰기DB에 의존했으므로 이는 전면 장애를 유발했다. 오랜 기간 점진적으로 서비스를 개선해나갔지만 쓰기DB에 부하를 일으키는 결정적 요인인 재고 증감 기능을 개선하지 않는 한 이벤트 때마다 장애가 발생하는 것은 피할 수 없었다.
2. 해결 방법
쓰기 DB에 순간적으로 집중되는 부하를 분산하고 데이터의 정합성을 높이기 위해 다음과 같은 설계 패턴들을 쓸 수 있다.
Write-Behind Caching
write-behind caching은 캐시 레이어에서 먼저 데이터를 업데이트 한 후, 캐시 레이어 뒤의 데이터 소스에 쓰기 연산을 하는 패턴이다. write-behind pattern에서는 캐시 업데이트에 성공한다면 데이터 소스의 업데이트 결과를 기다리지 않고 바로 응답을 반환한다. 따라서 캐시 데이터와 DB 데이터가 최종 일관성을 달성하기까지 시간차가 생길 수 있다. 이 패턴은 쓰기 성능을 향상시키고 싶을 때 효과적이지만 애플리케이션의 복잡성을 증가시키고, 캐시 쓰기와 DB 쓰기 사이에 실패가 발생하면 데이터 정합성이 깨질 수 있다.
Queue-Based Load Leveling
queue-based load leveling은 큐나 메시지 브로커를 이용해 순간적으로 치솟은 트래픽을 분산시키는 패턴이다. 짧은 시간에 요청이 몰렸을 때 요청을 모두 큐 혹은 메시지 브로커에 넣고, 예측 가능하고 일관된 속도로 요청을 처리한다.
Event Sourcing
event sourcing은 애플리케이션의 상태 변화를 일련의 이벤트로 저장하는 패턴이다. 이로 인해 데이터의 변경내역을 추적하기 쉬워질 뿐 아니라 서비스끼리의 결합도도 낮출 수 있다.
Token Bucket Algorithm
token bucket algorithm은 시스템이 주고 받는 데이터의 양을 제어하여 트래픽을 관리하는 알고리즘이다. token bucket algorithm에서는 버킷에 고정된 수의 토큰이 저장되고 고정된 비율로 추가된다. 시스템에 요청이 도착하면 각 요청은 버킷에 있는 토큰을 받아야 한다. 토큰이 있는 요청은 바로 처리되며, 요청이 처리될 때마다 버킷에서 토큰이 하나씩 제거된다. 토큰을 얻지 못한 요청은 거부되거나 버퍼에서 대기하게 된다. 대표적인 구현체로는 guava의 rate limiter가 있다.
3. 인메모리 재고 증감을 위한 시스템 설계
시스템 설계
케타포는 이러한 패턴들을 조합하여 재고 증감 기능을 개선하기 위해 아래와 같이 시스템을 설계하였다.
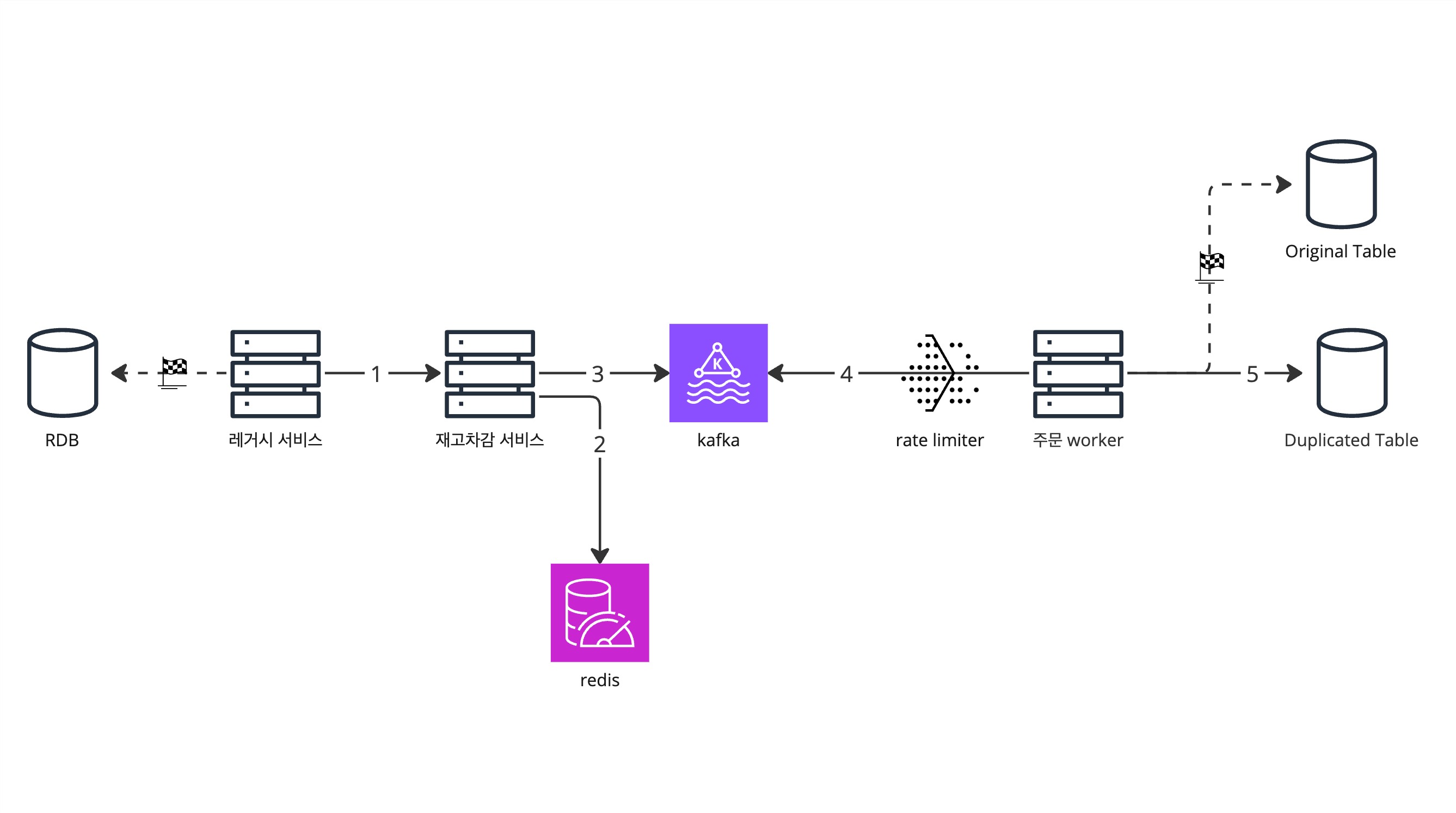
- 먼저 레거시에서 재고 증감 서비스를 분리하고, 레거시는 RDB에 직접 쓰기 요청을 하는 대신 재고 증감 서비스의 API를 호출한다.
- 재고 증감 서비스는 요청을 받으면 인메모리 DB인 redis에서 재고를 업데이트한다.
- 재고 증감 서비스가 kafka로 이벤트를 발행한다.
- 주문 worker는 rate limit을 걸어 kafka 메시지를 컨슘함으로써 부하를 분산시킨다.
- 주문 worker가 RDB를 업데이트한다.
언뜻 보면 단순해보이는 구조이지만 실제로 서비스에 적용시킬 땐 신경써야 할 부분이 상당히 많았다.
- 운영되고 있는 서비스에 영향을 끼치면 안된다. 기능 개선으로 인해 기존 서비스에 장애가 발생하거나 데이터가 틀어지는 상황을 방지해야 한다.
- 데이터의 신뢰성을 보장해야 한다. 재고 데이터는 항상 믿을 수 있어야 한다.
- 동시성을 제어해야 한다. 정합성이 틀어지지 않도록 thread-safe하게 개발해야 한다.
- 성능을 개선해야 한다. 병목을 해소하고 재고 데이터의 최종 일관성을 달성하기까지의 시간을 단축시켜야 한다.
4. 달리는 기차의 바퀴를 교체하기
기존 서비스에 영향을 끼치지 않으면서 점진적으로 개선하기 위해 몇가지 장치가 필요했다.
feature flag
출시 후 장애가 발생하면 빠르게 롤백을 할 수 있어야 한다. 이를 위해 feature flag가 유용하게 사용되었다. 먼저 feature flag를 끄든 켜든 서비스 운영에는 문제가 없도록 시스템을 설계해야 한다. 우리의 경우 feature flag가 켜지면 레거시 대신 주문worker가 RDB를 업데이트하고, feature flag가 꺼지면 레거시가 RDB를 업데이트하도록 구성하였다. feature flag를 쓸 때 주의할 점은, 프로젝트가 점점 복잡해지면 feature flag 또한 따라서 복잡해질 가능성이 있는데 실수로 잘못 켰다가 큰 장애를 유발할 수 있으니 가능하면 단순하게 구성해야 한다는 것이다.
parallel testing
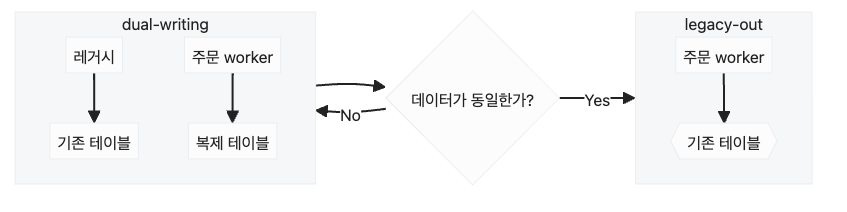
재고는 정합성이 중요한 데이터이다. 기능을 개선했는데 재고가 틀어진다면 개발 비용을 낭비한 것일뿐더러 전사적으로 피해를 끼칠 수 있다. 그래서 새로운 기능으로 바로 전환하기 보다는 일정 기간동안 기존 데이터와 새로운 데이터를 비교하여 검증하는 기간을 가진다. 검증 기간 동안 주문worker는 재고 테이블을 복제한 테이블을 업데이트하고, 레거시 서비스 또한 기존 재고 테이블을 계속해서 업데이트한다. 복제된 테이블과 기존 테이블을 비교하여 데이터가 올바르게 업데이트 되는지 검증하고 RDB가 잘 업데이트 되고 있다면 주문worker가 기존 테이블을 업데이트하도록 한다. 그리고 RDB 데이터와 redis 데이터 또한 비교하여 redis 데이터가 제대로 업데이트되는지 검증한다.
5. 신뢰성 보장
재고 증감 서비스는 다음을 보장해야 한다.
- 주문, 입고와 재고 증감은 원자적으로 실행되어야 한다.
- 똑같은 재고 증감 요청이 중복 반영되지 않는다. 즉, 멱등성이 보장되어야 한다.
- 재고 데이터는 영속적이어야 한다.
원자성 보장
MSA에서 원자성을 보장하기 위해 Saga와 Transactional Out Box 등의 패턴을 활용할 수 있다. 진행중인 프로젝트의 특성에 맞춰 적절한 방법을 선택하면 된다. 이 프로젝트에서는 다행히 코드 실행 순서를 조정하는 것만으로 원자성을 지킬 수 있었다.
1. 주문(취소), 입고와 재고 증감
주문과 입고 데이터는 RDB에 생성된다. 레거시에서 먼저 주문 혹은 입고를 생성하는 쿼리를 실행한 다음 재고 증감 API를 호출하고, 이 코드를 하나의 트랜잭션으로 묶는다. 이렇게 하면 다음과 같이 원자성이 지켜진다.
- 주문 혹은 입고 생성에 실패하면 재고 증감 API가 호출되지 않은 채로 트랜잭션이 롤백된다.
- 재고 증감 API 호출에 실패하면 트랜잭션이 롤백되면서 주문 혹은 입고 생성이 abort된다.
2. redis 업데이트와 kafka 이벤트 처리
먼저 redis를 업데이트한 다음 카프카 메시지를 발행한다. redis 업데이트에 실패하면 kafka 메시지를 발행하지 않는다. kafka 프로듀서는 자체적으로 retry 로직을 실행하기 때문에 메시지 발행을 실패할 경우는 고려하지 않는다. 카프카 리스너(주문worker)에 Dead Letter Topic을 구성하여 컨슘에 실패할 경우 Dead Letter Topic에 메시지가 발행될 수 있도록 한다. Dead Letter Topic의 메시지는 리스너가 처리할 때까지 반복해서 재시도를 하거나 수동으로 처리할 수 있다.
이벤트 중복 컨슈밍 방지
카프카는 메시지가 컨슘되어도 삭제되지 않기 때문에 이벤트가 중복으로 처리될 수 있다. 이를 방지하기 위해 RDB에 processed_events라는 테이블을 만들고 이벤트 ID에 유니크 제약을 걸어 처리된 이벤트를 이 테이블에 저장한다. 이벤트 처리와 처리된 이벤트 저장을 하나의 트랜잭션으로 묶으면 이벤트가 중복으로 컨슘되었을 때 유니크 제약으로 인해 예외가 발생하므로 트랜잭션이 롤백된다.
우리는 Template Method Pattern으로 이를 구현했다. ExactlyOnceEventProcessor라는 추상클래스를 만들고 서비스 클래스들이 이 클래스를 상속하도록 했다. Template Method Pattern을 구현할 땐 구체 클래스가 추상 클래스의 메서드를 호출하지 않도록 주의해야 한다. abstract method를 구현하는 것은 인터페이스에 의존하는 것이지만 메서드를 호출하는 것은 구현에 의존하는 것이기 때문이다. 이 외에도 구현할 수 있는 방법은 많으니 각자 상황에 맞게 구현하면 된다.
@Slf4j
@RequiredArgsConstructor
public abstract class ExactlyOnceEventProcessor<T> {
private final ProcessedEventRepository processedEvents;
@Transactional
public void processExactlyOnce(final Event<T> event) {
if (processedEvents.existsById(event.id())) {
log.warn("이미 처리된 이벤트입니다. {}", event);
return;
}
processedEvents.save(ProcessedEvent.from(event));
process(event);
}
protected abstract void process(final Event<T> event);
}재고 데이터의 영속성 보장
인메모리 DB는 속도가 빠른 대신 데이터가 손실될 가능성이 있다. 이를 염두에 두고 redis 업데이트 로직을 개발해야 한다.
- 먼저 redis에 재고 데이터가 있는지 확인한다.
- 재고 데이터가 있다면 재고 수량을 증감한다.
- 재고 데이터가 없으면 RDB에서 재고 데이터를 읽는다.
- 재고 데이터를 redis에 set하고 증감한다.
코드로는 다음과 같이 구현되었다.
private void increaseStock(final Stocks stocks) {
final Stocks absentStocks = stockSource.increaseStockOrReturnMissing(stocks);
if (absentStocks.isEmpty()) return;
final Stocks stocksWithOldQty = tableStockReader.getOldQty(absentStocks);
stockSource.setAndIncrease(stocksWithOldQty);
}6. 동시성 제어
재고 데이터의 정확도를 높이기 위해서 동시성은 필수적으로 제어해야한다. 멀티스레드 프로그래밍에서 동시성을 고려하는 것은 인간의 직관을 뛰어넘는 사고력을 필요로 한다. 개인적으로는 재고 증감을 개선하면서 가장 어려운 부분이었다.
애플리케이션에서의 read-modify-write 주의
동시성 문제를 일으키는 코드를 가장 쉽게 찾는 법은 read-modify-write의 순서로 작성된 코드를 보는 것이다. read-modify-write 코드는 가독성도 좋고 리팩토링하기도 쉽지만 동시성 문제를 일으킬 수 있다. 다수의 스레드가 동시에 같은 데이터를 읽고 연산을 한 뒤 DB에 쓰면 어떤 연산은 유실되기 때문이다. 재고 증감과 같이 연산의 정확도가 중요한 기능에서는 애플리케이션에서 read-modify-write를 피하고, DB 쿼리를 통해서 업데이트해야 한다.
Redis with Lua
redis 데이터를 원자적으로 연산하기 위해서 lua를 사용하였다. MULTI와 같은 redis 명령어로 트랜잭션을 실행할 수도 있지만 이 경우에는 get으로 조회되는 데이터를 활용해서 연산할 수가 없다. 재고 데이터의 영속성을 보장하기 위한 로직에는 반환값(데이터가 없는 키)이 필요하기 때문에 lua가 유일한 선택지가 되었다. 케타포에서는 다음과 같이 루아 스크립트를 작성하였다.
-- increaseIfExist.lua
local result = {}
for i, key in pairs(KEYS) do
if redis.call('EXISTS', key) == 1 then
-- redis에 재고 정보가 존재하면 재고 수량을 더한다.
redis.call('INCRBY', key, tonumber(ARGV[i]))
else
-- 재고 정보가 존재하지 않으면 키를 반환한다.
table.insert(result, key)
end
end
return result-- setAndIncrease.lua
for i, key in pairs(KEYS) do
local delta = tonumber(ARGV[i])
if redis.call('EXISTS', key) == 1 then
-- redis에 재고 정보가 존재하면 재고 수량을 더한다.
redis.call('INCRBY', key, delta)
else
-- redis에 재고 정보가 존재하지 않으면 기존 재고 정보에 재고 수량을 더한 값을 set한다.
local qty = tonumber(ARGV[#KEYS + i])
redis.call('SET', key, qty + delta)
end
end7. 성능 개선
배치 업데이트
새로운 시스템 설계를 도입하는 것만으로도 애플리케이션 성능은 충분히 좋아졌지만 한가지 문제가 있었다. redis 재고는 준실시간으로 차감되지만 RDB 재고는 rate limiter가 허용하는 만큼의 속도로 차감되기 때문에, 두 데이터가 최종 일관성을 가지기 까지는 최대 6분 정도로 시간이 꽤 걸릴 수 있다는 것이었다. 그래서 다음과 같은 방법으로 RDB 재고 업데이트 로직을 변경하였다.
- 주문worker가 이벤트를 컨슈밍할 때 재고 증감 delta값을 DB에 저장한다.
- 스케쥴러가 5초에 한번씩 delta값들을 집계하여 재고 데이터를 업데이트한다.
위와 같이 변경하면 rate limit을 대폭 늘릴 수 있다. 데이터를 업데이트하지 않고 삽입만 하니 DB lock에서 안전하기 때문이다. 주의할 점은 스케쥴러가 중복 실행되면 안되는 것이다. 분산 시스템으로 구성된 애플리케이션에서 여러 개의 컴퓨팅 리소스가 스케쥴러를 실행한다면 재고증감이 중복 반영된다. 케타포는 ShedLock을 통해서 이를 방지했다.
8. 결과✨
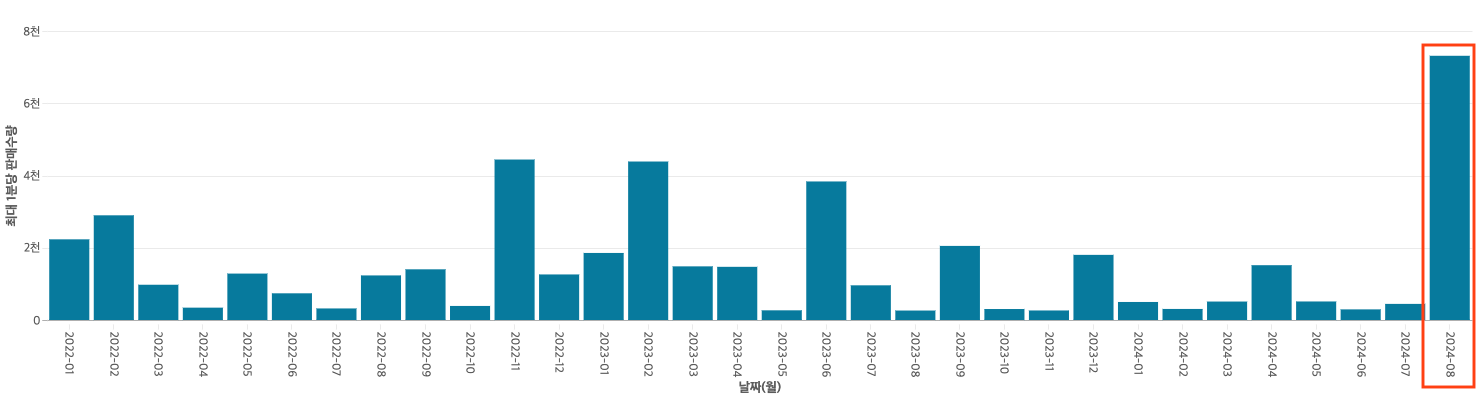
이러한 개선을 통해서 케타포는 순간 판매수량을 대폭 늘릴 수 있었다. 위 그래프는 2022년부터 2024년 8월까지의 최대 1분당 판매수량을 나타내고 있다. 이 프로젝트는 2024년 7월에 마무리 되었고, 2024년 8월에 최대 1분당 판매수량이 대폭 상승한 것을 확인할 수 있다. 이전에는 최대 판매수량이 1분당 약 4000개에 머물렀는데 개선 후에는 1분당 약 8000개를 판매할 수 있게 되었다. 또한 이벤트마다 발생하던 장애도 해소되었다. 2024년 8월 이벤트 당시 모니터링을 했을 때 모든 지표가 안정적이었으므로 8천개 그 이상 또한 충분히 소화할 수 있을 것으로 보인다.
정말 많은 것을 배우고 또 성과를 눈으로 직접 확인할 수 있어서 정말 즐거웠던 프로젝트였다. 프로젝트 당시에는 과제가 너무 어렵게 느껴졌는데, 되돌아보니 많은 성장을 할 수 있을 만큼 적당히 어려운 좋은 과제였던 것 같다. 이 어려운 프로젝트를 주니어가 소화할 수 있도록 프로젝트를 설계하고 태스크를 나눠주신 훌륭한 리더 기원님과, 내가 못하는 부분을 잘 보완해주고 마무리까지 꼼꼼하게 맺어주신 중석님께 감사의 말씀을 전하고 싶다.
함께 프로젝트를 진행한 이중석님의 블로그에서는 이 포스트와는 또 다른 내용을 알 수 있다.
