▣ 예제112. tablespace level 로 export/import 를 할 줄 알아야 해요
데이터 이행 vs 이과의 차이의 개념을 명확하게 알고 있어야합니다.
-
데이터 이행 --> 데이터를 이동하면서 데이터의 약간이라도 변경을 가하는 작업을
수행했다면 이행예: 서브쿼리를 사용한 insert 문으로 데이터를 이동
-
데이터 이관 --> 통채로 데이터를 넘기는게 이관입니다.
완전하게 데이터 이행을 완료한다는 것은 다음 8가지가 다 넘어가야 한다는 것입니다.
1. table
2. view
3. sequence
4. synonym
5. index
6. 권한
7. 유져
8. 기타
2.3 테라를 넘긴다고 한다면 데이터 이행이면 몇 일 걸리는데 데이터 이관이면 하루면 됩니다.
■ 실습1. 테이블 스페이스 레벨로 export / import
PROD --------------------------------------> jhs이력서에 보유기술 : 테이블 스페이스 레벨로 데이터 이관
#1. orcl db 와 asm 인스턴스를 모두 내립니다.
.oraenv 로 인스턴스 접속 후 sys 로 들어감
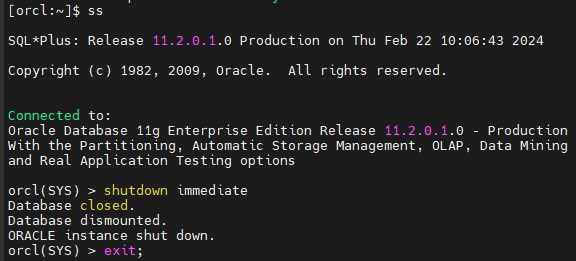
orcl(SYS) > shutdown immediate
Database closed.
Database dismounted.
ORACLE instance shut down.
orcl(SYS) > exit;
똑같은 방법으로 +ASM 으로 접속
ORACLE_SID = [orcl] ? +ASM
The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/grid is /u01/app/oracle
[+ASM:~]$ ss
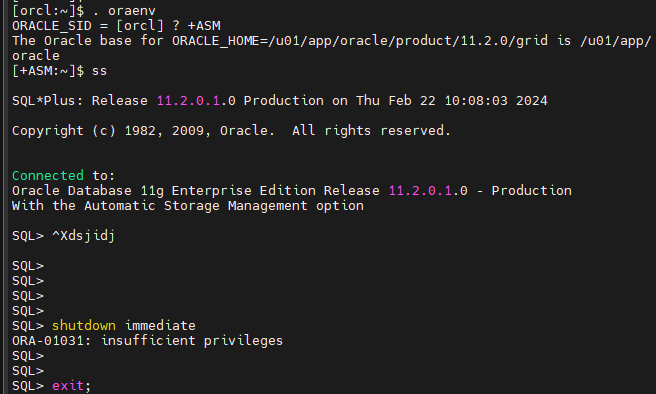
SQL> shutdown immediate
ORA-01031: insufficient privileges
SQL>
SQL>
SQL> exit;
[PROD:~]$ ps -ef | grep pmon
oracle 5455 1 0 Feb21 ? 00:00:14 ora_pmon_jhs
oracle 5567 1 0 Feb21 ? 00:00:14 asm_pmon_+ASM
oracle 8881 1 0 Feb21 ? 00:00:12 ora_pmon_PROD
oracle 10713 26103 0 10:10 pts/1 00:00:00 grep pmon#2. PROD와 jhs db 를 올립니다.
$ . oraenv
-PROD 인스턴스 접속 후 sys 에서 startup
[jhs:~]$ . oraenv
ORACLE_SID = [jhs] ? PROD
ORACLE_HOME = [/home/oracle] ? /u01/app/oracle/product/11.2.0/dbhome_1
The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1 is /u01/app/oracle
[PROD:~]$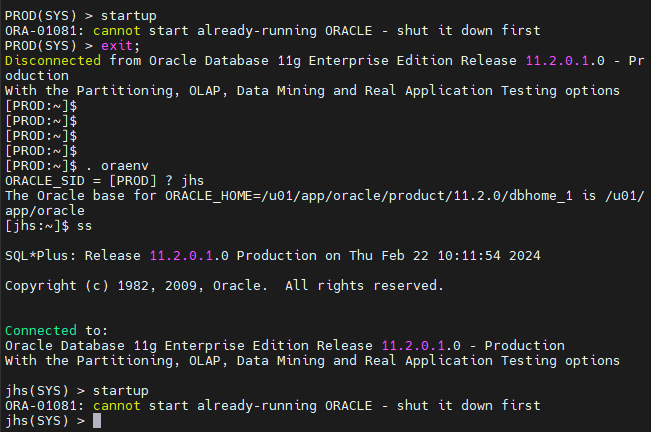
#3. 작업 전에 반드시 확인해야 할 사항을 체크 합니다.
PROD(SYS) > @dbp
PROPERTY_NAME PROPERTY_VALUE
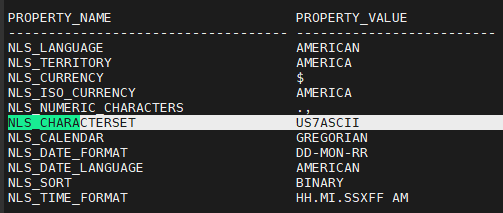
NLS_CHARACTERSET US7ASCII
ORACLE_SID = [PROD] ? jhs
The Oracle base for ORACLE_HOME=/u01/app/oracle/product/11.2.0/dbhome_1 is /u01/app/oracle
[jhs:~]$ ss
SQL*Plus: Release 11.2.0.1.0 Production on Thu Feb 22 10:16:13 2024
Copyright (c) 1982, 2009, Oracle. All rights reserved.
Connected to:
Oracle Database 11g Enterprise Edition Release 11.2.0.1.0 - Production
With the Partitioning, OLAP, Data Mining and Real Application Testing options
jhs(SYS) > @dbp
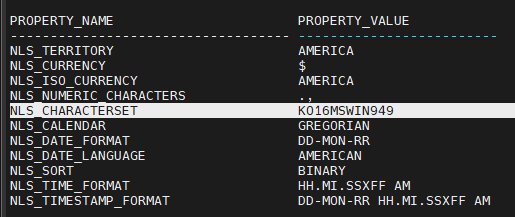
CHARACTERSET이 서로 달라서 jhs 로 데이터 이관을 할 수 없음
PROD 와 jhs2 의 CHARACTERSET 이 서로 같은지 확인 후 데이터 이관을 한다
CHARACTERSET 을 변경할 수 있는데 변경하지 않습니다.
CHARACTERSET 을 변경하면 기존에 저장되어있는 데이터가 ?? 로 나올 수 있기 때문에
data 가 들어있는 기존 db의 CHARACTERSET 을 변경하지 않고
새로 만든 db 의 CHARACTERSET 을 기존 db와 똑같이 맞춰서 생성합니다.
※ 현업에서의 db 엔지니어의 tip!
db 생성하기 전에 고객에게 반드시 기존 db 의 CHARACTERSET 과 똑같이 맞춰줘야 한다는 것을
얘기해줘야 합니다 (데이터 이관 할 때는 반드시 똑같아야 합니다)
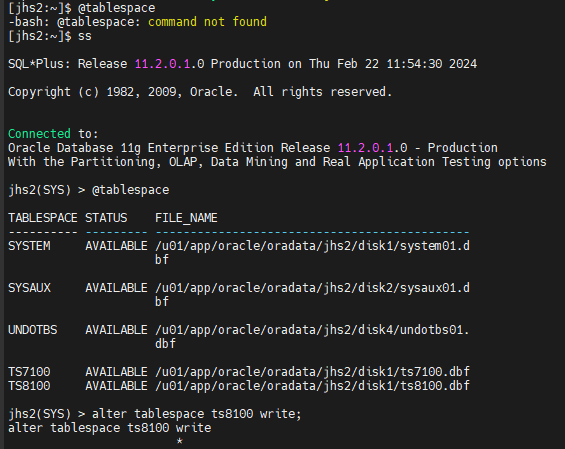
#4. prod db 에서 ts7100 이라는 테이블 스페이스를 생성합니다.
PROD(SYS) > create tablespace ts7100 datafile '/u01/app/oracle/oradata/PROD/disk1/ts7100.dbf' size 5m;
Tablespace created.
▣ 예제 113. database 를 통채로 export / import 할 수 있어요
export / import 4가지
- table level
- user level
- 테이블스페이스 level
- 데이터 베이스 level
■ database level 로 export / import
-
complete -> database 전체를 export
-
incremental -> database 전체를 export 한 이후에 변경된 부분만 export
-
cumulative -> 변경된 부분을 누적해서 export
■ 실습
#1. database level 로 export 를 받는데 옵션을 complete 로 export 받으시오 !
$ exp full=y file=complete01.dmp inctype=complete
username sys as sysdba
password : oracle_4U

#2. database level 로 export 를 받는데 옵션을 incremental 로 export 받으시오 !
$ exp full=y file=inc01.dmp inctype=incremental
▣ 예제114. export/import 보다 더 업그레이드 되어진 data pump 를 알아야 해요
data pump 는 export / import 의 더 업그레이드 된 버전입니다.
- data pump 의 장점 ?

네크워크 모드 : 11g ---------- > 21c
☆ 병렬실행과 재매핑기능 너무너무 중요하다
■ 실습 1. table level 펌프 실습
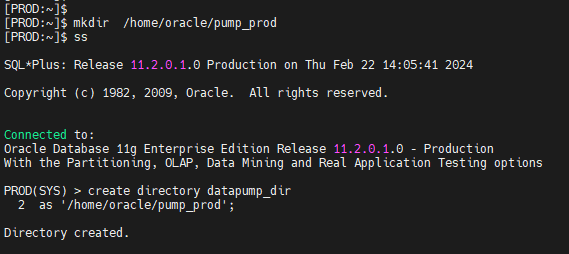
prod ---------------------------------------------> jhs2 #1. prod 쪽 sys 유져에서 directory 를 생성합니다 (펌프 파일을 생성할 디렉토리 )
[PROD:~]$ mkdir /home/oracle/pump_prod
[PROD:~]$ ss
PROD(SYS) > create directory datapump_dir
2 as '/home/oracle/pump_prod';
Directory created.
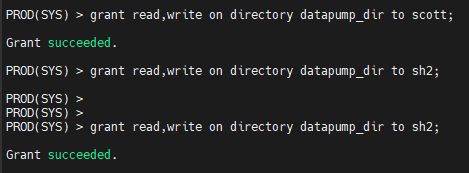
#2. export pump / import pump 를 수행할 유져에게 directory 엑세스 권한을 부여
PROD(SYS) > grant read,write on directory datapump_dir to scott;
PROD(SYS) > grant read,write on directory datapump_dir to sh2;
Grant succeeded.
#3. table level 로 export pump 를 수행합니다.
$ expdp scott/tiger directory=datapump_dir tables=emp dumpfile=emp_pump.dmp
undo 가 꽉 찬 에러가 떴기 때문에 늘려준다 !!
alter tablespace undotbs9
add datafile '/home/oracle/undotbs09b.dbf' size 100m;
$ expdp scott/tiger directory=datapump_dir tables=dept dumpfile=dept_pump.dmp
#4. jhs2 로 접속해서 directory 를 생성합니다.
$ mkdir /home/oracle/pump_jhs2
jhs2(SYS) > create directory jhs2_dir
as '/home/oracle/pump_jhs2';
#5. jones 라는 유져를 만든다.
jhs2(SYS) > create user jones identified by tiger;
jhs2(SYS) > grant dba to jones;
#6. export pump / import pump 를 수행할 유져에게 directory 엑세스 권한을 부여
jhs2(SYS) > grant read,write on directory jhs2_dir to jones;
#7. ts450 이라는 테이블 스페이스를 생성합니다.
jhs2(SYS) > create tablespace ts450 datafile '/home/oracle/ts450.dbf' size 100m;
#8. prod 쪽에서 export 받은 pump 파일을 jhs2 에 copy 합니다.
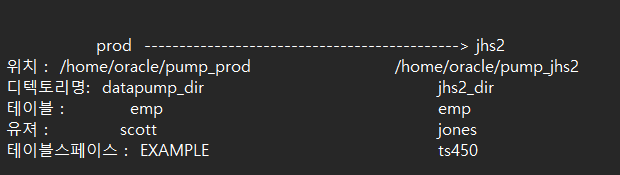
$ cp /home/oracle/pump_prod/emp_pump.dmp /home/oracle/pump_jhs2/emp_pump.dmp
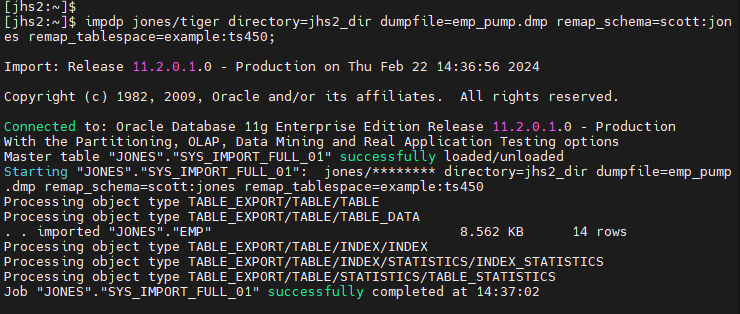
#9. jhs2 에 pump 파일을 import 합니다.
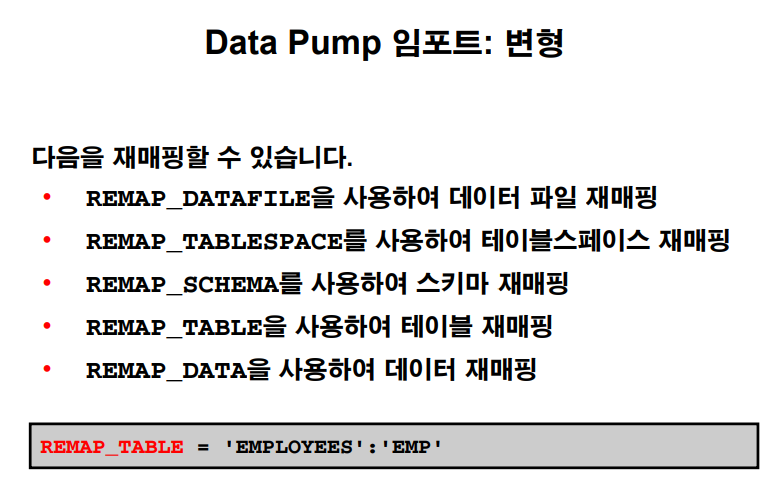
$ impdp jones/tiger directory=jhs2_dir dumpfile=emp_pump.dmp remap_schema=scott:jones remap_tablespace=example:ts450;
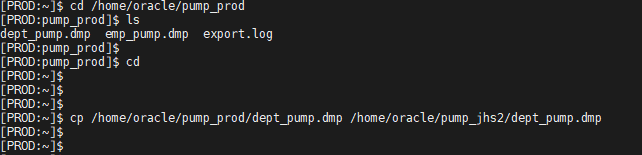
문제1. prod 쪽의 dept 테이블의 pump 파일인 dept_pump.dmp 를 jhs2 에 임폴트 펌프 하시오 !!
[PROD:pump_prod]$ ls
dept_pump.dmp emp_pump.dmp export.log
$ cp /home/oracle/pump_prod/dept_pump.dmp /home/oracle/pump_jhs2/dept_pump.dmp
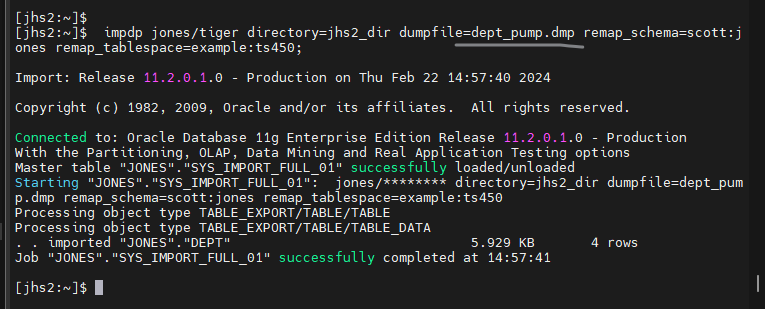
[jhs2:~]$
$ impdp jones/tiger directory=jhs2_dir dumpfile=dept_pump.dmp remap_schema=scott:jones remap_tablespace=example:ts450;
문제2. 테이블을 export pump / import pump 를 하면 관련 인덱스도 같이 export / import 되는지 테스트 하시오
#1. prod 쪽의 soctt 의 emp 테이블과 똑같은 구조와 데이터로 emp612 로 생성합니다.
PROD(SCOTT) > create table emp612
2 as select * from emp;
#2. emp612 테이블의 월급과 직업에 각각 인덱스를 생성합니다
PROD(SCOTT) > create index emp612_sal on emp612(sal);
Index created.
PROD(SCOTT) > create index emp612_job on emp612(job);
Index created.
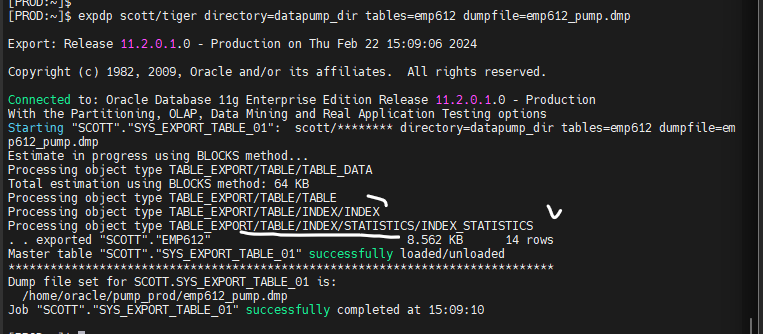
#3. emp612 테이블을 export pump 합니다.
$ expdp scott/tiger directory=datapump_dir tables=emp612 dumpfile=emp612_pump.dmp
인덱스도 같이 넘어왔다,
#4. jhs2 의 emp612 펌프파일을 copy 합니다.
[jhs2:~] cp /home/oracle/pump_prod/emp612_pump.dmp /home/oracle/pump_jhs2/emp612_pump.dmp
#5. jhs2 pump 파일을 임폴트 합니다.
[jhs2:~]$
impdp jones/tiger directory=jhs2_dir dumpfile=emp612_pump.dmp remap_schema=scott:jones remap_tablespace=example:ts450;
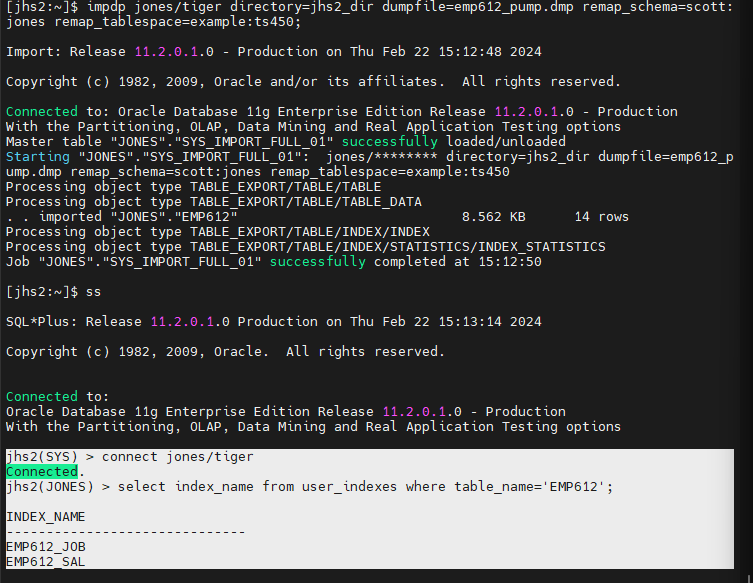
※ db 엔지니어와 dba 를 위한 팁 !
실제로 위와 같이 현장에서 import 하다보면 빅 데이터 환경에서는
import 할 때 인덱스를 생성하는것 때문에 너무 느려서 테이블만 임폴트하고
인덱스는 따로 생성합니다.
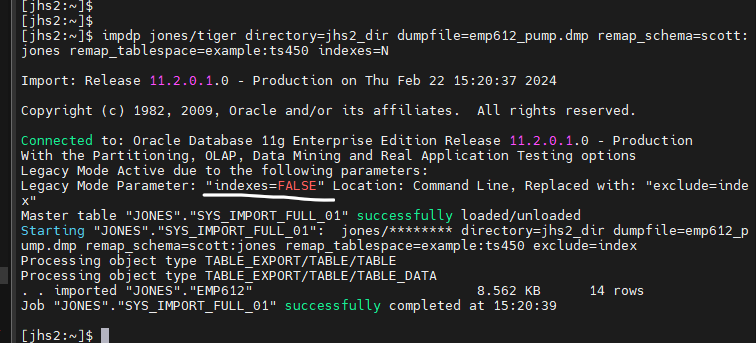
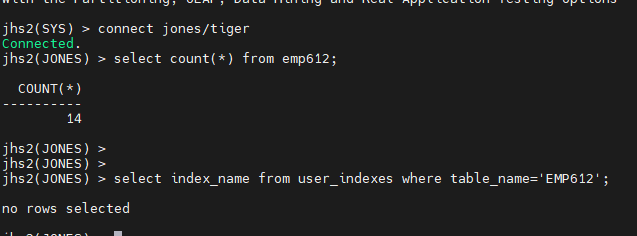
문제 3. 다시jhs2 에서 jones 로 접속해서 emp612 를 drop 하고 (인덱스까지 다 drop 됨)
다시 임폴트 하는데 indexes=n 을 써서 임폴트 하시오
impdp jones/tiger directory=jhs2_dir dumpfile=emp612_pump.dmp remap_schema=scott:jones remap_tablespace=example:ts450 indexes=N
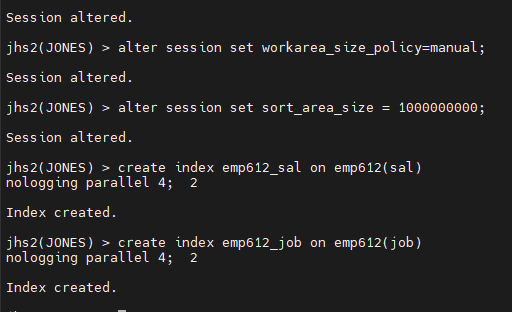
문제 4. jones 유져에서 인덱스를 따로 생성하는데 다음과 같이 빨리!! 생성되게 하시오 !
jhs2(JONES) >
#1. 정렬 작업공간에 대한 사이즈 관리를 수동으로 하겠다.
alter session set workarea_size_policy=manual;
#2. 정렬을 일으킬 메모리 사이즈를 1000000000로 하겠다 내 세션에서만.
alter session set sort_area_size = 1000000000;
create index emp612_sal on emp612(sal)
nologging parallel 4;
create index emp612_job on emp612(job)
nologging parallel 4;

※ 병렬도를 바꿔줘야 한다.
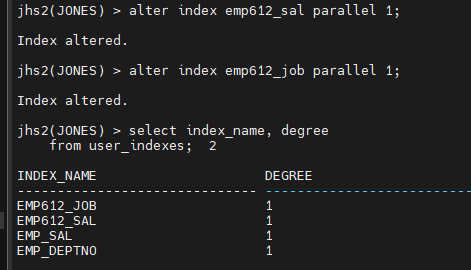
jhs2(JONES) > alter index emp612_sal parallel 1;
jhs2(JONES) > alter index emp612_job parallel 1;
▣ 예제 115. 현업에서 가장 많이 쓰는 유져레벨 pump 를 사용할 수 있어야 해요
■ 실습
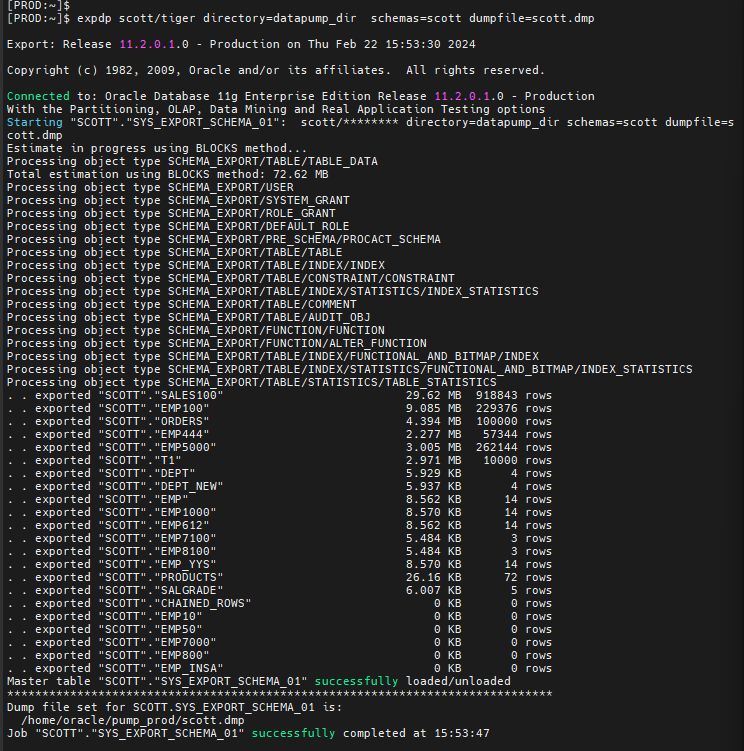
#1. PROD 쪽에서 scott 에 가지고 있는 모든 객체를 유져 레벨로 export pumpt 합니다.
$ . oraenv
[PROD:~]$
$ expdp scott/tiger directory=datapump_dir schemas=scott dumpfile=scott.dmp
#2. jhs2 에 jones2 유져를 생성 합니다.
jhs2(SYS) > create user jones2 identified by tiger;
User created.
jhs2(SYS) > grant dba to jones2;
Grant succeeded.
#3. export 받은 파일을 jhs2 쪽 디렉토리로 cp 합니다.
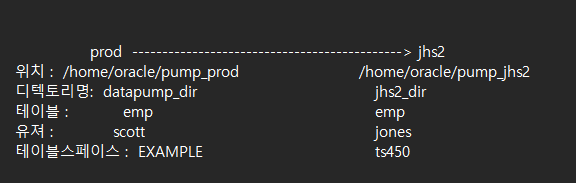
[PROD:~]$
$ cp /home/oracle/pump_prod/scott.dmp /home/oracle/pump_jhs2/scott.dmp
#4. jhs2 db 에 유져 레벨로 imp 합니다.
[jhs2:~]$
impdp system/oracle directory=jhs2_dir dumpfile=scott.dmp remap_schema=scott:jones2 remap_tablespace=example:ts450
문제1. 만약에 중간에 테이블이 많이 안넘어 갔으면 jones2 유져를 drop 하고 다시 생성한 다음에 다시 import 합니다
drop user jones2 cascade;
jhs2(SYS) > create user jones2 identified by tiger;
User created.
jhs2(SYS) > grant dba to jones2;다시 임폴트 할 때 jhs2 db 에 유져 레벨로 임폴트 합니다.
impdp scott/tiger directory=jhs2_dir dumpfile=scott.dmp remap_schema=scott:jones2 remap_tablespace=example:ts450 remap_tablespace=TS8100:ts450 remap_tablespace=TS800:ts450 remap_tablespace=TS100:ts450 remap_tablespace=TEMP:ts450 remap_tablespace=TS7100:ts450 remap_tablespace=TEST100:ts450 remap_tablespace=TS50:ts450 remap_tablespace=SYSTEM:ts450 remap_tablespace=INSA02:ts450 remap_tablespace=YYS:ts450 remap_tablespace=TS5000:ts450
다시 임폴트 할 때 jhs2 db 에 유져 레벨로 임폴트 합니다.
impdp scott/tiger directory=jhs2_dir dumpfile=scott.dmp remap_schema=scott:jones2 remap_tablespace=example:ts450 remap_tablespace=TS8100:ts450 remap_tablespace=TS800:ts450 remap_tablespace=TS100:ts450 remap_tablespace=TEMP:ts450 remap_tablespace=TS7100:ts450 remap_tablespace=TEST100:ts450 remap_tablespace=TS50:ts450 remap_tablespace=SYSTEM:ts450 remap_tablespace=INSA02:ts450 remap_tablespace=YYS:ts450 remap_tablespace=TS5000:ts450
PROD(SCOTT) > select distinct tablespace_name from user_tables;
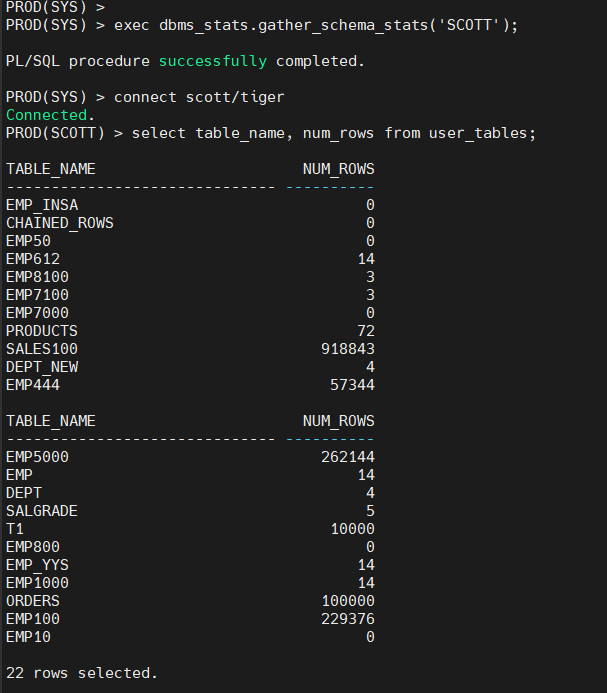
문제2. 양쪽에서 스키마 레벨로 통계정보 수집 후 user_tables 를 조회해서 테이블 이름과 num_rows 를 조회 하시오 !
양쪽에서 스키마 레벨로 통계 정보 수집
sys>
exec dbms_stats.gather_schema_stats('SCOTT');
scott>
select table_name, num_rows from user_tables;
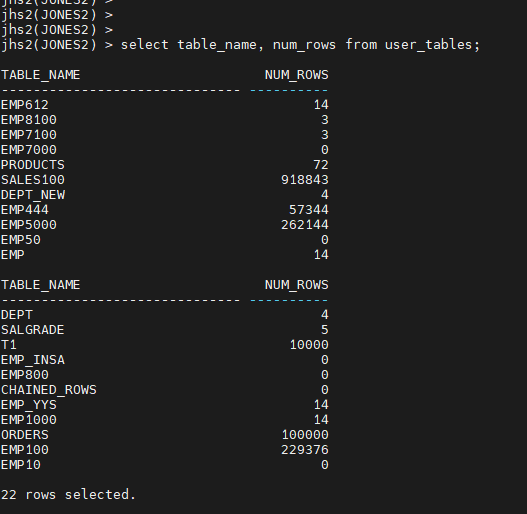
jhs2(SYS) >
exec dbms_stats.gather_schema_stats('JONES2');
jones2> select table_name, num_rows from user_tables;
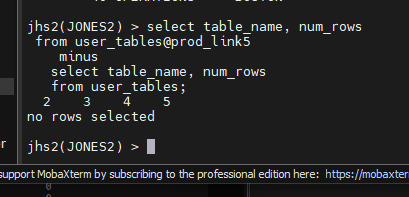
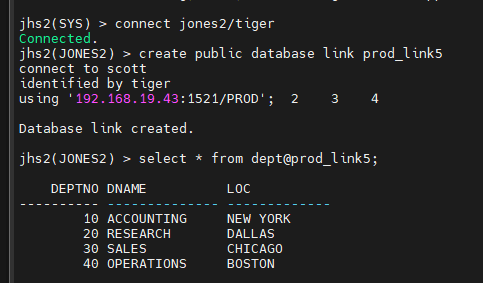
jhs2(JONES2) > create public database link prod_link5
connect to scott
identified by tiger
using '192.168.19.43:1521/PROD';
jhs2(JONES2) > select table_name, num_rows
from user_tables@prod_link5
minus
select table_name, num_rows
from user_tables;