
6. 멀티 헤드 어텐션(Multi-head Attention)
가. 개념
트랜스포머 연구진은 한 번의 어텐션을 수행하는 것보다 여러 번의 어텐션을 병렬로 사용하는 것이 더욱 효과적이라고 판단하였다. 따라서 의 차원을 개로 나누어 의 차원을 가지는 Query(Q), Key(K), Value(V)에 대해 개의 병렬 어텐션을 수행한다. 이때 각각의 어텐션 값 행렬을 어텐션 헤드(Attention Head)라고 부른다.
예를 들어, 논문에서는 로 하여 개의 병렬 어텐션이 이루어졌으며, 차원의 각 단어 벡터를 로 나누어 차원의 Q, K, V 벡터로 변환하여 어텐션을 수행하였다. 각 어텐션 헤드마다 가중치 행렬 의 값은 모두 다르게 적용된다.
나. 병렬 어텐션의 효과
병렬 어텐션으로 모델은 여러 시점에서 각각 다른 시각으로 정보들을 수집할 수 있다. 이는 각 어텐션 헤드가 전부 다른 시각에서 정보를 처리하기 때문이다.
예를 들어, 다음의 문장에서
"그 동물은 길을 건너지 않았다. 왜냐하면 그것은 너무 피곤하였기 때문이다."
그것(it)이라는 단어가 쿼리(Query)라고 해보겠다.
첫 번째 어텐션 헤드는 그것(it)과 동물(animal)의 연관도를 높게 판단하는 반면, 두 번째 어텐션 헤드는 그것(it)과 피곤하였기 때문이다(tired)의 연관도를 높게 볼 수 있다. 이러한 다각적인 분석은 단어 간의 복합적인 관계를 파악하는 데 도움을 준다.
다. 어텐션 헤드 연결(Concatenation) 및 최종 출력
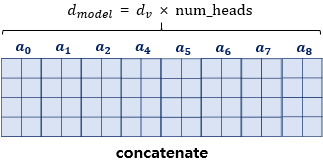
모든 병렬 어텐션을 수행한 후에는 모든 어텐션 헤드를 연결(concatenate)한다. 이렇게 연결된 어텐션 헤드 행렬의 크기는 다시 이 된다. 그리고 이 어텐션 헤드 행렬에 가중치 행렬 를 곱한다. 이에 따라 도출된 행렬이 멀티-헤드 어텐션의 최종 결과물이다.
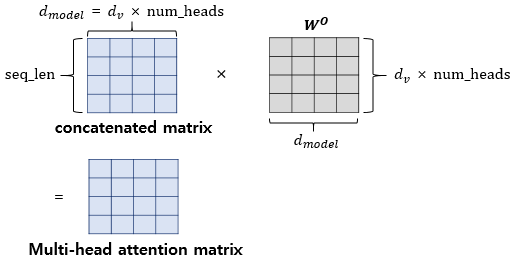
최종 결과물인 멀티-헤드 어텐션 행렬은 인코더의 입력이었던 문장 행렬의 크기인 과 동일하게 유지된다. 이는 인코더의 첫 번째 서브층인 멀티-헤드 어텐션 단계를 마쳤을 때도 입력 행렬의 크기가 보존됨을 의미한다.
라. 멀티 헤드 어텐션 구현 구성 요소
멀티 헤드 어텐션의 구현은 크게 다섯 가지 파트로 구성된다.
-
에 해당하는 크기의 Dense layer을 지나게 한다.
Keras코드 상에서는 입력을Dense()를 지나게 하여 가중치 행렬을 곱하는 방식을 사용한다. -
지정된 헤드 수()만큼 결과를 나눈다(split).
-
각 나눠진 헤드에 대해 스케일드 닷 프로덕트 어텐션(Scaled dot-product Attention)을 수행한다.
-
스케일드 닷 프로덕트 어텐션이 완료된 후, 나눠졌던 heads을 다시 연결(concatenation)한다.
-
연결된 헤드 행렬을 에 해당하는 Dense Layer을 지나게 한다.
이러한 과정을 통해 멀티 헤드 어텐션은 입력 시퀀스의 다양한 관점에서의 관계 정보를 효과적으로 추출하여 최종 출력으로 전달하게 된다.
7. 패딩 마스크(Padding Mask)
가. 패딩 마스크의 필요성
트랜스포머의 입력 문장에는 실질적 의미를 가지지 않는 <PAD> 토큰이 포함될 수 있다. 이러한 <PAD> 토큰은 어텐션 메커니즘의 유사도를 구하는 연산에서 사실상 제외되어야 한다. 그렇지 않는다면, 모델이 무의미한 정보에 집중하게 되어 학습 효율성과 성능에 부정적인 영향을 미칠 수 있다.
따라서 Key에 <PAD> 토큰이 존재하는 경우, 이에 대해서는 유사도를 구하지 않도록 마스킹(masking)을 적용해야 한다. 여기서 마스킹이란 어텐션에서 값을 가려서 제외하는 것을 의미한다.
나. 패딩 마스크의 동작 방식
① 어텐션 스코어 행렬
-
행(row): Query에 해당하는 문장
-
열(column): Key에 해당하는 문장
② 마스킹 대상
Key에 <PAD> 토큰이 있는 열 전체 마스킹
③ 마스킹 방법: 마스킹 위치에 매우 작은 음수를 삽입
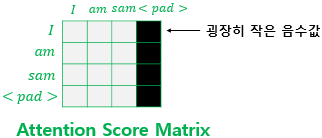
scores += mask * (-1e9)④ Softmax 적용 후
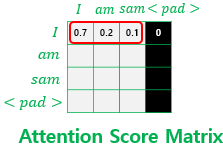
Softmax 함수를 거친 후, 마스킹 위치의 값은 이 된다. 결과적으로 <PAD> 토큰은 어텐션 가중치에 반영되지 않는다. 각 행의 어텐션 가중치 총합은 이며, <PAD> 열의 가중치만 이다.
다. 패딩 마스크 구현
패딩 마스크를 구현하는 방법은 입력된 정수 시퀀스에서 패딩 토큰의 인덱스인지 아닌지를 판별하는 함수를 구현하는 것이다. 다음 함수는 정수 시퀀스에서 0인 경우에는 1로 변환하고, 그렇지 않은 경우에는 0으로 변환한다.
def create_padding_mask(x):
mask = tf.cast(tf.math.equal(x, 0), tf.float32)
# (batch_size, 1, 1, key의 문장 길이)
return mask[:, tf.newaxis, tf.newaxis, :]8. 포지션-와이즈 피드 포워드 신경망(Position-wise FFNN)
가. FFNN의 역할 및 위치
포지션-와이즈 피드 포워드 신경망은 트랜스포머의 인코더와 디코더에서 공통적으로 사용되는 서브층이다.
하나의 인코더 층은 크게 총 2개의 서브층으로 나뉘는데, 이들은 멀티 헤드 셀프 어텐션과 포지션 와이즈 피드 포워드 신경망이다. 즉, FFNN은 멀티 헤드 어텐션 다음으로 오는 두 번째 서브층에 해당한다. FFNN은 어텐션 층에서 나온 결과를 변환하여 다음 층으로 전달하는 역할을 수행한다.
나. FFNN의 구조 및 행렬 크기
FFNN은 기본적으로 우리가 알고 있는 일반적인 피드 포워드 신경망이다. 이 신경망은 두 개의 선형 변환(Dense layer)으로 구성되며, 그 사이에 활성화 함수(ReLU)가 적용된다.
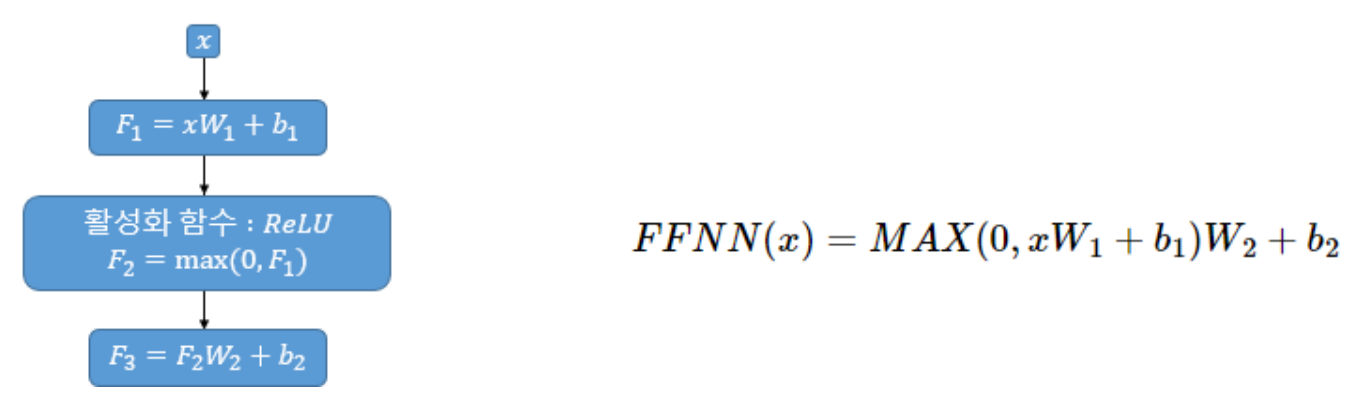
FFNN의 입력 는 이전 멀티 헤드 어텐션의 결과로 나온 크기의 행렬이다. 첫 번째 가중치 행렬 은 크기를 가진다. 논문에서 은닉층의 크기인 는 의 크기를 가진다고 명시되어 있다. 두 번째 가중치 행렬 는 크기를 가진다.
FFNN을 통한 연산은 다음과 같이 표현할 수 있다:
outputs = tf.keras.layers.Dense(units=dff, activation='relu')(attention)
outputs = tf.keras.layers.Dense(units=d_model)(outputs)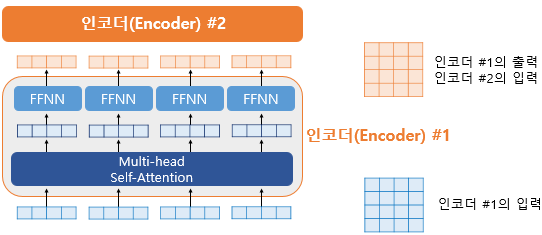
최종적으로 FFNN을 지난 후에도 인코더의 최종 출력은 인코더의 입력과 동일한 크기가 유지된다.
다. FFNN의 매개변수 공유
FFNN의 매개변수들은 하나의 인코더 층 내에서는 다른 문장, 다른 단어들마다 정확하게 동일하게 사용된다. 이는 모든 단어에 동일한 신경망을 적용한다는 의미이다. 하지만 다른 층에서는 다른 값을 가진다.
9. 잔차 연결(Residual connection)과 층 정규화(Layer Normalization)
가. 잔차 연결의 개념
트랜스포머에서는 인코더의 두 개의 서브층에 추가적으로 잔차 연결이라는 기법을 사용한다. 잔차 연결은 서브층의 입력과 출력을 더하는 것을 의미한다.
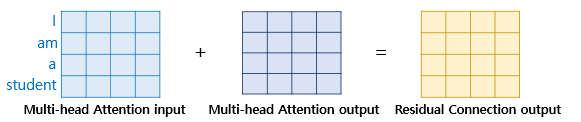
트랜스포머에서 서브층의 입력과 출력은 동일한 차원을 갖고 있으므로, 덧셈 연산을 수행할 수 있다. 이를 수식으로 표현하면
이다. 여기서 는 서브층의 입력이고, 는 서브층의 출력에 해당한다.
나. 층 정규화의 개념 및 동작
잔차 연결을 거친 결과는 이어서 층 정규화 과정을 거치게 된다. 층 정규화는 Tensor의 마지막 차원(트랜스포머에서는 차원)에 대해서 평균과 분산을 구하고, 이를 가지고 특정 수식을 통해 값을 정규화하여 학습을 돕는 기법이다.
층 정규화의 동작은 크게 두 가지 과정으로 나눌 수 있다.
① 평균과 분산을 통한 정규화
입력 벡터 의 각 차원 을 수식
을 사용하여 정규화한다. 여기서 는 해당 벡터의 평균이고, 는 분산이며, 은 분모가 0이 아닌 아주 작은 값이다.
② 감마()와 베타() 도입
정규화된 값에 학습 가능한 파라미터인 와 를 도입한다. 의 초기값은 1이고, 의 초기값은 0이다. 최종 수식은
와 같다. Keras에서는 층 정규화를 위해 LayerNormalization() 함수를 제공한다.
다. 잔차 연결과 층 정규화의 통합 적용
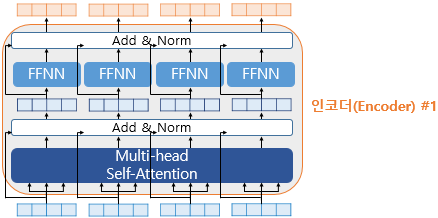
트랜스포머에서는 인코더와 디코더의 각 서브층에 Add & Norm이라는 기법을 추가적으로 사용한다. Add & Norm은 잔차 연결과 층 정규화를 통합하여 적용하는 것을 의미한다. 이는
라는 수식으로 표현될 수 있다. 즉, 서브층의 입력 와 서브층의 출력 를 먼저 더한 후에, 그 결과에 층 정규화를 적용하는 순서로 이루어진다.
10. 디코더(Decoder)의 구조
가. 디코더의 입력 및 교사 강요(Teacher Forcing)
트랜스포머의 디코더는 인코더와 마찬가지로 임베딩 층과 포지셔널 인코딩을 거친 후의 문장 행렬이 입력된다. 트랜스포머 역시 seq2seq 모델처럼 교사 강요(Teacher Forcing) 방식을 사용하여 훈련된다.
학습 과정에서 디코더는 번역할 문장에 해당되는 '<sos> je suis étudiant'과 같은 문장 행렬을 한 번에 입력받으며, 이 문장 행렬로부터 각 시점의 단어를 예측하도록 훈련된다.
나. 디코더의 첫번째 서브층
마스크드 멀티 헤드 셀프 어텐션과 룩-어헤드 마스크 디코더의 첫 번째 서브층은 마스크드 멀티 헤드 셀프 어텐션으로, 인코더의 첫 번째 서브층인 멀티 헤드 셀프 어텐션 층과 동일한 연산을 수행한다. 오직 다른 점은 어텐션 스코어 행렬에서 마스킹을 적용한다는 점이다.
1) 룩-어헤드 마스크의 필요성
RNN 계열의 신경망을 사용하는 seq2seq 디코더는 입력 단어를 매 시점마다 순차적으로 입력받으므로, 다음 단어 예측 시 현재 시점을 포함한 이전 시점에 입력된 단어만 참고할 수 있었다.
그러나 트랜스포머는 문장 행렬로 입력을 한 번에 받기 때문에, 현재 시점의 단어를 예측하고자 할 때 입력 문장 행렬로부터 미래 시점의 단어까지도 참고할 수 있는 현상이 발생한다.
예를 들어, 'suis'를 예측해야 하는 시점에 트랜스포머는 이미 전체 문장인 ‘<sos> je suis étudiant’를 입력받아 뒤의 단어까지 볼 수 있게 된다.
이러한 문제를 해결하고 현재 시점의 예측에서 현재 시점보다 미래에 있는 단어를 참고하지 못하도록 룩-어헤드 마스크(look-ahead mask)가 도입되었다.
2) 룩-어헤드 마스크의 동작 방식
룩-어헤드 마스크는 셀프 어텐션을 통해 얻은 어텐션 스코어 행렬에서 자기 자신보다 미래에 있는 단어들을 참고하지 못하도록 마스킹한다.
마스킹된 후의 어텐션 스코어 행렬의 각 행을 보면 자기 자신과 그 이전 단어들만을 참고할 수 있게 된다. 그 외에는 셀프 어텐션과 멀티 헤드 어텐션을 수행한다는 점에서 인코더의 첫 번째 서브층과 동일하다.
3) 룩-어헤드 마스크의 구현 및 패딩 마스크와의 관계
룩-어헤드 마스크는 패딩 마스크와 마찬가지로 scaled_dot_product_attention 함수의 mask 인자로 전달된다.
트랜스포머에는 총 세 가지 어텐션이 존재하며, 모두 멀티 헤드 어텐션을 수행하고, 멀티 헤드 어텐션 함수 내부에서 스케일드 닷 프로덕트 어텐션 함수를 호출한다. 각 어텐션 시 함수에 전달하는 마스킹은 다음과 같다.
-
인코더의 셀프 어텐션: 패딩 마스크 전달
-
디코더의 마스크드 셀프 어텐션: 룩-어헤드 마스크 전달
-
디코더의 인코더-디코더 어텐션: 패딩 마스크 전달
룩-어헤드 마스크는 패딩 마스크를 불필요하게 만들지 않으므로, 룩-어헤드 마스크는 패딩 마스크를 포함하도록 구현한다. 구현 방법은 마스킹을 하고자 하는 위치에는 1을, 마스킹을 하지 않는 위치에는 0을 리턴하도록 하는 함수를 만드는 것이다. 이 벡터에 매우 작은 음수값(-1e9)을 곱하고 행렬에 더해 해당 열을 마스킹한다.
다. 디코더의 두번째 서브층: 인코더-디코더 어텐션
디코더의 두 번째 서브층은 멀티 헤드 어텐션을 수행하지만, 셀프 어텐션이 아니다.
1) 인코더-디코더 어텐션의 Query, Key, Value
이 서브층에서는 인코더로부터 두 개의 화살표가 그려져 있으며, 이는 각각 Key와 Value를 의미한다.
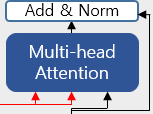
Key와 Value는 인코더의 마지막 층에서 온 행렬로부터 얻는다. 반면, Query는 디코더의 첫 번째 서브층의 결과 행렬로부터 얻는다.
2) 인코더-디코더 어텐션의 동작
Query가 디코더 행렬이고 Key가 인코더 행렬일 때 어텐션 스코어 행렬을 구하는 과정은 다른 어텐션과 유사하다. 그 외에 멀티 헤드 어텐션을 수행하는 과정은 다른 어텐션들과 동일하다.
<참고 문헌>
유원준/안상준, 딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/21694
박호현 교수님, 인공지능, 중앙대학교 전자전기공학부, 2024
