Abstract
기존 open-vocabulary object detection은 VLMs(ex. CLIP)과 같은 open-vocabulary recognition을 활용해 향상시킴. 하지만 2가지 문제점이 있다.
- CLIP의 text space에서 사용되는 category가 충분한 텍스트, 시각적 정보를 포함하지 않음
- VLMs에서 detectors로 transfer할 때 base category에 overfitting하는 문제
이를 해결하기 위해 Language Model Instruction (LaMI) 전략을 제안하였다.
이는 GPT를 활용해 visual concept를 구성하고 T5를 사용해 category간 시각적 유사성을 나타낸다.
Introduction
Open-vocabulary object detection(OVOD)는 제한된 base category set로만 훈련되었음에도 불구하고, inference에서 base, novel category에서 object를 탐지하고 위치를 찾아내는 것을 목표로 한다. 기존 연구는 VLM의 zero-shot과 few-shot 성능을 object detection에 효과적으로 적용시키기 위한 모듈 개발에 초점을 맞춰왔다.
하지만 이는 2가지 문제점이 존재한다.
개념 표현 문제
기존에는 CLIP text encoder의 name embedding을 사용해 개념을 표현한다. 하지만 이는 시각적으로 혼돈될 수 있는 범주를 category를 구별하고 새로운 물체를 탐색하는데 도움이 될 수 있는 textual과 visual 의미의 유사성을 포착하는데 한계가 있다.base category에 대한 overfitting 문제
VLMs는 open-vocabulary detector의 학습 과정에서 base category에 대한 데이터만 사용하므로 overfitting의 문제점이 있다. 이는 새로운 object들을 background나 base category로 잘못 분류될 수 있는 문제가 존재한다.
Concept Representation
CLIP의 textual space 내의 category 이름은 textual의 깊이와 visual 정보가 부족하다.
VLM의 text encoder는 language model에 비해 textual semantic knowledge가 부족하다.

위 그림을 보면 CLIP의 name 표현에만 의존하는 것은 문자 조합의 유사성에만 초점을 맞추고 언어 뒤에 있는 계층적이고 상식적인 이해는 무시한다. 이는 category 간의 개념적인 관계를 고려하지 않기 때문에 category의 clustering에 불리하다.
또한, 추상적인 category 이름과 정의를 기반으로 한 개념 표현은 시각적 특징을 설명하지 못한다.

위 그림을 보면, sea-lion과 dugong은 시각적으로 유사함에도 불구하고 별도의 cluster에 할당된다.
base category에 대한 overfitting 문제
고정된 CLIP의 image encoder를 backbone으로 사용하고 CLIP의 text encoder를 classification weight로써 category embedding을 활용한다. detector 훈련을 수행할 때 foreground을 background로부터 분리를 해야 하고, CLIP의 open-vocabulary classification 능력을 유지하야 한다.
base category annotation만으로 훈련을 하면 overfitting이 발생하게 되고, 이는 새로운 object가 background나 base category로 잘못 분류되는 결과가 초래된다.
위 문제를 해결하기 위해 inter-category relationships이 중요하다고 한다. 이는 시각적으로 유사한 category를 식별해 모델이 일반화된 foreground 특징 학습에 더 집중할 수 있도록 하고 base category에 대한 overfitting을 방지할 수 있다.
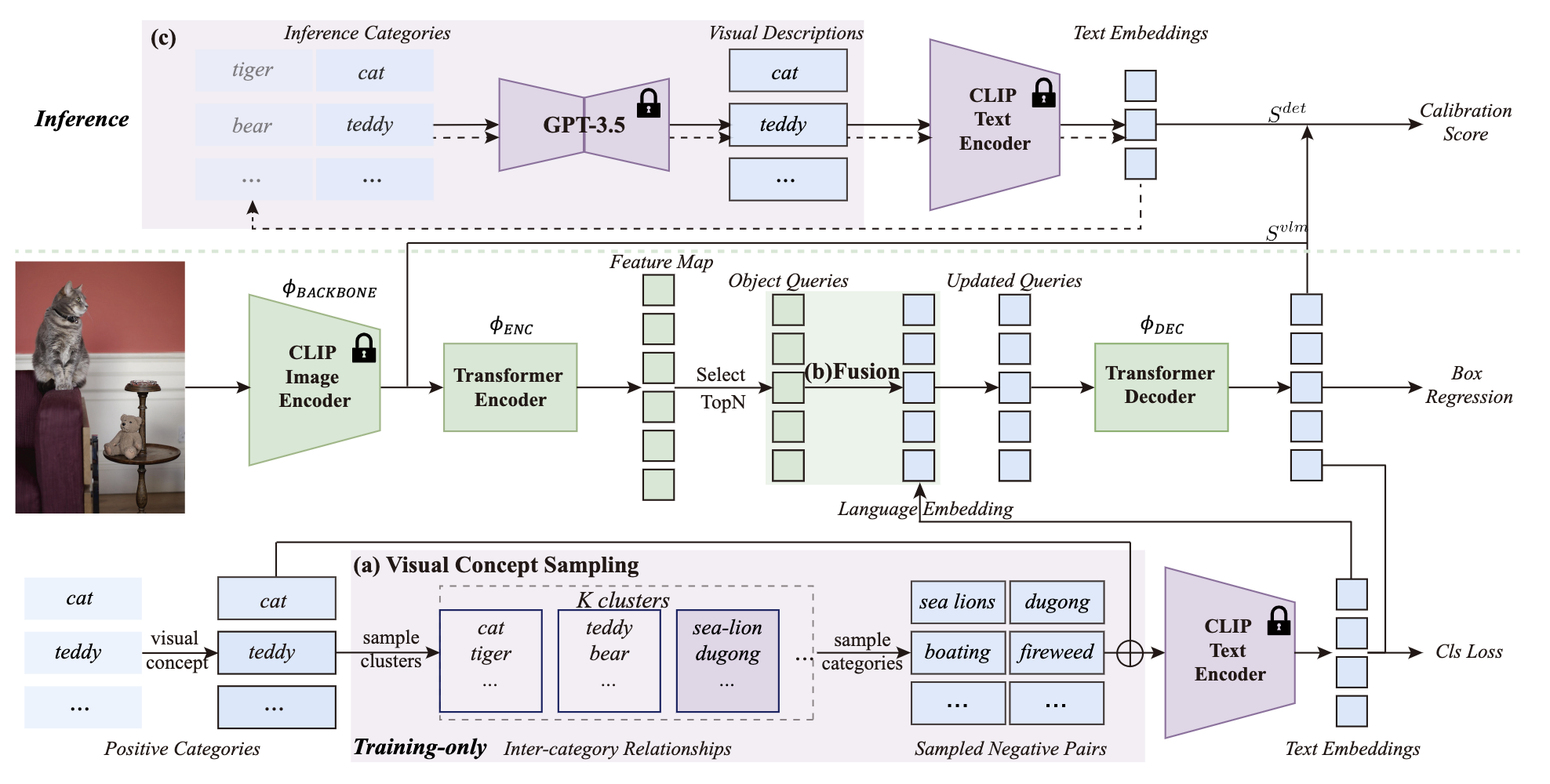
concept representation을 다루기 위해 먼저 category 유사성을 평가하기 위해 Instructor embedding, T5 language model을 채택했다. 이를 통해 language model이 CLIP text encoder에 비해 더 정교한 의미 공간을 보여주는 것을 발견했다. 위 그림을 보면 "fireweed"와 "fireboat"는 별개의 cluster로 분류되어 인간 인식에 더 가깝게 반영이 된다. 또한 각 category의 시각적 설명을 생성하기 위해 GPT-3.5를 사용했다. 이를 통해 형태, 색상, 크기와 같은 특성이 상세하게 설명되어 있고 이는 category를 시각적 개념으로 전환한다.

위 그림을 보면 유사한 시각적 설명으로 인해 sea-lion과 dugong이 동일한 cluster로 그룹화 된 것을 확인할 수 있다.
이 clustering을 통해 각 iteration에서 truth category와 시각적으로 다른 negative class들을 식별하고 sampling 할 수 있도록 한다.
Related Work
Open-vocabulary object detection (OVOD)
OVOD는 image-level dataset이나 대규모 pre-trained VLMs에서 저장된 iamge와 language alignment 지식을 활용해 object detector에 open-vocabulary 정보를 통합한다. OVOD는 대규모 image-text pair를 활용해 detection vocabulary를 확장한다. object detector가 VLM으로부터 open-vocabulary 지식을 얻는 방법은 다음과 같다.
- pseudo labels
- distillation
- parameter transfer
이에도 불구하고 VLM에 의해 성능이 제한되고, 이는 category 간의 시각적 관계에 대해 크게 인식하지 못하는 경향이 있다.
Zero-shot object detection (ZSD)
ZSD는 일반화된 언어적 특징을 활용해 새로운 class detection에 도전한다.
Method
Preliminaries
Input:
Output:
- Classification
이미지 내 j 번째 예측 object에 대해 class label 할당
이때 는 inference 중 목표 category의 집합이다. - Localization
이미지 내 j 번째 예측 object의 위치를 식별하는 bounding box 결정
Architecture of LaMI-DETR
Input image에 대해 pre-trained CLIP의 image encoder ()에서 ConvNext backbone을 사용해 spatial feature map을 얻는다. 이때 backbone은 훈련 중 학습되지 않는다. 다음으로 feature map을 정제하기 위해 transformer encoder()와 query feature 을 생성하는 transformer decoder()와 query feature는 object의 위치를 infer하기 위한 bounding box module ()에 의해 처리되어 로 나타낸다. 이때 F-VLM의 inference pipeline을 따르며, VLM 점수 을 사용해 detection score 을 보정한다.
