Non-linear hypothesis
Non-linear Classification
- 에 대해 비선형적 decision boundary를 구해야 할 때 매우 많은 features 조합이 필요하다.
- logistic regression은 feature의 수가 많아질수록 식을 위해 필요한 항이 매우 많아지고 overfitting이 발생할 수도 있다.
- 입력이 이미지인 경우 pixel 수는 2500, quadratic features만 로 경우가 매우 많아진다.
- 위의 경우 Logistic regression 같은 non-linear classification은 좋은 해결 방법이 아니다.
- 이를 해결하기 위해 더욱 효율적인 neural network가 등장하였다.
Neurons and the brain
Neural Networks
- Origins: 뇌를 모방한 algorithms
- 80~90년대에 광범위하게 사용되었다.
- 90년대 후반부터 덜 사용되지 시작하였다.
- 최근 재기: 많은 영역에서 사용하는 최신 기술
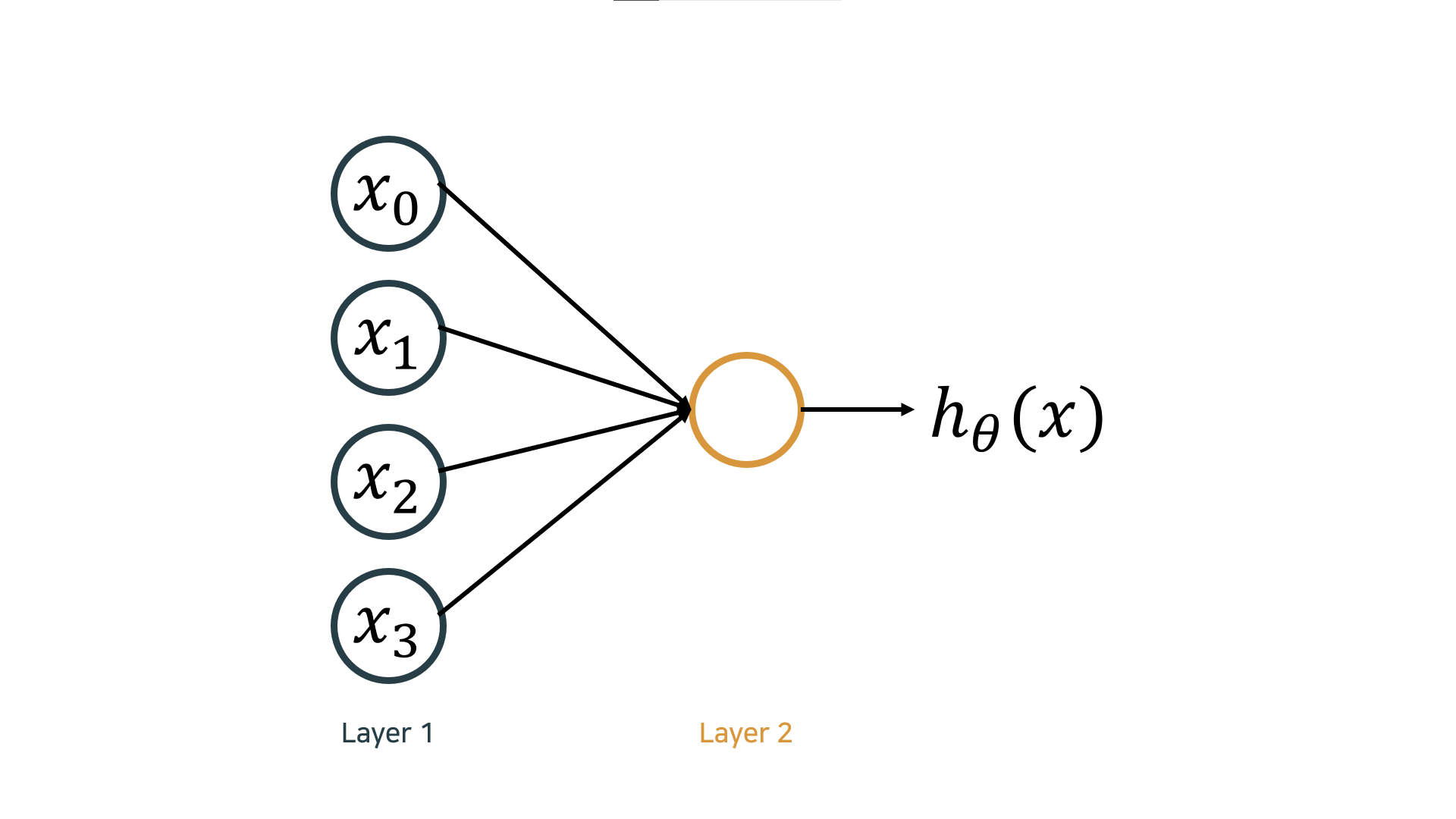
Model representation
Neuron model: Logistic unit
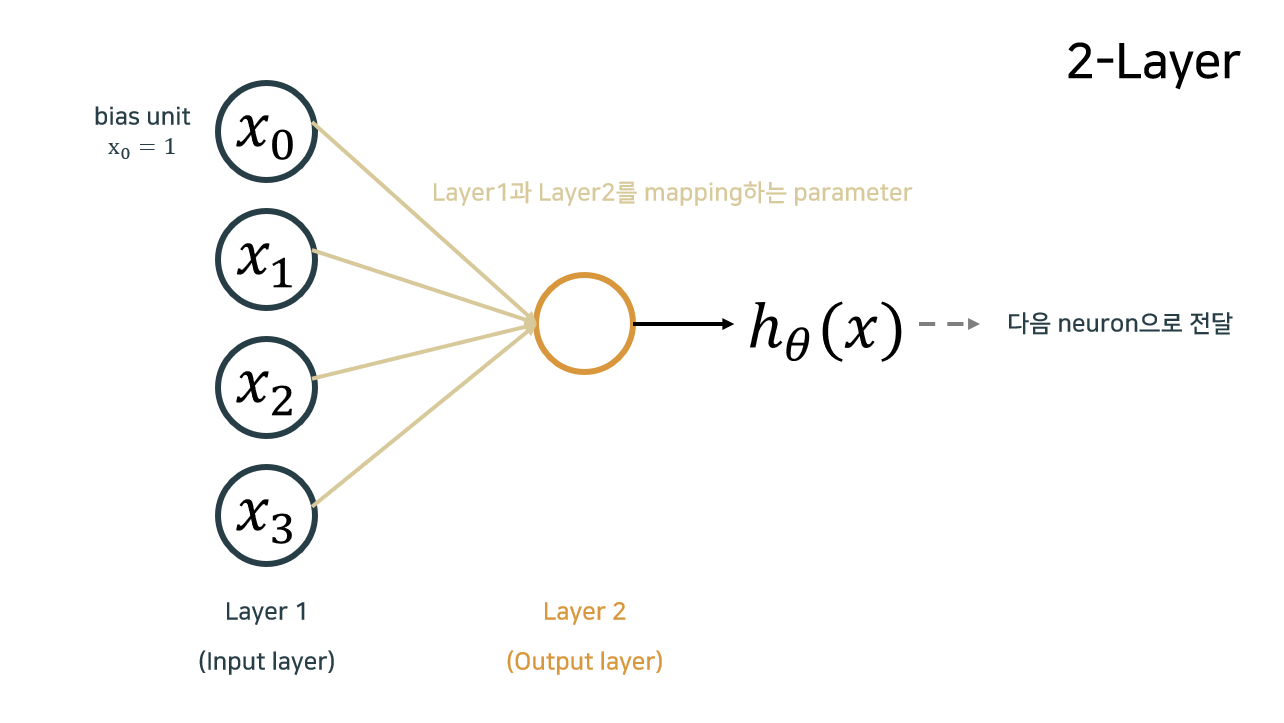
- : 입력 신호 unit, : parameters/weights
- layer: parameter 기준이 아닌 data 기준으로 count
- layer 1: unit 세 개로 이루어진 layer
Neural Network
hiddne layer를 중첩하는 구조이다.
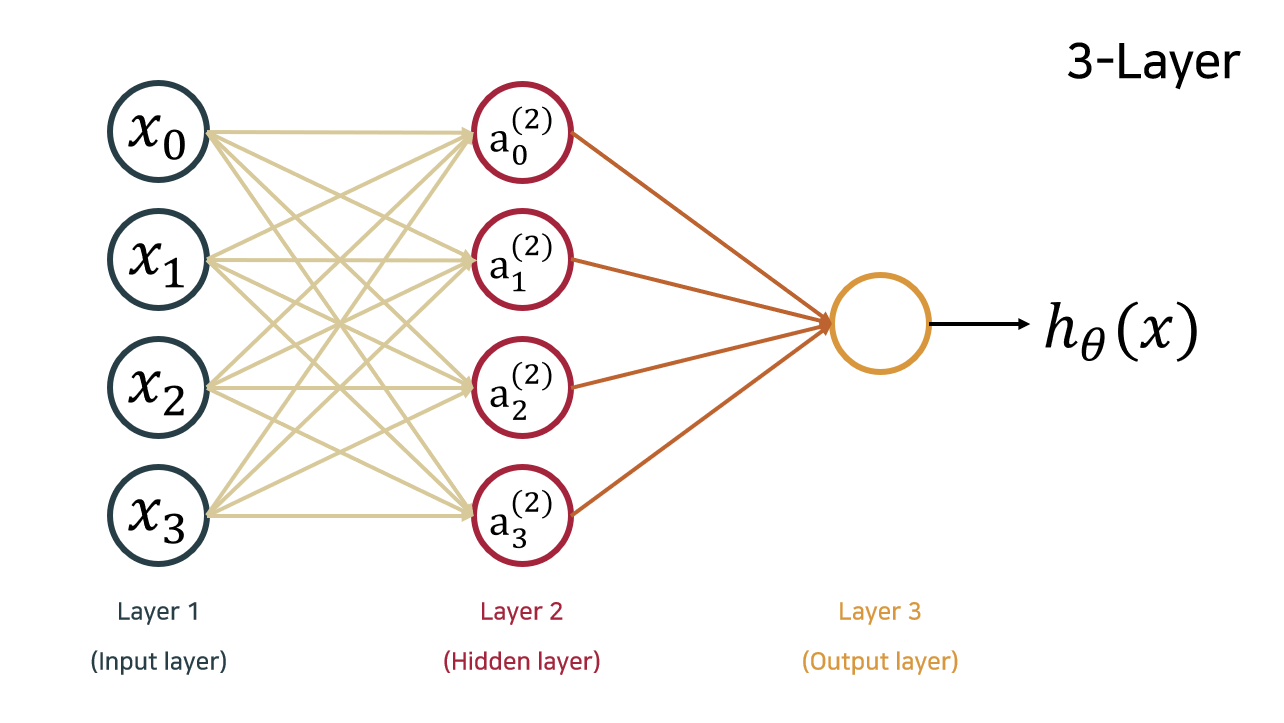
에서 은 연결하지 않는다.
- Hidden layer: 눈에 보이는 input, output layer와 달리 보이지 않는 중간 layer
- : layer 의 unit의 activation
- : layer 와 layer 을 연결하는 mapping matrix
- : non linear activation function
- layer 에 units이 있고, layer 에 units이 있다면
- 의 크기는 이다.
- : 이전 unit의 bias
Forward propagation: Vectorized implementation
- Forward propagation: 연산 이후 다음 layer로 전달하는 과정
- 학습 시에는 backward propagation
- linear parameter 를 아무리 중첩하여도 linear layer 하나 곱한 것과 동일한 효과
Neural Network learning its own features
data 를 통해 를 구해야 한다.
- 올바른 를 구하기 위해서는 좋은 data가 필요하다.
Examples and intuitions
Non-linear classification example: XOR/XNOR
, 가 0 or 1(binary)
-
-
일차함수로 구분할 수 없다.
y 0 0 1 0 1 0 1 1 0 1 1 1
-
-
Simple example: AND
-
-
0 0 0 1 1 0 1 1
-
Example: OR function
-
-
0 0 0 1 1 0 1 1
-
XOR function - Neural Network
| 0 | 0 | 0 | 1 | 1 |
| 0 | 1 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 |
| 1 | 1 | 1 | 0 | 1 |
Multi-class classification
- logistic regression의 경우 binary classification N개 중 가장 확률이 큰 값을 prediction으로 출력하였다.
- Neural network의 경우 단 하나의 모델로 표현 가능하다.
one-hot encoding
- when answer 0
- when answer 1
- when answer 0

Hi, there 👋