Backpropagation
- 모델을 학습시키려면 Gradient를 알아야 한다.
- 수치 미분
- 근사한 도함수를 이용하기 때문에 오차가 누적될 수 있다.
- Weight와 Data 변수 개수만큼 계산해야 하기 때문에 비효율적이다.
- 수식을 직접 미분한다.
- 근사하지 않으므로 오차가 없다.
- 함수 값 한 번만 계산하면 된다.
- 하지만 수식에 따라 미분이 어렵다는 단점이 있다.
- Computational graph를 이용해 Divide & Conquer를 수행하면 된다.
Computational Graph
- 계산 과정을 Node와 Edge로 구성된 그래프 자료구조로 나타낸 것
- 국소적 계산을 전파함으로써 최종 결과를 얻는다.
- 중간 계산 결과를 보관할 수 있다.
- 역전파, 연쇄법칙을 통해 효율적인 미분 계산이 가능하다.
Backpropagation 계산 절차
- Input 신호 에 국소적 미분을 곱하여 전달한다.
- 덧셈 노드의 역전파
- Gradient Distributor: Gradient 분배
- 곱셈 노드의 역전파
- Swap multiplier: 교차해서 곱한다.
Multi-layer Perceptron에서의 Backpropagation
One Node per Layer
- Notation
- : l번째 층의 weight scalar
- : l번째 층의 bias scalar
- : l번째 층의 activation scalar
- Assumption
- 은닉층 및 출력층에 Sigmoid 활성함수 사용
- 정답 는 0 또는 1인 Binary Classification
- 오차함수: SSE
- Forward
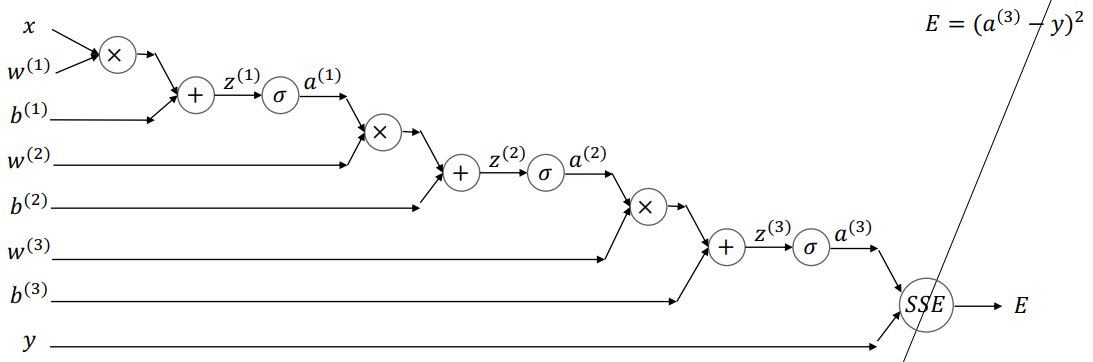
-
Backward
-
는 label이므로 학습 대상이 아니다.
-
Chain Rule에 의해 오차 값이 모든 node에 전달되어 오차에 비례하여 모든 가중치가 갱신된다.
- 의 변화가 에 직접 영향 주는 것은 아니지만 일정 비율 영향을 미친다.
- : 이 바뀔 때 가 변화하는 비율
- 의 변화 의 변화 의 변화 의 변화 의 변화 의 변화 의 변화 의 변화 의 변화 의 변화
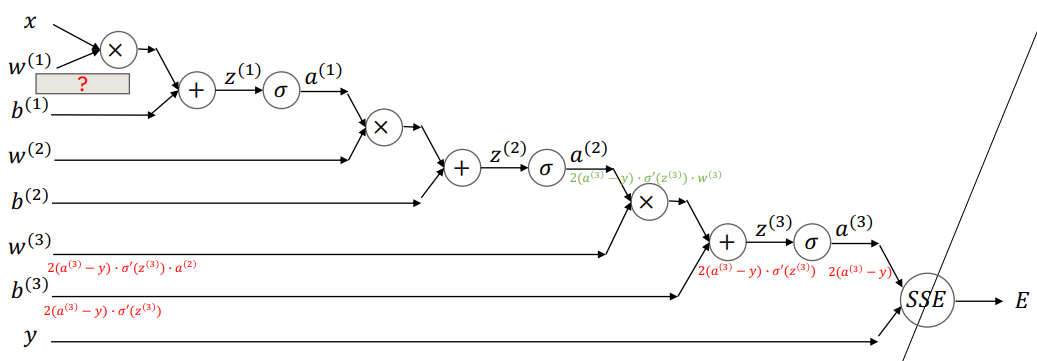
-
Cahin Rule을 적용하면 layer 개수가 아무리 많아도 모든 층에서 가중치에 대한 편미분 값을 구할 수 있다.
-
Few Nodes per Layer
- Notation
- : 이전층 1번 노드와 다음층 2번 노드를 이어주는 번째 층의 weight scalar
- : 번째 층 1번 노드에 대한 편향 값
- : 번째 층 1번 노드에 대한 활성 값
- Assumption
- 은닉층에는 ReLU 활성화함수, 출력층에는 Softmax 함수를 사용한다.
- 오차함수: 교차 엔트로피
-
Forward
- 앞 층 노드 개수 , 뒤 층 노드 개수
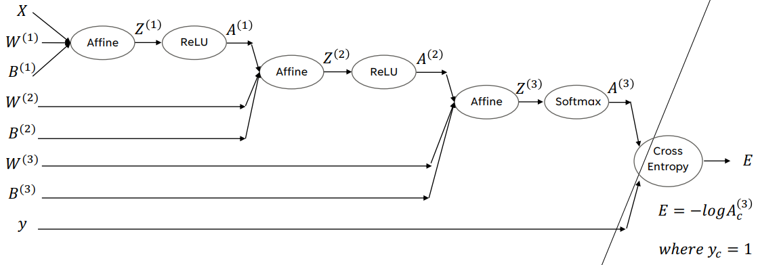
-
Backward
- 매우 복잡한 과정이다.
- Pytorch, tensorflow 등의 프레임워크에 backward pass 코드가 이미 구현되어 직접 계산하지 않아도 된다.
- 매우 복잡한 과정이다.
Generalized Multi-Layer Perceptron
- 입력층: 이미지 (784개 노드)
- 2개의 은닉층 (각 층 노드 16개), ReLU
- 출력층: 10개의 노드 (digit), Softmax
- Forward
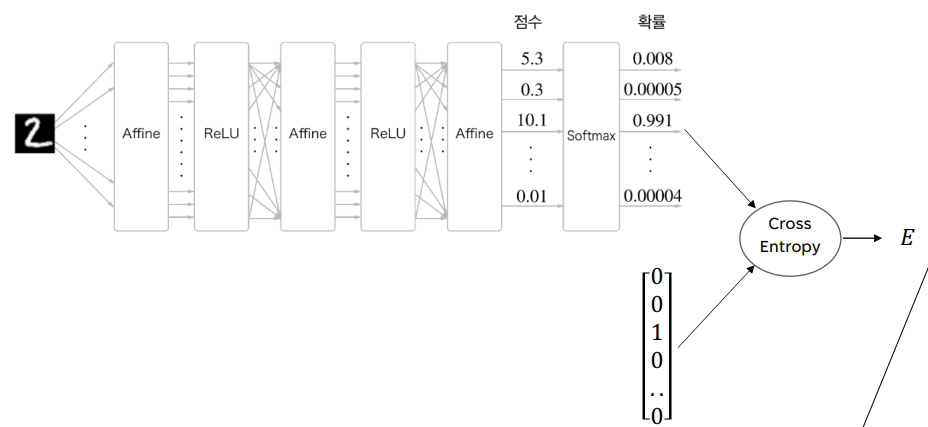
- 총 가중치 (ReLU는 가중치 없음)
- Affine 1:
- Affine 2:
- Affine 3:
- Total: 13002
- 총 가중치 (ReLU는 가중치 없음)
- Backward
- One Node per Layer와 동일한 원리로 진행된다.

Hi, there 👋