
YOLO란?
YOLO는 딥러닝 기반 객체 탐지 알고리즘으로, 이미지를 단 한 번 처리해 객체의 위치와 종류를 빠르게 예측하는 기술이다.
"한 번만 본다"는 이름처럼 이미지를 한 번의 패스로 처리해 실시간 애플리케이션에 적합하다.
이 글에서는 YOLO의 작동 원리부터 장단점, 그리고 학습 방법까지 알아본다.
1. YOLO의 특징과 작동 원리
(1) 기존 방식과의 차이점
기존 방식(예: R-CNN 계열): 이미지의 영역을 잘라내거나 제안(Region Proposal)한 후, 각 영역을 탐지하는 단계적 접근 방식
YOLO: 이미지를 전체적으로 보고, 단일 신경망에서 객체 탐지와 분류를 동시에 수행한다
(2) 작동 원리
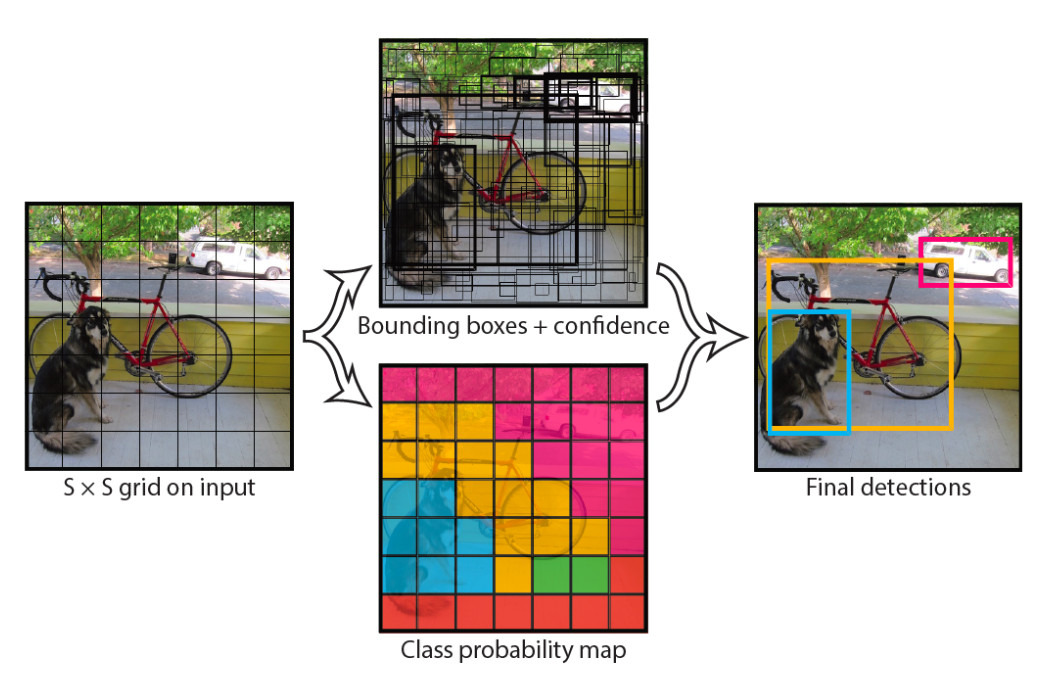
1.이미지 분할
이미지를 S×S 크기의 그리드로 나눈다
각 셀이 객체 중심(center)이 포함되어 있다면 해당 셀이 탐지 역할을 맡는다
2.예측값 출력
각 그리드 셀은 다음 정보를 예측한다
👉Bounding Box: 객체 위치를 나타내는 사각형(좌표와 크기)
👉객체 확률(Confidence Score): 해당 박스가 실제 객체를 포함할 확률
👉객체 클래스: 탐지된 객체의 종류(예: 고양이, 강아지)
3.결과 조정
신뢰도가 낮은 박스는 제거한다
중복 박스는 NMS(Non-Max Suppression)로 처리한다
2. YOLO의 장단점
(1) 장점
👉빠른 속도
단일 네트워크로 모든 작업을 수행하므로 실시간 탐지가 가능.
👉전체 맥락 활용
이미지 전체를 고려해 탐지하므로 배경과 객체의 관계를 잘 이해.
👉쉽게 확장 가능
데이터셋만 변경하면 다양한 객체 탐지에 활용 가능.
(2) 단점
👉소형 객체 탐지 어려움
작은 객체는 그리드 셀의 크기 제약 때문에 탐지 정확도가 떨어질 수 있다
👉복잡한 장면에서의 한계
객체가 겹치거나 밀집된 경우 신뢰도가 낮아질 수 있다
👉고정된 출력 구조
바운딩 박스 수가 제한적이어서 많은 객체가 있는 이미지에는 적합하지 않을 수 있다
3. YOLO 학습 및 활용 방법
(1) 필요한 도구
딥러닝 프레임워크: PyTorch, TensorFlow 등
데이터셋: COCO, Pascal VOC, 사용자 정의 데이터셋 등
(2) 학습 단계
👉데이터 준비
라벨링 툴(예: LabelImg)로 바운딩 박스와 클래스 정보를 설정
👉YOLO 모델 다운로드
최신 버전(YOLOv5, YOLOv8 등) 선택
👉하이퍼파라미터 설정
학습률, 배치 크기 등 최적화
👉학습 및 평가
GPU를 사용해 학습 속도를 높이고, 모델의 성능(정확도, 속도 등)을 평가
(3) 간단한 실습 코드 (PyTorch)
#YOLOv8 모델 다운로드 및 학습
from ultralytics import YOLO
#모델 로드
model = YOLO("yolov8n.pt") # YOLOv8 기본 모델
#사용자 데이터셋으로 학습
model.train(data="custom_data.yaml", epochs=50, imgsz=640)
#이미지에서 탐지
results = model.predict(source="test_image.jpg", save=True)4. YOLO의 발전
YOLO는 계속 발전하며 다양한 버전이 등장했다.
YOLOv1👉최초 버전으로 단순하지만 혁신적
YOLOv2👉정확도를 높이기 위해 앵커 박스(anchor box) 도입
YOLOv3👉다중 스케일 예측으로 소형 객체 탐지 개선
YOLOv5👉사용자 친화적이며, 경량화된 구조
YOLOv7/v8👉최신 딥러닝 기법 적용, 고성능 제공
YOLO의 활용
👉자율주행: 차량, 보행자 탐지
👉스마트 시티: 보안 카메라를 통한 침입자 감지
👉헬스케어: 의료 영상에서 병변 탐지
👉스포츠: 경기 중 선수 동작 추적
결론
YOLO는 빠른 속도와 높은 정확성을 제공하며 다양한 분야에서 혁신을 이끌어가고 있다.
딥러닝에 익숙하지 않은 초보자도 비교적 쉽게 다룰 수 있어 공부와 프로젝트에 적합한 알고리즘이다.
