최근 대량의 데이터가 등장하고 이에 따라 labeling 작업에 비용과 시간이 많이 든다. 이에 unlabelled dataset만으로 좋은 representation을 얻으면 더 좋은 성능을 낼 것이라는 생각에 self-supervised learning이 등장했다.
Self-Supervised Learning
unlabelled dataset으로부터 좋은 representation을 얻고자 하는 학습 방식
없이 내에서 target으로 쓰일만한 것을 정해 즉, self로 task를 정해 supervision 방식으로 모델을 학습한다.
self-supervised learning은 다음과 같이 구성된다.
- Self-prediction
- Contrastive learning
Self-prediction
하나의 data sample 내에서 한 part를 통해 다른 part를 예측하는 task
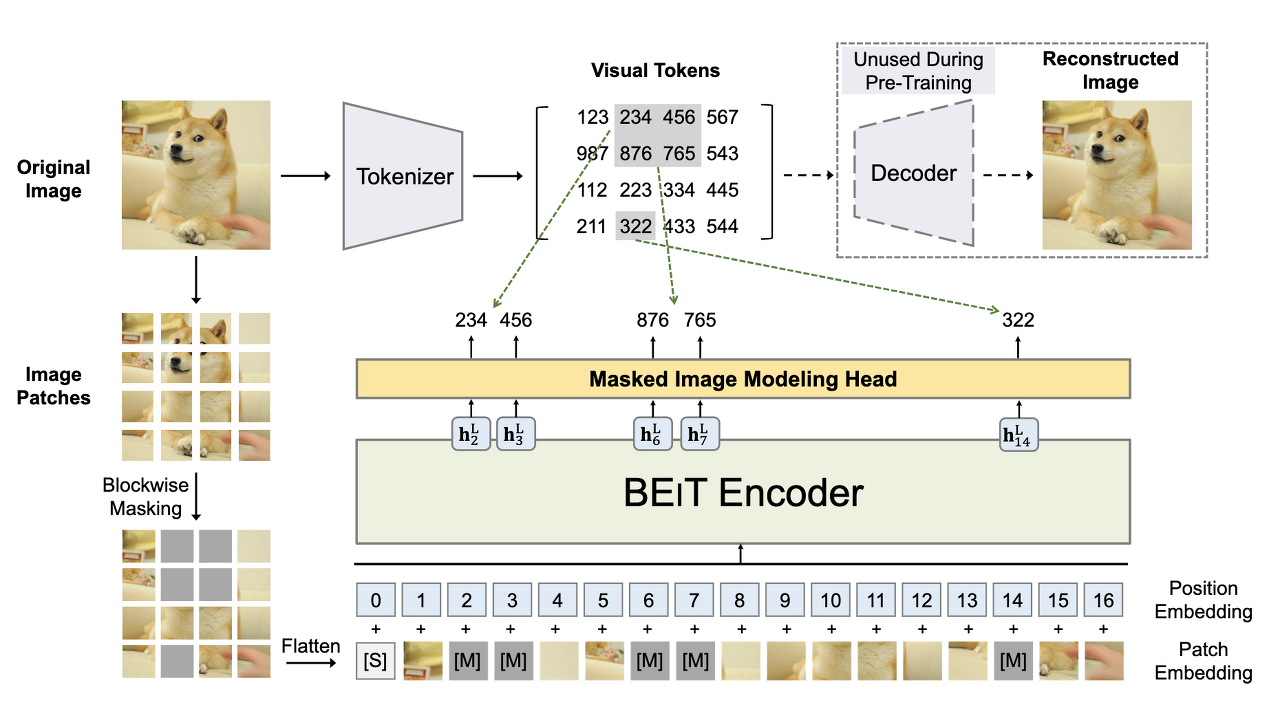
최근에는 일부를 random masking하고 이를 prediction 하는 방식이 가장 많이 사용된다.
1. Autoregressive generation
Autoregressive 모델은 이전 behavior를 통해 미래의 behavior를 예측한다. language처럼 문장을 이어 나가면서 다음에 올 단어를 예측하는 경우가 된다.
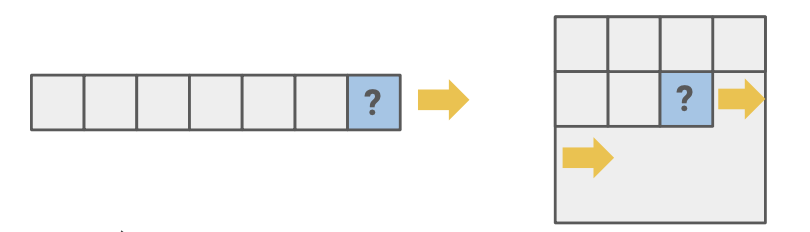
2. Masked generation/prediction
정보의 일부를 masking하여 masking 되지 않은 부분을 통해 masking 된 부분을 예측한다. Autoregressive generation은 앞 정보만 보고 예측하는 반면, 이는 앞, 뒤 정보를 보고 예측한다. 또한 random masking으로 masking의 범위가 계속 변화하기 때문에 다양한 scale이나 size에 대한 학습이 가능하다.

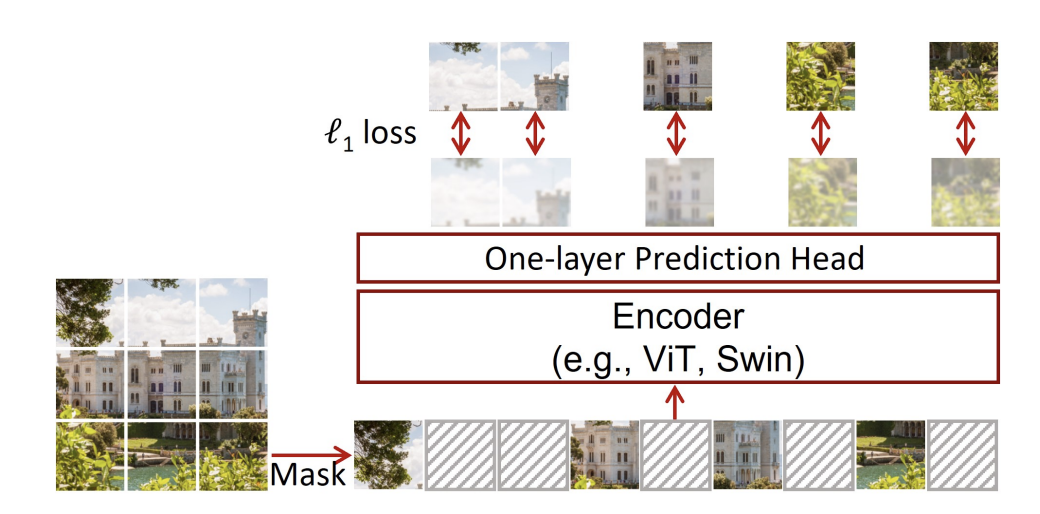

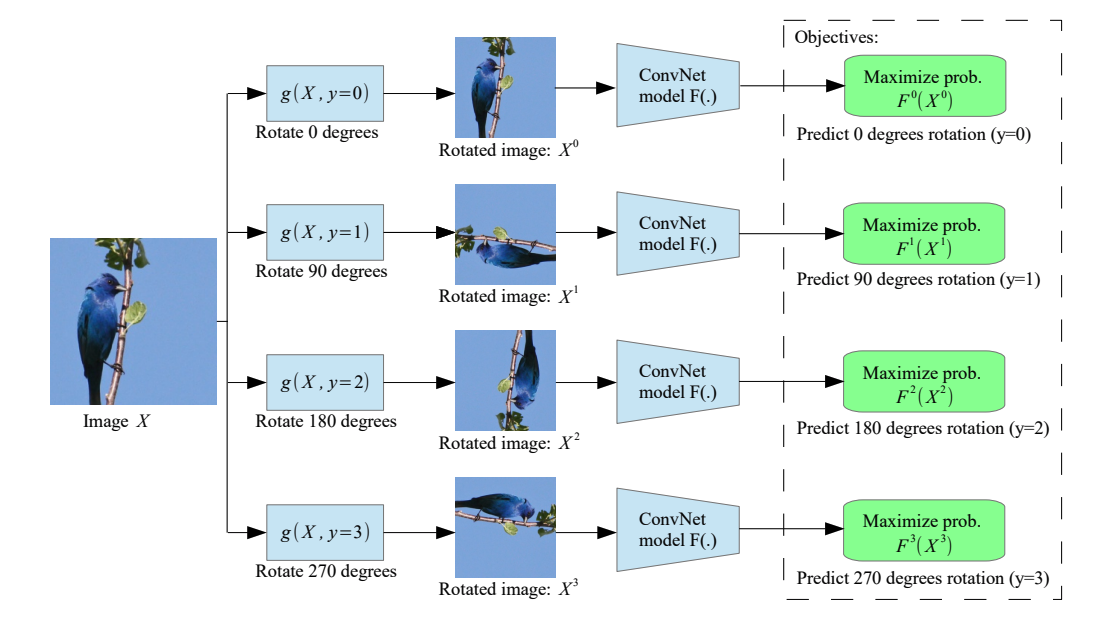
3. Innate relationship prediction
segmentation이나 rotation 등의 transformation을 하나의 sample에 가했을 때 본질적인 정보는 동일할 것이라는 믿음으로 relation을 prediction한다.
4. Hybrid self-prediction
앞에 나온 여러가지 방식을 섞어 나오는 hybrid model
Contrastive learning
batch 내의 data sample들 사이의 관계를 예측하는 task
목적은 invariance를 학습하는 것이다. 유사한 sample pair는 거리가 가깝게, 유사하지 않은 sample pair는 거리가 멀게 한다. 유사한지 않은지에 대한 기준이 되는 현재 data point를 anchor라고 하고 anchor와 유사한 sample을 positive point라고 하고 유사하지 않은 sample을 negative sample이라고 한다.
1. Background and theories
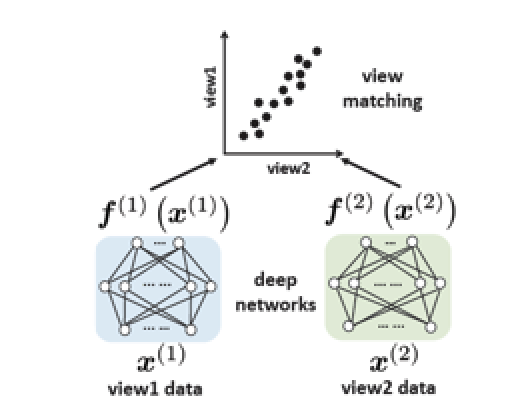
Siamese network and representation collapse(or dimensional collapse)
Siamese network는 입력으로부터 얻은 2개의 augmented views x1과 x2에 대한 latentfmf matching 시키는 방식으로 작동. 이는 다른 view 간의 correlation을 maximize하거나 distance를 minimize하는 방식으로 작동한다.
즉, 다양한 view로 보며 공통의 정보를 추출한다는 것이다.
2.Inter-sample classification (=Instance discrimination)
contrastive learning은 instance를 구별하는 classification task를 pretext task로 삼는다. 다른 view로 생성한 positive pair(x1, x2)는 각각 다른 encoder를 통과하고 서로 가까워지도록 학습을 수행한다. 또한 다른 class를 가지는 negative sample은 서로 멀어지도록 학습한다.
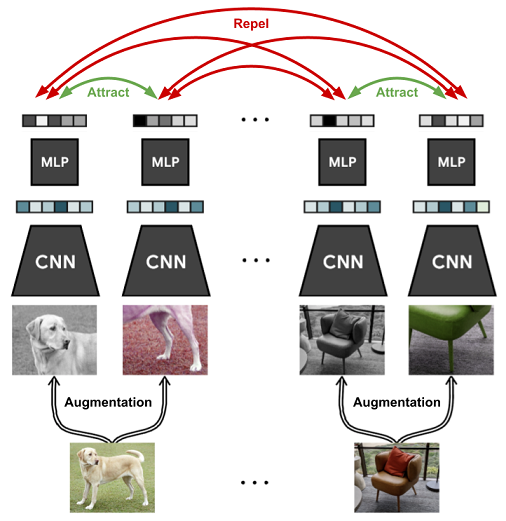
이때 positive pair를 고르는 방법은 image의 다양한 augmentation 기법을 통해 다양한 version을 만든다. 또한 하나의 data에 대해 different view를 positive pair로 선정한다.
negative pair를 고르는 방법은 batch내에 anchor가 아닌 다른 sample들을 negative sample로 본다. 이때 negative sample은 개수가 많을수록 representation collapse를 방지하는데 효과가 좋다고 한다.
이때 loss는 다음과 같이 여러가지가 쓰인다.
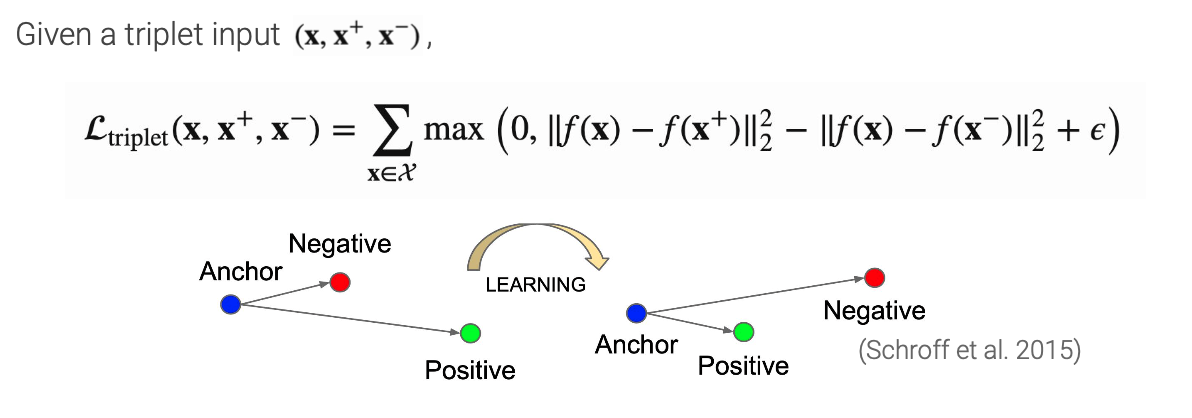
- Triplet loss
이는 distance를 기반으로 anchor와 positive의 distance는 minimize하고, negative와의 distance는 maximizegksms 방식을 사용한다.
- InfoNCE
참고
