
인공 뉴런: 초기 머신러닝의 간단한 역사
인공 뉴런의 수학적 정의
인공 뉴런을 2개의 클래스가 있는 이진 분류로 나타낼 수 있다.
클래스는 1(양성 클래스)와 -1(음성 클래스)로 나타낼 수 있다.
최종 입력은 다음과 같이 나타낼 수 있다.
퍼셉트론에서 는 단위 계단 함수를 변형한 것이다.
이때 식을 간단하게 만들기 위해 임계 값인 를 식의 왼쪽으로 옮겨 이고, 인 0번째 가중치를 정의하면 다음과 같이 결정함수가 정의될 수 있다.
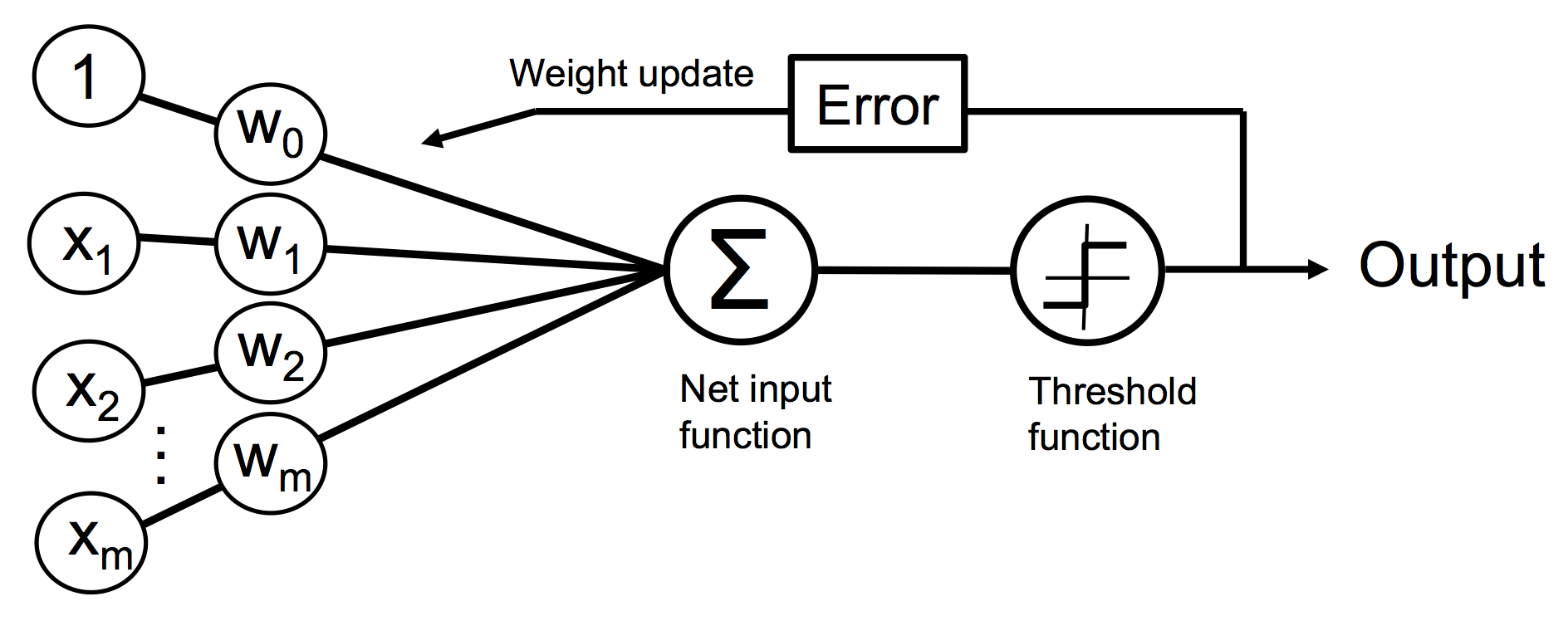
퍼셉트론 학습 규칙
퍼셉트론은 출력을 내거나, 내지 않는 2가지의 경우만 존재한다.
퍼셉트론 학습 규칙은 다음과 같다.
1. 가중치를 0 또는 랜덤한 작은 값으로 초기화한다.
2. 각 훈련 샘플 에서 다음 작업을 진행한다.
a. 출력 값 ŷ를 계산한다.
b. 가중치를 업데이트 한다.
이때 가중치 업데이트는 다음과 같이 정의할 수 있다.
만약 퍼셉트론이 클래스 레이블을 정확히 예측한 두 경우는 가중치가 변경되지 않고 그대로 유지된다.
- 퍼셉트론을 표현한 다이어그램
파이썬으로 퍼셉트론 학습 알고리즘 구현
https://github.com/hyeonsoo0625/review-machinelearning-textbooks/blob/main/ch2/perceptron.ipynb
적응형 뉴런과 학습의 수렴
아달린과 퍼셉트론의 차이점은 가중치를 업데이트하는데 퍼셉트론은 단위계단 함수를 사용한 반면 아달린은 선형 활성화 함수를 사용한다.
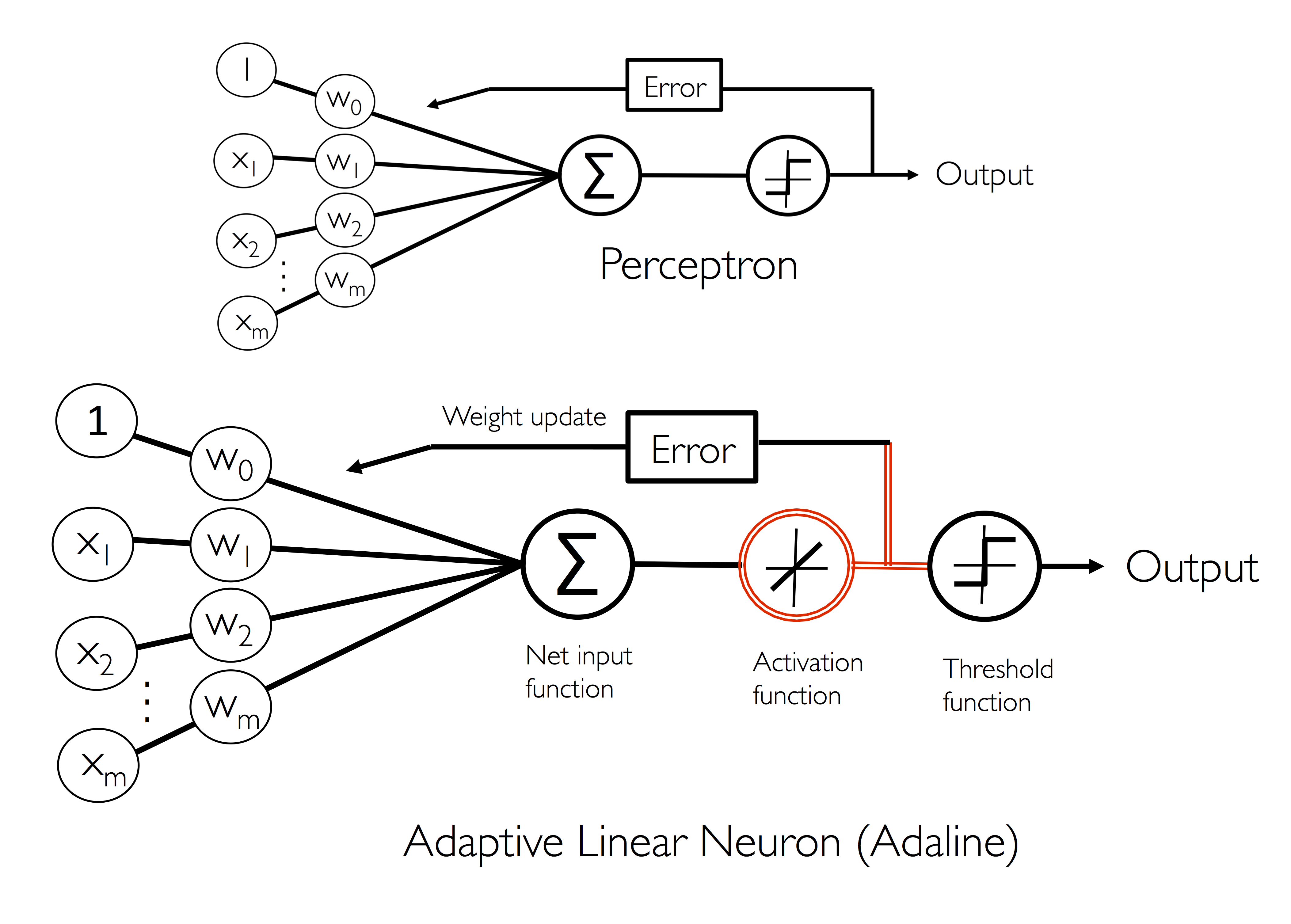
아달린 알고리즘은 진짜 클래스 레이블과 선형 활성화 함수의 실수 출력값을 비교하여 모델의 오차를 계산한다.
경사 하강법으로 비용 함수 최소화
아달린의 비용함수는 다음과 같다.
연속적인 선형 활성화 함수의 장점은 비용 함수가 미분 가능해진다는 것이다.
파이썬으로 아달린 구현
https://github.com/hyeonsoo0625/review-machinelearning-textbooks/blob/main/ch2/adaline.ipynb
특성 스케일을 조정하여 경사 하강법 결과 향상
머신러닝 알고리즘들은 특성 스케일을 조정하는 것이 필요하다. 이중 표준화가 있다.
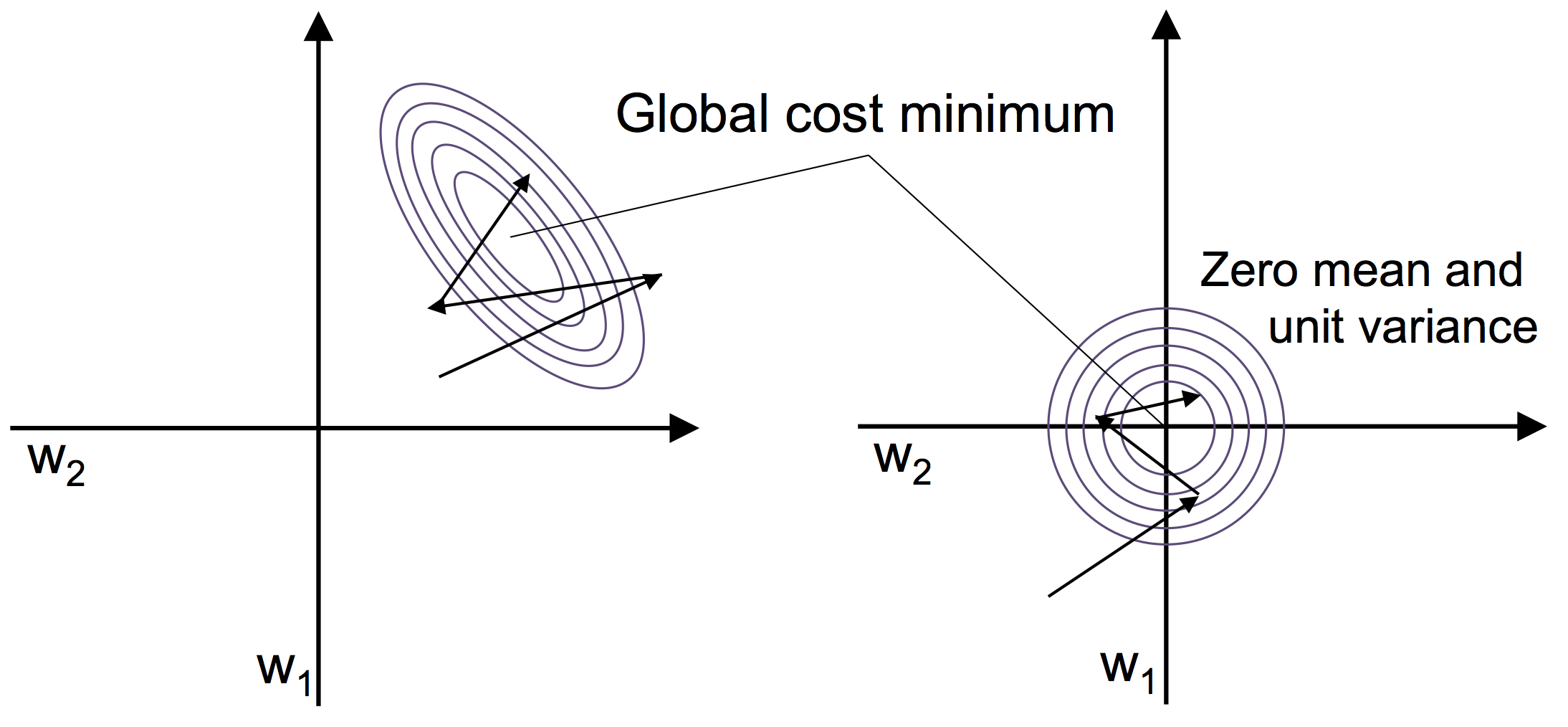
표준화은 평균이 0이고, 표준 편차가 1(단위 분산)으로 만드는 것
표준화는 다음과 같이 더욱 적은 단계를 거쳐 최적 혹은 좋은 솔루션을 찾기 때문에 좋다.
대규모 머신 러닝과 확률적 경사 하강법
-
배치 경사 하강법
전체 훈련 데이터 셋에서 계산한 gradient의 반대 방향으로 한 걸음씩 진행하여 비용 함수를 최소화
-
확률적 경사 하강법 (온라인 경사 하강법)
각 훈련 샘플에 대해 조금씩 가중치를 업데이트 함
