Generative AI
- 정의: 텍스트, 오디오, 이미지, 동영상 형태의 새로운 컨텐츠를 생성하도록 설계된 인공지능 모델
Large Language Model
- ChatGPT: Generative Pre-trained Transformer
- Generative: 텍스트를 생성하는 과정
- 문장은 다음 단어 예측의 연속으로 생각할 수 있다.
- 현재까지의 문장을 입력으로 받아 dictionary 내의 각 단어가 다음 이어질 단어가 될 가장 적합할 확률을 softmax로 예측한다.
- 전체 단어 중에서 가장 높은 확률의 단어를 선택한다.
- Generator는 분류 softmax의 연속이다.
- Pre-Trained
- 인터넷의 방대한 텍스트 데이터로 large language model을 학습시킨다.
- 다음 단어를 예측하는 것이기 때문에 정답 label 지정이 필요 없다.
- 손실함수는 전체 dictionary 내 단어들을 대상으로 cross entropy loss를 사용한다.
- 인터넷 상 텍스트 데이터는 응답용 텍스트가 아니기 때문에 Reinforcement Learning from Human Feedback을 통해 LLM에 추가적인 튜닝을 수행해야 한다.
- 튜닝을 거치면 "더 필요한 것 있으면 ..."과 같은 응답 텍스트로 조정된다.
- Transformer
- 문장 전체 단어를 한번에 입력으로 받아 각 단어 간의 상관관계를 모델링하는 어텐션 메커니즘
- 문맥 정보로 강화된 feature기반으로 최종 예측을 수행한다.
Diffusion Model
- Diffusion: 확산
- 공기 중에 기체가 퍼지는 현상
- 수학적 모델링: 각 분자는 정규분포에 따라 매 순간 움직인다.
Image Diffusion
- 이미지에 대한 확산 현상 모델링
- 픽셀 하나를 분자로 본다.
- 각 개별 픽셀마다 정규분포를 따르는 노이즈를 더한다.
- 각 개별 픽셀마다 노이즈는 모두 독립적으로 적용된다.
- 충분히 긴 시간동안 노이즈를 더하는 과정을 반복하다보면 최종적으로 원본 이미지를 알아볼 수 없는 완전한 noise 이미지가 된다.
- 이 과정을 역으로 계산하면 완전한 noise 이미지로부터 원본 이미지를 복원할 수 있다.
- Diffusion Model Training
- UNet 구조 (convolution & Up-convolution): 입력과 출력의 사이즈가 동일하다.
- 임의의 시점의 이미지 및 시점 정보를 입력으로 받아 각 픽셀별로 더해진 노이즈를 예측하도록 학습한다.
- 모델이 예측한 노이즈와 실제 노이즈의 오차제곱합 손실함수
- 와 를 입력으로 받으면 실제 노이즈(정답)은
- Denoising Unet: 입력으로 받은 이미지에서 계산한 노이즈를 빼면 한 step 덜 noisy한 이미지로 변환할 수 있다.
- 자기 자신으로 계산하기 때문에 정답 label 지정할 필요가 없다.
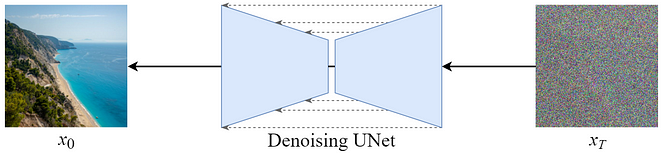
- Diffusion Model Inference
- 랜덤한 노이즈 이미지를 입력으로 넣고 노이즈 예측과 노이즈 뺄셈을 회 반복하면 이미지를 생성할 수 있다.
- Diffusion Model에 생성할 이미지에 대한 텍스트 정보를 추가로 넣으면 원하는 이미지를 생성할 수 있다.
- Condition은 caption으로 입력해서 LLM에 넣고 LL은 diffusion model 중간에 들어간다.(multi modal)


Hi, there 👋