Reinforcement Learning
강화학습의 등장
- 지금까지의 학습 패러다임은 학습 데이터와 정답 라벨 쌍이 주어진 상태에서 지도학습으로 이루어졌다.
- 바둑의 경우 현재 순간에 내리는 결정에 대해 정해진 정답이 없다. 또한 계속해서 변하는 환경 속에서 최선의 결정을 내려야 한다.
강화학습이란
- 사람의 학습 과정
- 시행착오를 거치면서 처한 상황과 상호작용하며 학습한다.
- 인간의 뒤집기, 걸음마, 자전거타기는 지도학습에 해당하지 않는다.
- 강화학습의 핵심 연산
- : 시점에서 상태(state)
- : 시점에서 행동(action)
- 에피소드: 상태 에서 행동 를 취하면 다음 상태 로 전환하고 보상 을 받는다.
- 강화학습의 원리
- Agent가 Environment와 상호작용하면서 학습한다.
아이가 지표면과 상호작용하며 걸음마를 배우는 것- Agent: 행동을 결정
- Environment: 상태 전환과 보상값 결정
- 학습 목표: 각 상태에서 어떤 행동을 취하는 것이 최적인지, 최대의 보상을 얻을 수 있는지 학습하는 것(policy)
- Agent가 Environment와 상호작용하면서 학습한다.
- Examples
- 바둑 (알파고)
- Agent: 알파고 (바둑을 두는 주체)
- Environment: 바둑판 상황, 이세돌 (상대방)
- State: 바둑판 상황
- Action: 자신의 차례에 다음 수를 둘 위치(가로, 세로 좌표)
- Reward: 승/패
- 스타크래프트 (알파스타)
- Agent: 알파스타
- Environment: 맵의 상태, 상대 플레이어
- State: 맵의 상태 (점유)
- Action: 마우스 이동, 마우스 클릭, 키보드 타이핑
- Reward: 승/패
- 바둑 (알파고)
Q-Learning
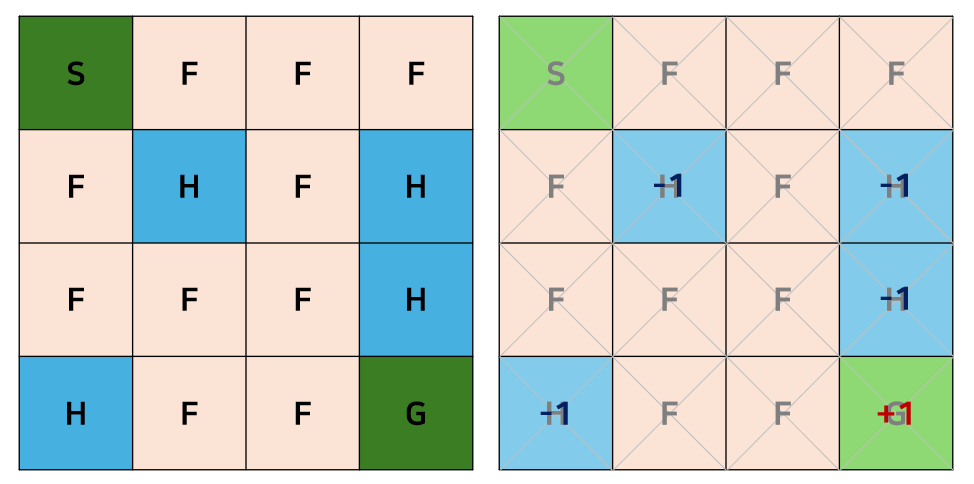
Frozen Lake Example
- 목표: Agent가 시작점에서부터 빙판길을 따라 목적지까지 도착해야 한다.
- State: , 총 16개
- Action: 상/하/좌/우로 이동
- Reward: Goal에 도착하면 점, Hole에 닿으면 점
- Agent는 전체 지도를 알지 못하고 현재 상태만 알고 있다.
- 최적의 정책을 찾는 방법
Q-Function
- : 상태 에서 행동 를 취했을 때 얼마큼의 보상을 받을 수 있는지 알려주는 역할을 하는 함수
- 특정 상태 에서 값이 최대인 행동을 취하는 정책 이 최적의 정책이다.
- 이때 는 상/하/좌/우로 이동하는 것
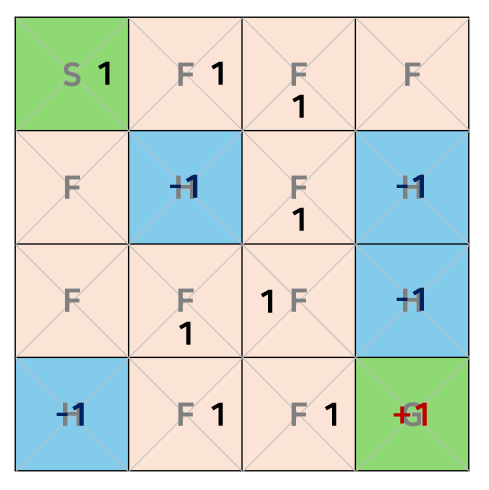
- 함수를 구하는 방법 Q-Learning
Q-Learning
- 에이전트가 상태 에서 행동 를 취하면 보상 을 받고 상태는 으로 바뀐다.
- 현재 상태에서 값은 모르지만 미래 의 값을 알고 있다고 가정하면 다음 수식을 반복하며 값을 학습할 수 있다.
- 현재에 행동 를 취하여서 얻는 보상과 미래에 얻을 수 있는 최대 값
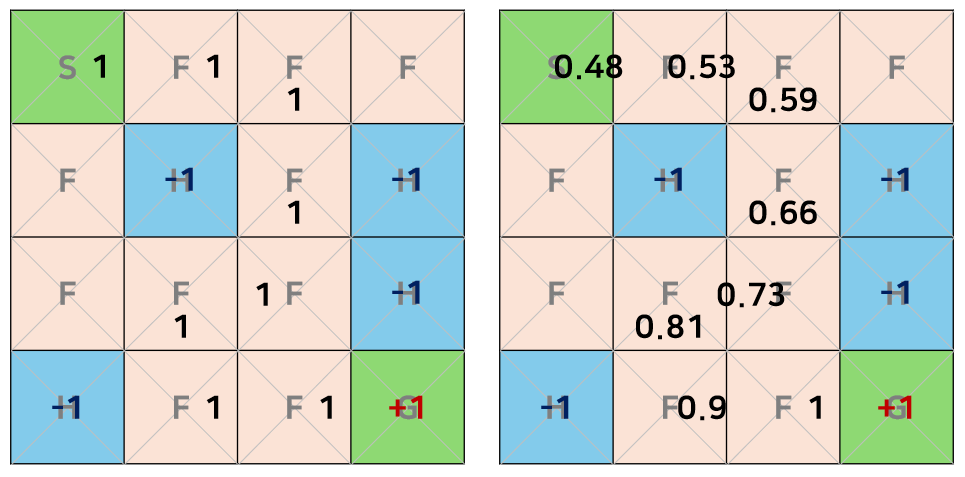
- 문제점
- 계속 같은 경로로만 이동하게 된다.
- 방식 도입
- 의 확률로 값이 최대인 행동을 취한다.
- 의 확률로는 랜덤한 행동을 취한다.
- table이 비어있는 상태에서 값은 처음에는 작은 값이었다가 시간이 지날수록 점점 커진다.
- 경로가 너무 길어질 수 있다.
- value update 공식에 discount factor (약 0.9)를 도입한다.
- 빨리 reward를 획득하는 짧은 경로에 대한 advantage를 부여할 수 있다.
- 경로가 길수록 가 곱해지는 횟수가 늘어나기 때문에 경로가 짧을수록 유리하다.
- 고전 머신러닝과 유사하다.
- 계속 같은 경로로만 이동하게 된다.
Deep Q-Network
- Frozen Lake example의 state는 16개였으나, state와 action의 개수가 많아지면 table로 관리할 수 없다.
- 함수를 신경망으로 근사하여 해결한다.
- Q-Learning:
- DQN:
- Multi-layer perceptron
- 입력 노드: state 정보
- 출력 노드: 취할 수 있는 개별 action에 대한 값
- CNN
- 게임 화면을 CNN읠 input으로 넣어 state 정보를 CNN이 자동으로 추출하는 DeepMind(구글)
- 49개의 게임 중 43개에서 기존 머신러닝 알고리즘 성능을, 29개에서 전문가의 점수를 능가하였다.

Hi, there 👋