
BERT란?
BERT는 2018년 등장과 동시에 수많은 NLP 태스크에서 최고 성능을 보여주며 NLP의 한 획을 그은 모델이다.
이전 글에서 알아본 트랜스포머를 이용해 구현된 위키피디아와 같은 레이블이 없는 텍스트 데이터로 사전 훈련된 언어 모델이다.
BERT가 높은 성능을 낸 이유는 레이블이 없는 방대한 데이터로 사전 훈련된 모델로 레이블이 있는 다른 태스크에서 추가 훈련과 하이퍼파라미터를 재조정하여 사용하여 성능이 높게 나온 기존 사례를 참고했기 때문이다.
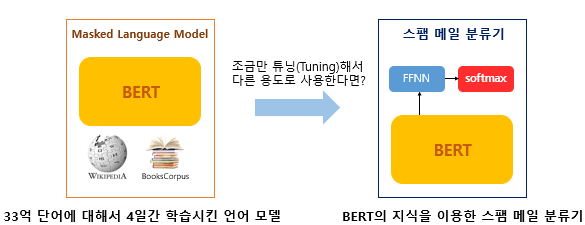
다른 태스크에 대해 파라미터 재조정을 위한 추가 훈련 과정을 파인 튜닝(Fine-tuning)이라고 한다.
BERT 구조
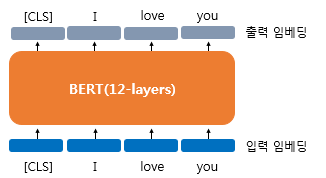
BERT의 기본 구조는 트랜스포머의 인코더를 쌓아올린 구조이다. base 버전은 레이어를 12개 쌓았고 large버전은 24개를 쌓았다.
버트 베이스 버전은 보다 먼저 등장한 Open AI GPT-1과 성능을 비교하기 위해 크기를 동일하게 설계했다. 반면 버트 라지는 최대 성능을 보여주기 위함이며 버트가 세운 기록들 대부분이 라지 모델의 기록이다.
이 글에서는 버트 베이스 모델을 기준으로 설명한다.
버트의 입력은 다른 딥러닝 모델들과 마찬가지로 임베딩 층을 지난 임베딩 벡터들이다.
을 768로 정의하므로 모든 단어 벡터들은 765차원의 임베딩 벡터가 되어 입력으로 사용된다.
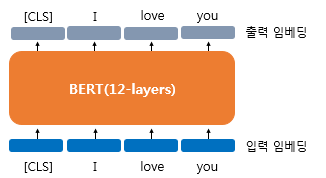
버트는 내부적인 연산을 거치고 각 단어에 대해 768차원의 벡터를 출력한다. 위 그림은 CLS, I, love, you라는 4개의 벡터를 입력받아서(입력 임베딩) 768차원의 4개의 벡터를 출력하는 모습(출력 임베딩)을 보여준다.
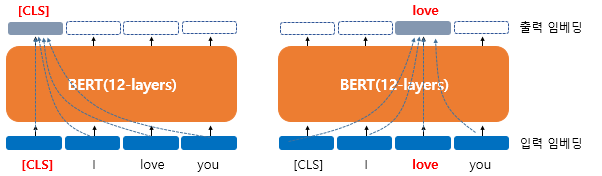
버트의 연산을 거치고 나서의 출력 임베딩의 각 단어들은 문장의 모든 단어 벡터를 참고한 후 문맥 정보를 가지게 된다.
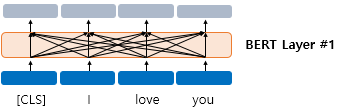
하나의 단어가 모든 단어를 참고하게 하는 연산은 12개의 층에서 모두 이루어진 후 출력 임베딩을 얻게 된다. 첫번째 층의 출력 임베딩은 두번째 층의 입력 임베딩이 된다.
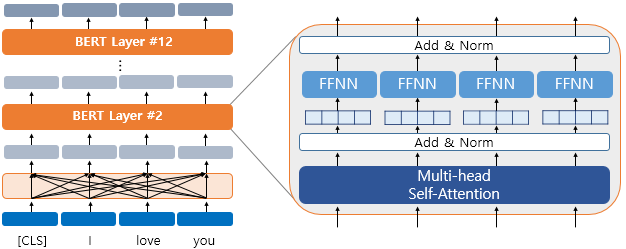
버트는 이전 글에서 다룬 셀프 어텐션을 수행하여 모든 단어들을 참고하여 문맥을 반영한다. 각 층마다 멀티 헤드 어텐션과 포지션 와이즈 FFNN을 수행한다.
서브워드 토크나이저
버트는 서브워드 토크나이저로 WordPiece를 사용하는데 이는 단어보다 더 작은 단위로 쪼개는 토크나이저이다.
서브워드 토크나이저는 기본적으로 자주 등장하는 단어는 그대로 단어 집합에 추가하고 자주 등장하는 단어가 아니면 더 작은 단위인 서브워드로 분리되고 그 서브워드들이 단어 집합에 추가된다는 아이디어이다.
이렇게 단어 집합이 만들어지면 이 단어집합을 바탕으로 토큰화를 진행한다.
<토큰화 수행 방식>
준비물 : 이미 훈련 데이터로부터 만들어진 단어 집합
-
토큰이 단어 집합에 존재한다.
👉 해당 토큰을 분리하지 않는다. -
토큰이 단어 집합에 존재하지 않는다.
👉 해당 토큰을 서브워드로 분리한다.
👉 해당 토큰의 첫번째 서브워드를 제외한 나머지 서브워드들은 앞에 "##"를 붙인 것을 토큰으로 한다.
예를 들면 입력 단어가 단어 집합에 존재하지 않는 단어라면 입력 단어를 더 작은 단위인 서브워드로 쪼개려고 시도한다.
만약 단어 집합에 쪼개려는 서브워드들이 존재한다면 입력 단어는 서브워드들로 쪼개지게 된다.
첫번째 서브워드를 제외하고 ##을 붙이는 이유는 나중에 다시 쉽게 복원하기 위해서이다.
ex) embeddings 👉 em, ##bed, ##ding, ##s
이때 서브워드 토크나이저가 아닌 토크나이저라면 Out of Vocabularya 에러가 발생하게 된다.
포지션 임베딩
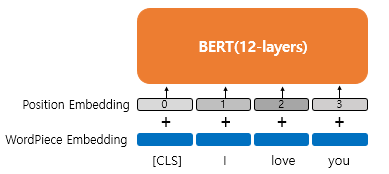
트래랜스포머에서는 포지셔널 인코딩 방법을 사용해서 위치 정보를 표현하지만 버트는 학습을 통해서 얻는 포지션 임베딩(Position Embedding)이라는 방법을 사용한다.
위 그림에서 WordPiece Embedding은 위에서 언급했었고 입력으로 사용된다. 여기에 포지션 임베딩을 통해 위치 정보를 포함시켜야 한다.
포지션 임베딩은 위치 정보를 위한 임베딩 층을 하나 더 사용한다. 예를들어 문장의 길이가 4라면 4개의 포지션 임베딩 벡터를 학습시킨다. 그리고 포지션 임베딩 벡터를 더해준다.
사전 훈련
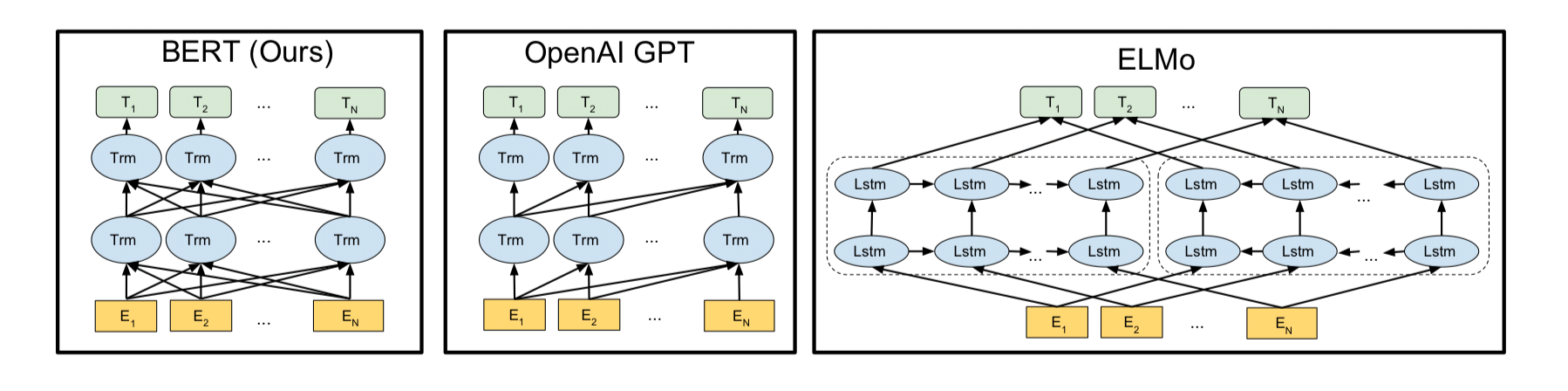
위 그림에서 ELMo는 정방향 LSTM과 역방향 LSTM을 각각 훈련시키는 방법으로 양방향 언어 모델을 만들었다. Open AI GPT-1은 트랜스포머(Trm)의 디코더를 이전 단어들로부터 다음 단어를 예측하는 방식으로 단방향 언어 모델을 만들었다.
버트의 사전훈련 방식은 두가지로 나뉘는데 첫번째는 마스크드 언어 모델(Masked Language Model), 두번째는 다음 문장 예측(Next sentence prediction, NSP)이다. 버트는 마스크드 언어 모델로 양방향성을 얻은 양방향 언어 모델이다.
마스크드 언어 모델
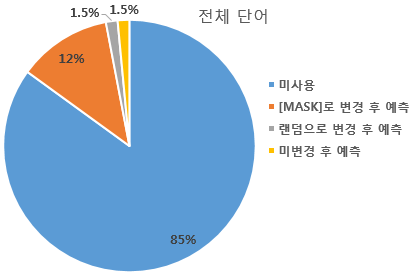
버트는 사전 훈련을 위해 입력 문장의 15% 중에 80%는 단어를 마스킹하고, 10%는 다른 랜덤한 단어로 바꾸고 나머지 10%는 그대로 둔다. 그리고 각각을 예측하게 한다.
입력의 15%를 제외한 85%는 마스크드 언어 모델의 학습에 사용하지 않는다.
예를 들면,
1. 'My cat is cute. he likes playing'
2. ['my', 'dog', 'is' 'cute', 'he', 'likes', 'play', '##ing']
1번 문장을 마스크드 언어 모델에 학습시킬 때 전처리와 서브워드 토크나이저에 의해 2번처럼 토큰화 되어 입력에 사용된다.
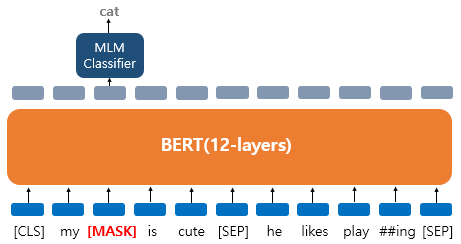
그리고 위 그림은 dog가 MASK로 변경됐을 때 버트가 원래 단어를 맞추려는 모습이다.
dog 위치의 출력층 벡터만 사용되고 다른 위치의 벡터들은 예측과 학습에 사용되지 않는다. 이는 버트의 손실 함수에서 다른 위치에서의 예측은 무시한다는 뜻이다.
출력층은 예측하기 위해 단어 집합 크기만큼의 밀집층과 소프트맥스 함수를 사용하는 1개의 층으로 원래 단어가 무엇인지 맞추게 된다.
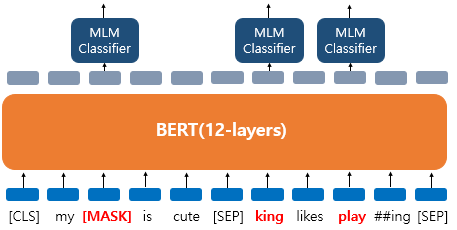
추가적으로 위 그림과 같이 데이터셋이 변경된다면 랜덤한 단어 king으로 바뀐 토큰의 원래 단어가 무엇인지, 변경되지 않은 단어 play에 대해서도 원래 단어가 무엇인지 예측해야 한다.
다음 문장 예측
BERT는 마스크드 언어 모델말고도 다음 문장 예측이라는 태스크도 학습한다.
두개의 문장을 주고 이 문장이 이어지는 문장인지 아닌지를 맞추는 방식으로 훈련한다.
50:50 비율로 어지는 문장과 랜덤으로 이어붙인 문장 두개를 주고 훈련시킨다. 이어붙인 문장을 각각 Sentence A와 B라고 하자.
-
이어지는 문장의 경우
Sentence A : The man went to the store.
Sentence B : He bought a gallon of milk.
Label = IsNextSentence -
이어지는 문장이 아닌 경우 경우
Sentence A : The man went to the store.
Sentence B : dogs are so cute.
Label = NotNextSentence
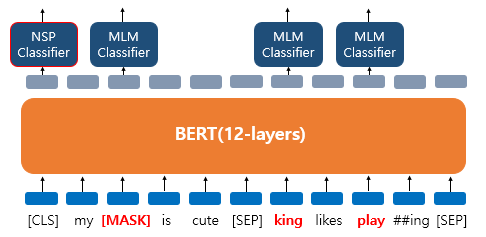
버트의 입력으로 넣을 때 모든 문장의 끝나는 부분에 SEP라는 특별 토큰을 넣어 구분한다.
그리고 실제 이어지는 문장인지 아닌지 CLS 토큰의 위치의 출력층에서 이진 분류 문제를 풀도록 한다. CLS 토큰은 버트가 분류 문제를 풀기 위해 추가된 특별 토큰이다.
다음 문장 예측 테스크를 학습하는 이유는 BERT가 풀고자 하는 태스크 중 QA(Question Answering)와 NLI(Natural Language Inference)와 같이 두 문장의 관계를 이해하는 것이 중요한 태스크가 있기 때문이다.
마스크드 언어 모델과 다음 문장 예측은 따로 학습되지 않고 loss를 합하여 동시에 학습된다.
세그먼트 임베딩
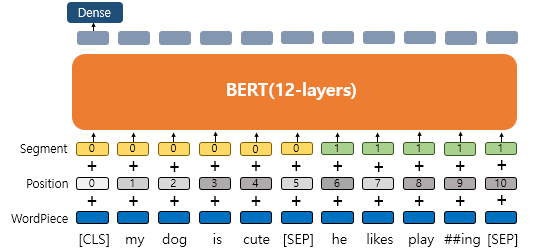
BERT는 문장 구분을 위해서 세그먼트 임베딩이라는 또 다른 임베딩 층을 사용한다.
첫번째 문장에는 Sentence 0, 두번째 문장에는 Sentence 1 임베딩을 더해주는 방식이고 임베딩 벡터는 두개만 사용된다.
결론적으로 BERT는 총 3개의 임베딩 층이 사용됩니다.
WordPiece Embedding: 실질적인 입력이 되는 워드 임베딩. 임베딩 벡터의 종류는 단어 집합의 크기로 30,522개Position Embedding: 위치 정보를 학습하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 길이인 512개Segment Embedding: 두 개의 문장을 구분하기 위한 임베딩. 임베딩 벡터의 종류는 문장의 최대 개수인 2개
BERT 파인 튜닝
파인 튜닝은 사전학습 된 모델에 우리가 풀고자 하는 태스크의 데이터를 추가로 학습시켜 테스트하는 단계다.
BERT를 사용하는 유형을 알아보자.
하나의 텍스트에 대한 텍스트 분류 유형(Single Text Classification)
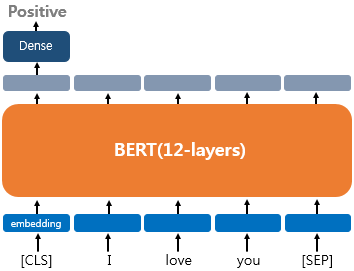
첫번째 유형은 하나의 문서에 대한 텍스트 분류 유형이다.
예를 들면 영화 리뷰 감성 분류, 로이터 뉴스 분류와 같이 입력된 문서에 대해 분류를 하는 유형이다.
문서의 시작에 CLS 토큰을 입력하고 CLS 토큰 위치의 출력층에서 FC layer를 추가하여 분류에 대한 예측을 하게 된다.
하나의 텍스트에 대한 태깅 작업(Tagging)
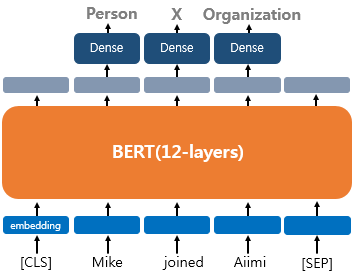
두번째 유형은 태깅 작업이다.
대표적으로 각 단어에 품사를 태깅하는 품사 태깅, 개체명을 인식해 태깅하는 개체명 인식 작업이 있다.
출력층에서 입력 텍스트의 각 토큰의 위치에서 FC layer를 사용하여 분류에 대한 예측을 한다.
텍스트의 쌍에 대한 분류 또는 회귀 문제(Text Pair Classification or Regression)
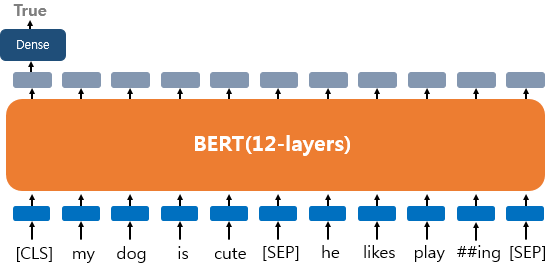
BERT는 텍스트 쌍을 입력으로 하는 태스크도 풀 수 있다. 대표적으로 자연어 추론(Natural language inference)이 있다.
자연어 추론이란 두 문장이 주어졌을 때 하나의 문장이 다른 문장과 논리적으로 어떤 관계가 있는지 분류하는 것이다. 유형으로 모순 관계(contradiction), 함의 관계(entailment), 중립 관계(neutral)가 있다.
이런 태스크의 경우 입력 텍스트가 두개이기 때문에 두 텍스트 사이에 SEP 토큰을 추가하고 Sentence 0과 1 임베딩을 하는 두 개의 임베딩을 사용하여 두 텍스트를 구분한다.
질의 응답(Question Answering)
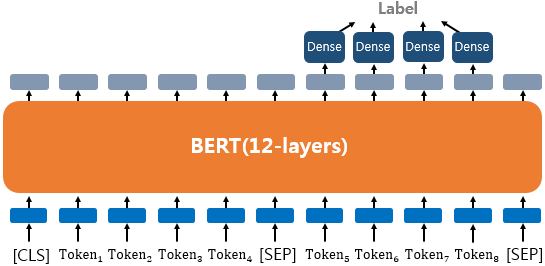
텍스트 쌍을 입력받는 태스크는 QA(Question Answering)도 있다.
BERT로 QA를 풀기 위해서 질문과 본문 두개의 텍스트를 입력해야 한다. 대표적인 데이터셋으로 SQuAD(Stanford Question Answering Dataset) v1.1이 있다. 질문과 본문을 입력받으면 본문의 일부를 추출해서 질문에 답변한다.
어텐션 마스크
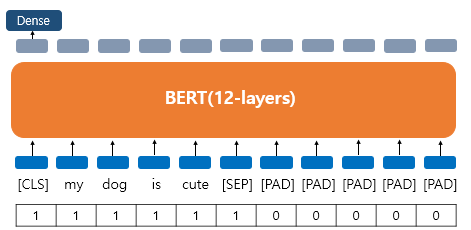
BERT는 어텐션 마스크라는 추가적인 시퀀스 입력이 필요하다.
어텐션 마스크는 BERT가 어텐션 연산을 할 때 패딩 토큰에 대해 불필요한 연산을 하지 않게 실제 단어와 패딩 토큰을 구분할 수 있게 알려주는 입력이다.
실제 단어인 경우 1을 가지고 패딩 토큰일 경우 0을 갖는다. 0이면 연산하지 않도록 마스킹을 하게 된다.
정리
BERT는 Google에서 개발한 자연어 처리 모델이다. 이 모델은 문맥을 양방향으로 이해할 수 있다는 점에서 기존 모델들과 차별화된다. BERT는 단어의 앞뒤 문맥을 동시에 고려하여 단어의 의미를 더 정확히 파악할 수 있다. 사전 학습 단계에서 "마스크된 언어 모델(Masked Language Model)"과 "다음 문장 예측(Next Sentence Prediction)"이라는 두 가지 독특한 학습 방식을 사용한다. 이를 통해 단어의 의미를 추론하고, 문장 간 관계를 학습하게 된다. 이렇게 사전 학습된 BERT는 다양한 자연어 처리 작업에 적용되기 위해 추가 학습 과정을 거치게 되는데, 이를 파인튜닝(Fine-tuning)이라고 한다. 문서 분류, 감성 분석, 질의응답 등 여러 NLP 응용 분야에서 BERT는 기존 모델 대비 뛰어난 성능을 보여주고 있다.
마무리
버트에 대해 공부와 정리를 해봤다. 다음글은 GPT로 돌아오겠다!
레퍼런스
