
1. GPT 개요
GPT는 Large Language Model(LLM)의 대표 사례로, Pre-training과 Transformer 구조 결합을 통해 자연어 생성 및 이해 능력을 극대화한 모델이다.
① Pre-training(사전 학습)
대규모 텍스트 코퍼스를 활용해 언어의 통계적 패턴을 학습한다. 이 과정에서 단어 간 연관성, 문장 구조, 의미적 유사성을 파악해 다양한 다운 스트림 작업에 적용할 수 있는 기초 지식을 구축한다.
② Transformer 구조
Attention 메커니즘으로 입력 토큰 간 관계를 동적으로 가중치에 반영한다. Decoder Only 형태의 GPT는 순차적 언어 생성에 최적화되어, 특정 위치의 단어가 앞선 문맥을 참고해 자연스러운 텍스트를 생성한다.
③ Zero-/One-/Few-shot Learning
예시가 적거나, 심지어 예시 없이도, 사전 학습만으로 다양한 과제에 바로 적용 가능해, 추가적인 파인튜닝 없이 질문 답변·요약·번역·분류 등 여러 작업을 수행할 수 있다.
2. GPT의 역사와 발전
① Transformer 모델의 등장 배경
Transformer는 2017년 Attention Is All You Need 논문을 통해 제안되었다. 기존의 RNN이나 CNN의 한계를 벗어나, Attention 메커니즘만으로도 긴 문맥을 효과적으로 처리할 수 있음을 증명했다. 특히, 병렬 연산이 가능한 구조 덕분에 학습 속도가 크게 향상됐고, 이후 모든 LLM의 토대가 되었다.
② GPT-1: 제로샷 학습 능력의 시발점
2018년 발표된 GPT-1은 12 개의 레이어, 1.17억 개의 파라미터로 구성된 Decoder Only Transformer이다. 대규모 웹 텍스트(BooksCorpus)를 활용해 Pre-training을 진행했으며, 파인튜닝을 통해 여러 다운스트림 태스크에 적용했다. 이때부터 ‘pre-training + fine-tuning’ 방식이 NLP 표준 워크플로우로 자리 잡았다.
③ GPT-2: 대규모 언어 모델의 가능성
2019년 등장한 GPT-2는 15억 개 파라미터로 스케일을 대폭 확장했다. 특히, fine-tuning 없이도 프롬프트에 대한 응답을 생성하는 Zero-/One-/Few-shot 학습 능력을 보여, 별도 튜닝 없이도 다양한 과제에 적용 가능한 범용성을 입증했다. 한편, 허위 정보 생성 등 잠재적 위험을 이유로 초기에는 모델 공개가 단계적으로 이루어졌다.
④ GPT-3 이후 대형 언어 모델의 진화
2020년 공개된 GPT-3는 1750억 개 파라미터로 다시 한 번 혁신을 일으켰다. 풍부한 문맥 이해와 자연스러운 생성 능력 덕분에 연구·산업 전반에 폭넓게 채택됐다. 이후 OpenAI는 성능 개선 및 비용 효율을 위해 GPT-3.5 계열 모델을 출시했으며, 2023년 말 공개된 GPT-4는 멀티모달 입력 지원과 고도화된 추론 능력을 갖추었다. 각 버전마다 파라미터 규모, 데이터 다양성, 학습 기법이 진화하며 ‘인간 수준의 언어 지능’에 한 걸음 더 다가가고 있다.
3. GPT 아키텍처 심층 분석
가. Decoder Only 구조
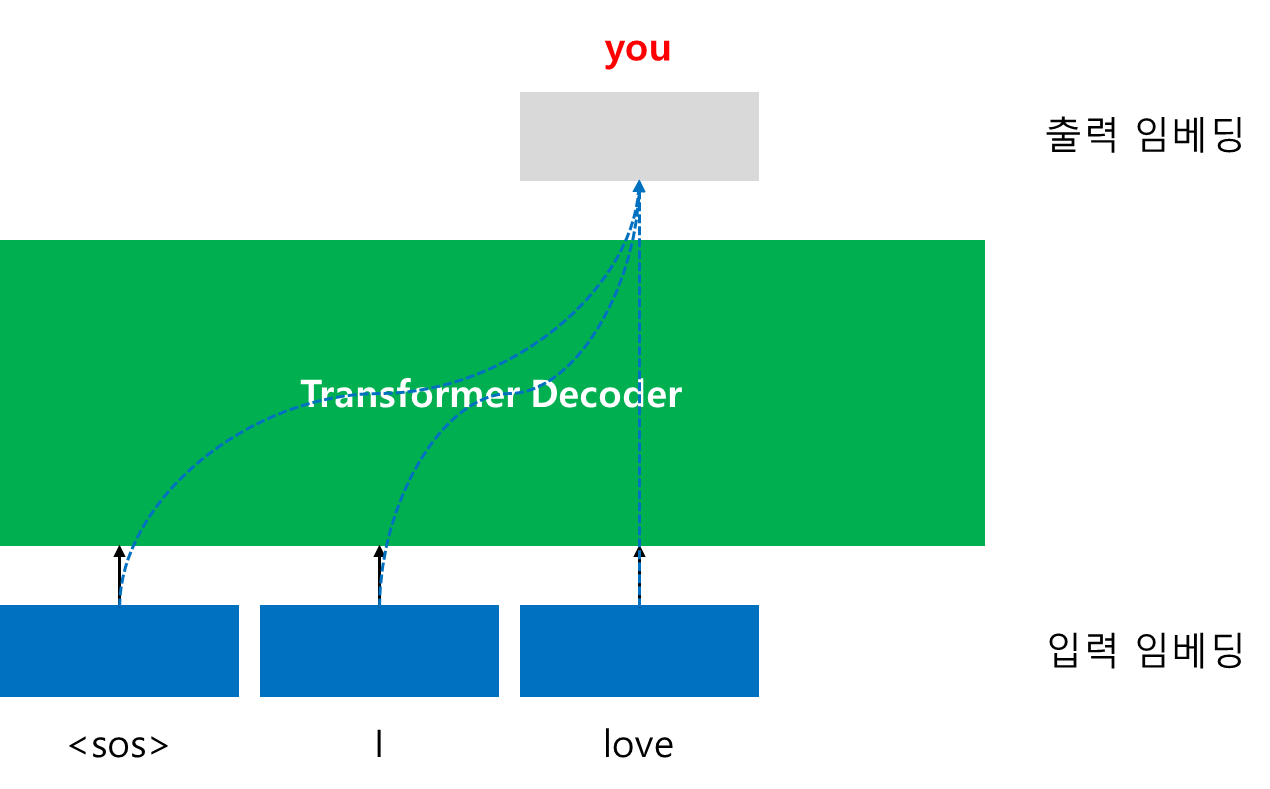
GPT는 Transformer의 Decoder 부분만을 활용한 Decoder-Only 아키텍처를 채택한다. 입력 시퀀스 전체를 한 번에 보지 않고, 이전 토큰들만 참조하여 다음 토큰을 예측하는 마스킹(self-attention mask)을 적용한다. 이로써 순차적 언어 생성에 최적화되고, 긴 문맥에서도 계산 복잡도를 선형으로 유지할 수 있다.
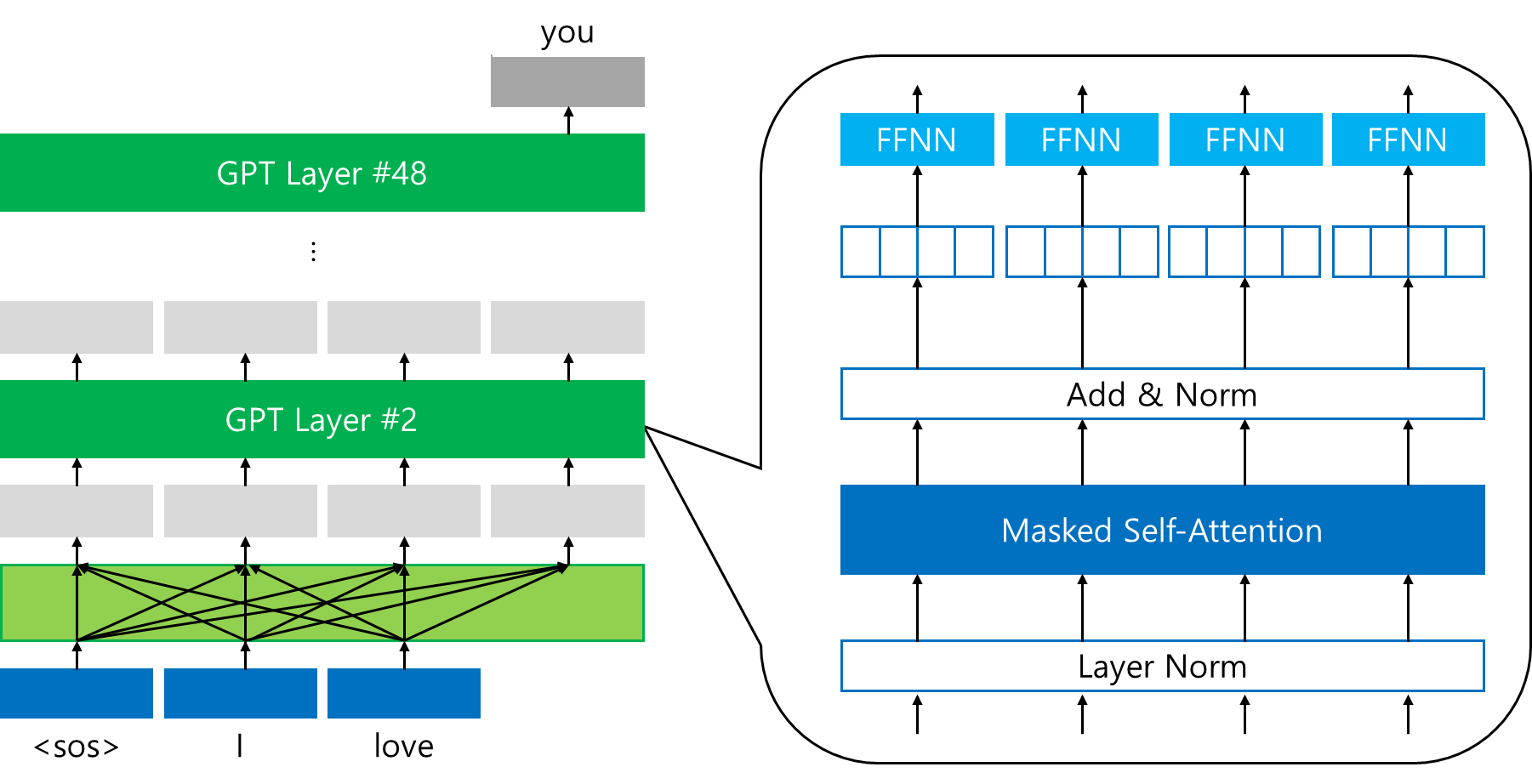
각 Decoder 블록은 (1) 마스킹된 셀프 어텐션, (2) FFNN(Feed-Forward Neural Network), (3) 잔차 연결(residual connection) 및 레이어 정규화(layer normalization)로 구성된다.
나. 서브레이어 구성과 레이어 정규화 위치 변화
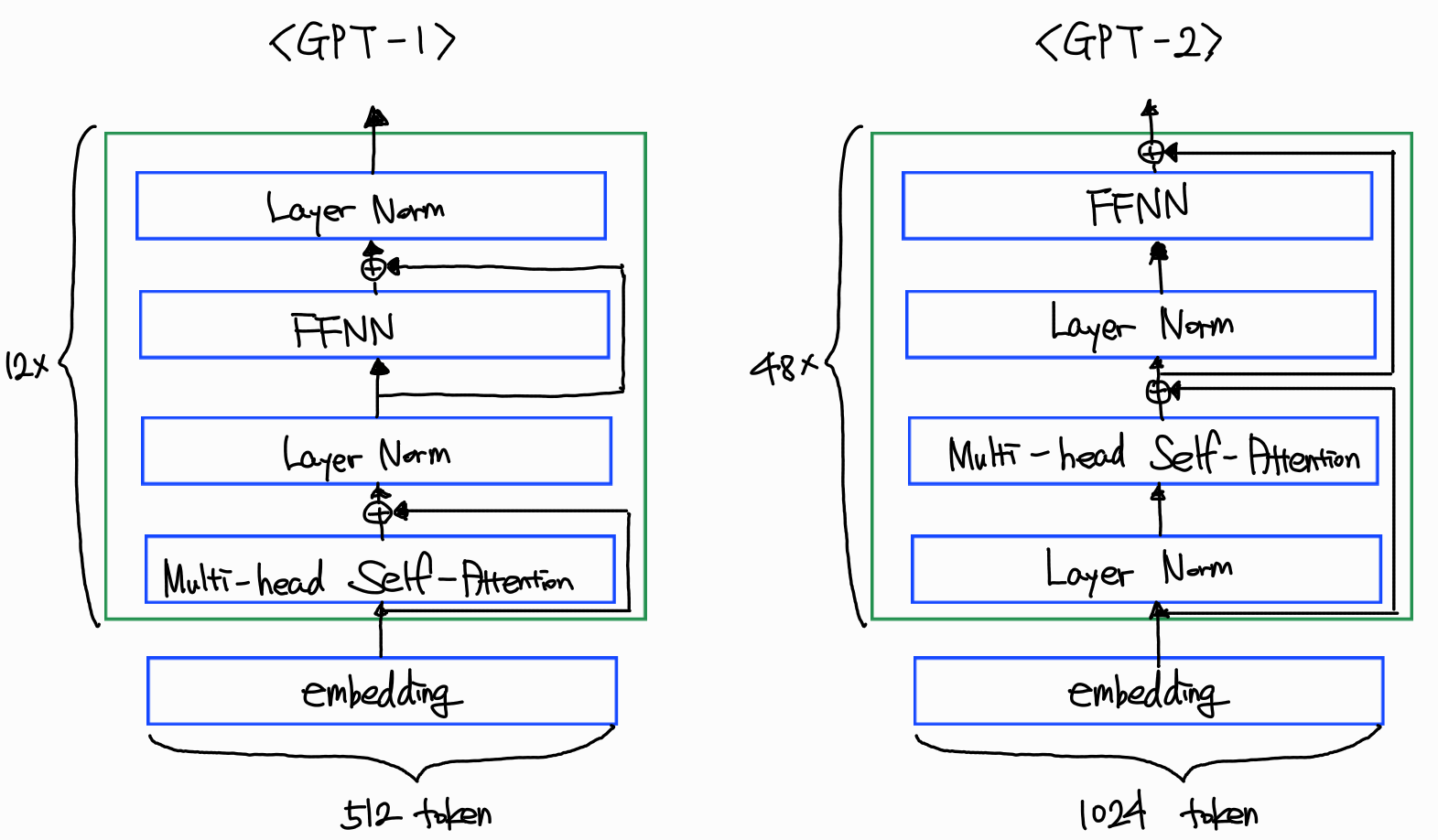
① GPT-1 vs GPT-2 비교
GPT-1은 원본 Transformer와 동일하게 포스트 레이어 정규화(Post-LN) 방식을 사용했다. 즉, 잔차 연결을 더한 뒤에 레이어 정규화를 적용한다.
GPT-2에서는 학습 안정성과 수렴 속도 개선을 위해 프리 레이어 정규화(Pre-LN) 방식으로 전환했다. 서브레이어 입력에 먼저 레이어 정규화를 적용하고, 그 결과를 셀프 어텐션 또는 MLP에 전달한다. 이로 인해 그라디언트 흐름이 더 원활해지고, 수십~수백 층의 모델에서도 학습이 용이해진다.
② 토크나이저·어휘 수 확장
GPT-1은 단어와 서브워드 기반의 BPE(Byte-Pair Encoding)를 사용해 약 50,000 개 어휘를 구성했다.
GPT-2부터는 바이트 단위 BPE(byte-level BPE) 토크나이저로 전환해, 이모지·특수문자·非ASCII 텍스트까지 모두 하나의 체계로 처리한다. 어휘 크기는 약 50K에서 52K 내외로 확장되며, 다양한 언어·기호에 대한 내성이 강화됐다.
다. 사전 학습 전략과 데이터셋
① Common Crawl 활용
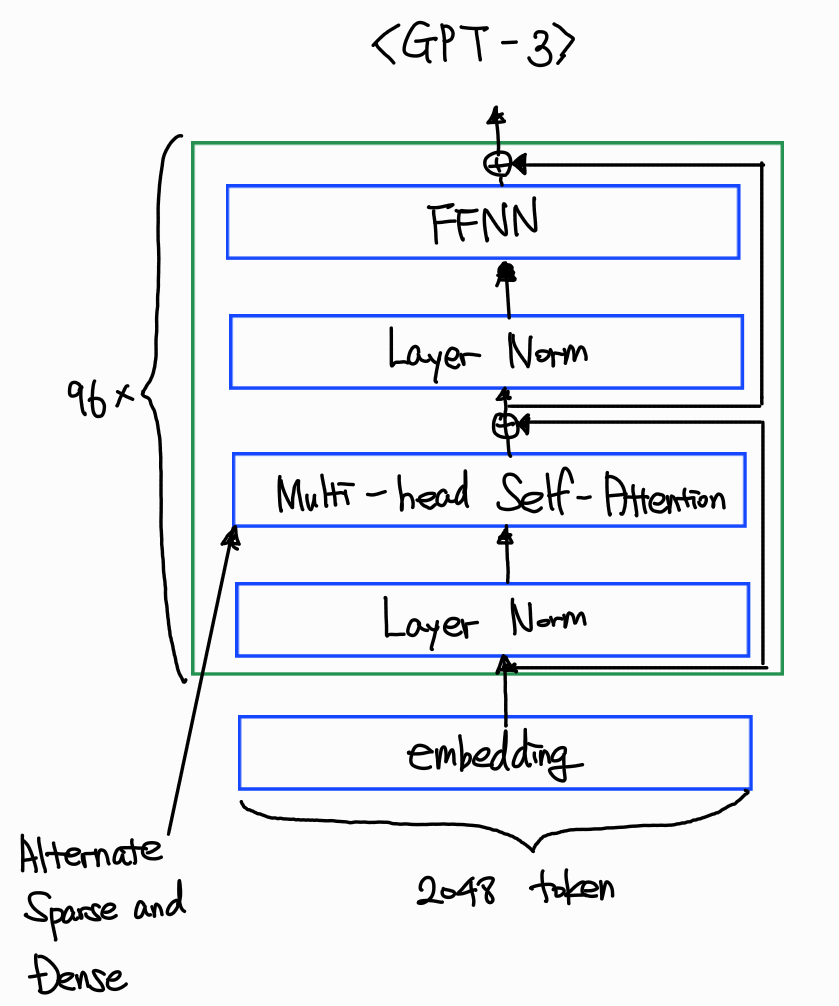
GPT-3 이후 모델부터 사전 학습 데이터셋에 Common Crawl 전체 웹 크롤링 데이터를 대규모로 활용한다. 대용량·다양성 높은 웹 문서를 정제하여 학습에 투입함으로써, 일반 지식과 상식 추론 능력을 크게 끌어올린다.
데이터 샘플링 시 언어별·도메인별 비율을 조정해 과대표집(over-representation)을 방지하고, 편향(bias)을 줄이려는 시도도 병행된다.
② 파인튜닝 없이 일반화 성능
GPT-2부터 선보인 zero-/one-/few- shot 학습 능력은 사전 학습만으로도 일반화가 충분히 가능함을 보여준다. 간단한 프롬프트 설계만으로도 분류·요약·번역 등의 작업을 수행하며, 별도 파인튜닝 없이도 품질 높은 결과를 내는 것이 특징이다.
이 접근법은 모델 재학습에 드는 비용과 시간을 절감하며, 다양한 언어 태스크에 신속히 적용할 수 있는 강력한 이점을 제공한다.
4. 실습
가. GPT-2를 이용한 문장 생성 실습
https://colab.research.google.com/drive/1JIu8YQTmZGsOrmGmXAeVvDwknSiayW44?usp=sharing
1) KoGPT-2로 문장 생성
Transformers 패키지를 사용하여 모델과 토크나이저를 로드한다.
!pip install transformers
import tensorflow as tf
from transformers import AutoTokenizer
from transformers import TFGPT2LMHeadModelTFGPT2LMHeadModel.from_pretrained('GPT 모델 이름')을 넣으면 두 개의 문장이 이어지는 문장 관계인지 여부를 판단하는 GPT 구조를 로드한다. AutoTokenizer.from_pretrained('모델 이름')을 넣으면 해당 모델이 학습되었을 당시에 사용되었던 토크나이저를 로드한다.
model = TFGPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2', from_pt=True)
tokenizer = AutoTokenizer.from_pretrained('skt/kogpt2-base-v2')GPT가 생성할 문장의 방향을 지시하기 위해, 시작 문자열을 정해준다. 다음과 같이, '근육이 커지기 위해서는'이라는 문자열을 주고, GPT에게 이어서 문장을 생성해보라고 하겠다.
sent = '근육이 커지기 위해서는'GPT의 입력으로는 정수 인코딩된 결과가 입력되어야 하므로, tokenizer.encode()을 통해서, '근육이 커지기 위해서는'이라는 문자열을 정수 시퀀스로 변환해준다.
input_ids = tokenizer.encode(sent)
input_ids = tf.convert_to_tensor([input_ids])
print(input_ids)
위와 같이, 33245 10114 12748 11357라는 4 개의 정수 시퀀스를 얻는다. 해당 정수 시퀀스를 GPT의 입력으로 사용하여 GPT가 이어서 문장을 생성하도록 하겠다. model.generate()을 사용하여, 주어진 문장으로부터 이어서 문장을 생성하도록 한다.
output = model.generate(input_ids,
max_length=128,
repetition_penalty=2.0,
use_cache=True)
output_ids = output.numpy().tolist()[0]
print(output_ids)다음 결과를 보면, 기존의 33245 10114 12748 11357라는 4 개의 정수 시퀀스 뒤에도 여러 정수들이 추가로 생성된 것을 알 수 있다.
[33245, 10114, 12748, 11357, 23879, 39306, 9684, 7884, 10211, 15177, 26421, 387, 17339, 7889, 9908, 15768, 6903, 15386, 8146, 12923, 9228, 18651, 42600, 9564, 17764, 9033, 9199, 14441, 7335, 8704, 12557, 32030, 9510, 18595, 9025, 10571, 25741, 10599, 13229, 9508, 7965, 8425, 33102, 9122, 21240, 9801, 32106, 13579, 12442, 13235, 19430, 8022, 12972, 9566, 11178, 9554, 24873, 7198, 9391, 12486, 8711, 9346, 7071, 36736, 9693, 12006, 9038, 10279, 36122, 9960, 8405, 10826, 18988, 25998, 9292, 7671, 9465, 7489, 9277, 10137, 9677, 9248, 9912, 12834, 11488, 13417, 7407, 8428, 8137, 9430, 14222, 11356, 10061, 9885, 19265, 9377, 20305, 7991, 9178, 9648, 9133, 10021, 10138, 30315, 21833, 9362, 9301, 9685, 11584, 9447, 42129, 10124, 7532, 17932, 47123, 37544, 9355, 15632, 9124, 10536, 13530, 12204, 9184, 36152, 9673, 9788, 9029, 11764]정수들이 단순히 나열된 것만으로는 GPT가 실제로 어떠한 문장을 생성했는지 알 수 없으니, 해당 정수 시퀀스를 한국어로 변환하겠다. 이 과정은 tokenizer.decode()로 가능하다.
tokenizer.decode(output_ids)결과는 다음과 같다.
'근육이 커지기 위해서는 무엇보다 규칙적인 생활습관이 중요하다.\n특히, 아침식사는 단백질과 비타민이 풍부한 과일과 채소를 많이 섭취하는 것이 좋다.\n또한 하루 30분 이상 충분한 수면을 취하는 것도 도움이 된다.\n아침 식사를 거르지 않고 규칙적으로 운동을 하면 혈액순환에 도움을 줄 뿐만 아니라 신진대사를 촉진해 체내 노폐물을 배출하고 혈압을 낮춰준다.\n운동은 하루에 10분 정도만 하는 게 좋으며 운동 후에는 반드시 스트레칭을 통해 근육량을 늘리고 유연성을 높여야 한다.\n운동 후 바로 잠자리에 드는 것은 피해야 하며 특히 아침에 일어나면 몸이 피곤해지기 때문에 무리하게 움직이면 오히려 역효과가 날 수도 있다.\n운동을'2) Numpy로 Top 5 뽑기
GPT는 기본적으로 이전 단어들로부터 다음 단어를 예측하는 언어 모델이다. 앞선 결과에 따르면, '근육이 커지기 위해서'라는 입력을 넣었을 때, GPT는 '무엇보다'라는 다음 단어를 예측하였다. 실제로는 수많은 후보의 다음 단어들이 있었지만, 그 중 확률이 가장 높은 단어를 예측한 것이다. 그렇다면, 또다른 후보들로 어떠한 것이 있는지 5 개만 알아보겠다.
output = model(input_ids)
top5 = tf.math.top_k(output.logits[0, -1], k=5)그 후 Top 5의 단어를 한국어로 변환하여 출력해보겠다.
tokenizer.convert_ids_to_tokens(top5.indices.numpy())
3) Numpy Top 5로 문장 생성하기
앞서 문장을 생성했을 때는 각 시점(time step)마다 가장 확률이 높은 단어를 예측했지만, 이번에는 매 시점마다 Top 5 개의 단어들 중에서 무작위로 선택하는 방식으로 문장을 생성해보겠다.
sent = '근육이 커지기 위해서는'
input_ids = tokenizer.encode(sent)
while len(input_ids) < 50:
output = model(np.array([input_ids]))
# Top 5의 단어들을 추출
top5 = tf.math.top_k(output.logits[0, -1], k=5)
# Top 5의 단어들 중 랜덤으로 다음 단어로 선택.
token_id = random.choice(top5.indices.numpy())
input_ids.append(token_id)
tokenizer.decode(input_ids)
나. GPT-2를 이용한 한국어 챗봇 실습
https://colab.research.google.com/drive/1GzJGQ7QUbXtc4zfpIxfy8OGCpM07wNka?usp=sharing
1) KoGPT-2의 모델과 토크나이저 로드
!pip install transformers
import tensorflow as tf
from transformers import AutoTokenizer
from transformers import TFGPT2LMHeadModel토크나이저를 로드할 때 텍스트 생성을 시작할 때 사용하는 시작 토큰을 bos_token, 텍스트 생성을 종료할 때 사용하는 종료 토큰을 eos_token이라는 이름으로 지정할 수 있다. 여기서는 </s>라는 토큰을 시작 토큰이자 종료 토큰으로 사용하고자 한다.
tokenizer = AutoTokenizer.from_pretrained('skt/kogpt2-base-v2', bos_token='</s>', eos_token='</s>', pad_token='<pad>')
model = TFGPT2LMHeadModel.from_pretrained('skt/kogpt2-base-v2', from_pt=True)GPT에는 특별한 용도로 사용하기 위해 할당해놓은 special tokens이 존재한다. Ko-GPT2에서 사용되는 speical tokens의 정수 그리고 반대로 정수 1, 2, 3, 4는 각각 어떤 tokens을 의마하는지 확인해보겠다.
print(tokenizer.bos_token_id)
print(tokenizer.eos_token_id)
print(tokenizer.pad_token_id)
print('-' * 10)
print(tokenizer.decode(1))
print(tokenizer.decode(2))
print(tokenizer.decode(3))
print(tokenizer.decode(4))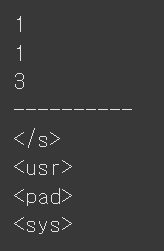
| 토큰 역할 | 정수 ID | 토큰 문자열 |
|---|---|---|
| 문장 시작(BOS) / 문장 종료(EOS) | 1 | </s> |
| 사용자(User) 구분 | 2 | <usr> |
| 패딩(PAD) | 3 | <pad> |
| 시스템(System) 구분 | 4 | <sys> |
BOS와 EOS는 동일하게 ID 1번으로 설정되어 있으며, 둘 다 </s>로 표현된다. <usr>(2)와 <sys>(4) 토큰은 챗봇 대화에서 사용자와 시스템 메시지를 구분하는 용도로 사용된다. <pad>(3)는 입력 길이를 맞추기 위한 패딩 토큰이다.
2) 챗봇 데이터 로드
import pandas as pd
import tqdm
import urllib.request
urllib.request.urlretrieve("https://raw.githubusercontent.com/songys/Chatbot_data/master/ChatbotData.csv", filename="ChatBotData.csv")
train_data = pd.read_csv('ChatBotData.csv')
len(train_data)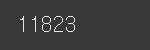
챗봇 데이터의 개수는 11,823 개이다.
3) 챗봇 데이터 전처리
다음을 챗봇 데이터를 전처리하기 위한 함수 get_chat_data()이다.
def get_chat_data():
for question, answer in zip(train_data.Q.to_list(), train_data.A.to_list()):
bos_token = [tokenizer.bos_token_id]
eos_token = [tokenizer.eos_token_id]
sent = tokenizer.encode('<usr>' + question + '<sys>' + answer)
yield bos_token + sent + eos_token위의 전처리는 <usr> 다음에 사용자의 질문을 부착하고, 그 후 <sys> 다음에 챗봇의 답변을 부착하는 형식으로 전처리를 진행한다. 그리고 앞 뒤에 BOS 토큰과 EOS 토큰을 부착하는 전처리이다. 두 토큰은 동일하며 </s>이다.
batch_size = 32
dataset = tf.data.Dataset.from_generator(get_chat_data, output_types=tf.int32)
# 배치 크기만큼 데이터를 구성하되 패딩 토큰으로 패딩을 진행.
dataset = dataset.padded_batch(batch_size=batch_size, padded_shapes=(None,), padding_values=tokenizer.pad_token_id)첫 번째 배치를 출력하면 다음과 같다.
for batch in dataset:
print(batch)
breaktf.Tensor(
[[ 1 2 9349 7888 739 7318 376 4 12557 6824 9108 9028
7098 25856 1 3 3 3 3 3 3 3 3 3
3 3 3 3 3 3]
[ 1 2 9020 8263 7497 10192 11615 8210 8006 4 12422 8711
9535 7483 12521 1 3 3 3 3 3 3 3 3
3 3 3 3 3 3]
... 중략 ...
[ 1 2 10464 9136 7380 9071 7513 8711 8210 8006 4 9054
7285 9117 7703 7788 11120 8705 14553 10667 8718 7055 7661 25856
1 3 3 3 3 3]], shape=(32, 30), dtype=int32)32개의 데이터를 보면 길이는 30으로 패딩되었으며 뒤에 채워진 패딩 토큰은 숫자 3이고, 각 데이터의 맨 앞에는 정수 1, 2가 부착되어 있다. 정수 1, 2는 앞에서 확인했던 것과 같이 각각 </s>와 <user>에 해당된다. 첫 번째 배치는 현재 batch라는 변수에 저장되어 있으므로, 32 개의 데이터 중 가장 첫 번째 샘플을 출력해보겠다. 이때 이미 정수 인코딩이 진행된 상황이므로 tokenizer.decode()를 통해 정수 인코딩 된 결과를 다시 복원하여 출력한다.
print(tokenizer.decode(batch[0]))
4) 챗봇 학습하기
# 옵티마이저 결정
adam = tf.keras.optimizers.Adam(learning_rate=3e-5, epsilon=1e-08)
# 전체 데이터의 개수를 배치 크기로 나누면 하나의 에포크에서 실행되는 학습 횟수가 계산됨.
steps = len(train_data) // batch_size + 1
EPOCHS = 3
for epoch in range(EPOCHS):
epoch_loss = 0
for batch in tqdm.tqdm_notebook(dataset, total=steps):
with tf.GradientTape() as tape:
result = model(batch, labels=batch)
loss = result[0]
batch_loss = tf.reduce_mean(loss)
grads = tape.gradient(batch_loss, model.trainable_variables)
adam.apply_gradients(zip(grads, model.trainable_variables))
epoch_loss += batch_loss / steps
print('[Epoch: {:>4}] cost = {:>.9}'.format(epoch + 1, epoch_loss))5) 챗봇 실행
사용자의 질문의 앞뒤에 <usr>와 <sys>를 부착한다. 그 후 해당 문장 앞에 시작 토큰에 해당하는 </s>를 부착한다.
text = '오늘도 좋은 하루!'
sent = '<usr>' + text + '<sys>'
input_ids = [tokenizer.bos_token_id] + tokenizer.encode(sent)
input_ids = tf.convert_to_tensor([input_ids])
print('정수 인코딩 후 :', input_ids)
print('정수 인코딩을 재복원 :', tokenizer.decode(input_ids[0]))정수 인코딩 후 : tf.Tensor([[ 1 2 10070 7235 10586 12557 376 4]], shape=(1, 8), dtype=int32)
정수 인코딩을 재복원 : </s><usr> 오늘도 좋은 하루!<sys>현재의 입력은 챗봇이 학습할 당시의 형태(</s><usr>사용자의 질문<sys>챗봇의 답변</s>)에서 챗봇의 답변이 바로 시작되기 전까지의 형태이다. 기존에 학습하였을 당시에는 <sys> 뒤에 챗봇의 답변이 있었으므로, 현재의 입력을 KoGPT-2에 입력으로 사용하면 챗봇은 학습 때 봤던 데이터의 형식 그대로 챗봇의 답변을 작성하려는 관성을 가지고 있다. 현재의 입력을 모델의 입력으로 넣고 모델이 생성하는 문장을 얻는다.
output = model.generate(input_ids, max_length=50, early_stopping=True, eos_token_id=tokenizer.eos_token_id)
decoded_sentence = tokenizer.decode(output[0].numpy().tolist())
print(decoded_sentence)
KoGPT-2의 출력은 사용자가 넣은 입력이었던 </s><usr> 오늘도 좋은 하루!<sys>도 포함하여 반환되므로, 챗봇의 답변만 확인하기 위해서는 <sys>를 기준으로 분할하여 뒷부분만 가져와야 한다.
print(decoded_sentence.split('<sys> ')[1].replace('</s>', ''))
만약 동일 질문에도 KoGPT-2의 답변이 무작위로 나오기를 바란다면, do_sample=True, top_k=10이라는 파라미터를 통해서 후보가 되는 단어 10 개 중 무작위로 선택하여 생성하도록 유도할 수 있다.
output = model.generate(input_ids, max_length=50, do_sample=True, top_k=10)
decoded_sentence = tokenizer.decode(output[0].numpy().tolist())
print(decoded_sentence.split('<sys> ')[1].replace('</s>', ''))def return_answer_by_chatbot(user_text):
sent = '<usr>' + user_text + '<sys>'
input_ids = [tokenizer.bos_token_id] + tokenizer.encode(sent)
input_ids = tf.convert_to_tensor([input_ids])
output = model.generate(input_ids, max_length=50, do_sample=True, top_k=20)
sentence = tokenizer.decode(output[0].numpy().tolist())
chatbot_response = sentence.split('<sys> ')[1].replace('</s>', '')
return chatbot_response
return_answer_by_chatbot('안녕! 반가워~')
<참고 문헌>
유원준/안상준, 딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/21694
박호현 교수님, 인공지능, 중앙대학교 전자전기공학부, 2024
