Object Detection
- Classification
- 한 물체가 아닌 여러 물체에 대해 어떤 물체인지 분류하는 것 - Localization
- 그 물체가 어디 있는지 박스를 통해 위치 정보를 나타내는 것
즉, Object Detection = Classification + Localization
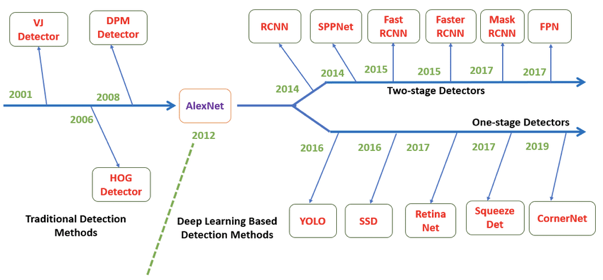
Object Detection은 1-stage Detector와 2-Stage Detector로 구분 할 수 있다.
이때, 1-stage Detector은 Classification 문제와, Localization을 동시에 행하는 방법이고, 2-stage Detector은 순차적으로 진행한다.
| 1 - stage Detector | 2 - stage Detector | |
|---|---|---|
| 속도 | 빠름 | 느림 |
| 정확도 | 낮음 | 높음 |
R-CNN
설정한 Region을 CNN의 feature로 활용해, Object Detection을 수행하는 신경망
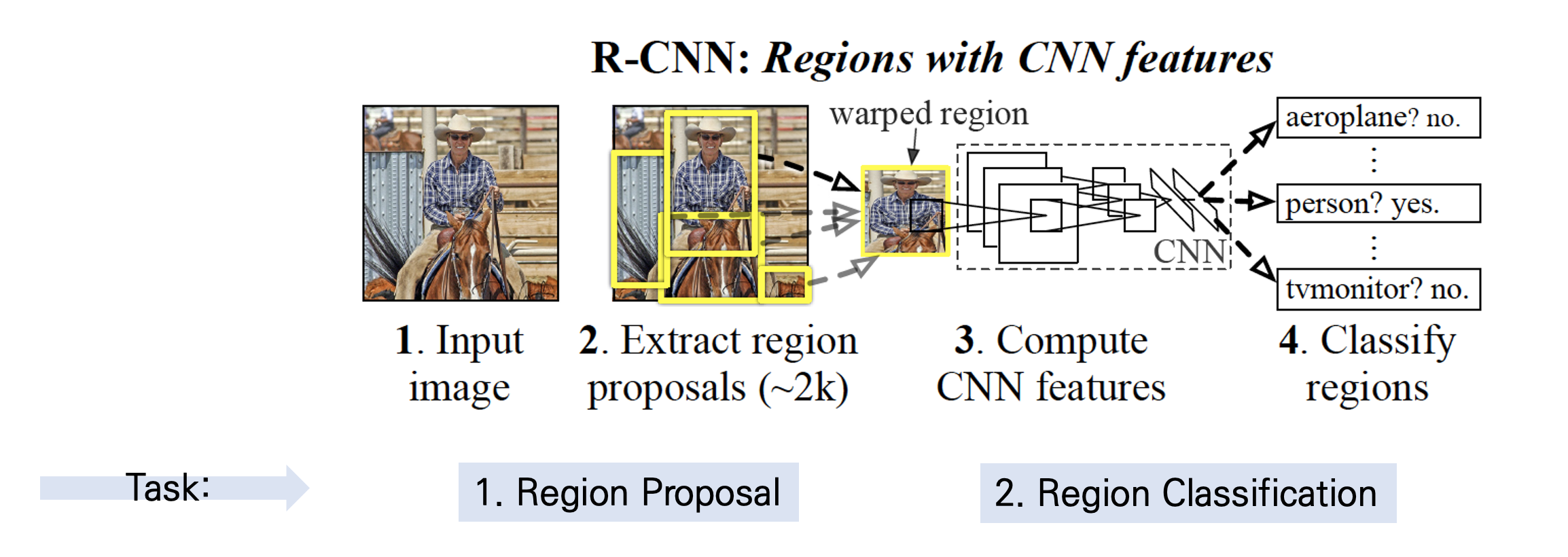
- Region Proposal
- 물체의 위치를 찾는 것 - Region Classification
- 물체를 분류하는 것
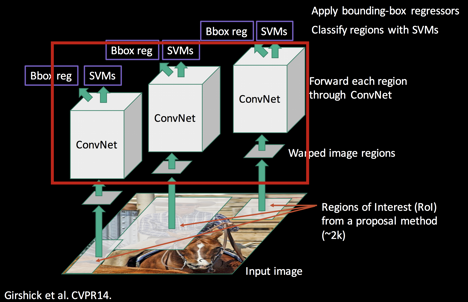
1. 이미지에 있는 데이터와 레이블을 투입한 후 물체의 영역을 찾는 Region Proposal
2. proposal 된 영역에서 고정된 크기의 Feature Vector을 warping/crop하여 CNN의 input으로 사용
3. CNN을 통해 나온 feature map을 활용해 선형 지도학습 모델인 SVM을 통한 분류
4. Regressor를 통한 bounding box regression
1. Region Proposal
이미지를 테이터 형식으로 사용하려면 이미지 픽셀들을 vertex로 표현하고, 그 vertex의 연결을 edge라고 보면 된다.
R-CNN은 이 단계에서 Selective Search 알고리즘을 이용해 임의의 Bounding Box를 설정한다.
1. Bounding Box들을 Random하게 작게 많이 생성함
2. 계층적 그룹핑 알고리즘을 사용해 조금씩 merge해 나간다.
3. 이를 바탕으로 ROI(Regions of Interest)라는 영역을 제안하는 Region Proposal 형식으로 진행된다.
2. CNN
AlexNet(ImageNet) 구조 재사용
CNN은 input 값의 크기가 고정되어 있기 때문에, 이들을 모두 CNN에 넣기 위해 여러 사이즈로 나온 Bounding Box들을 같은 사이즈(227 X 227)로 통일 시키는 작업을 거친다.
3. SVM (Support Vector Machine)
CNN 모델로부터 feature가 추출되고 Training Label이 적용되고 나면 Linear SVM을 사용해 classification을 진행한다.
4. Bounding Box Regression
처음에 y로 줬던 레이블과, CNN을 통과해서 나온 Bounding Box,의 차이를 구해서 차이를 줄이도록 조정하는 선형회귀 모델 절차
