
1. 순환 신경망(Recurrent Neural Network, RNN)
가. Sequence Model
RNN은 입출력을 시퀀스(Sequence) 단위로 처리하는 시퀀스 모델이다. 예를 들어, 번역기의 입력은 번역 대상인 단어의 시퀀스인 문장이며, 출력인 번역된 문장도 단어의 시퀀스이다. 이렇게 시퀀스를 처리하기 위해 고안된 모델을 시퀀스 모델이라 하며, RNN이 가장 기본적인 인공 신경망 시퀀스 모델이다.
나. vs. 피드 포워드 신경망(Feed Forward Neural Network)
피드 포워드 신경망의 경우, 은직층에서 활성화 함수를 지난 값은 오직 출력층 방향으로만 향했다. 반면, RNN은 은닉층의 노드에서 활성화 함수를 통해 나온 결과값을 출력층 방향으로도 보내고, 다시 은닉층 노드의 다음 계산의 입력으로도 보낸다.
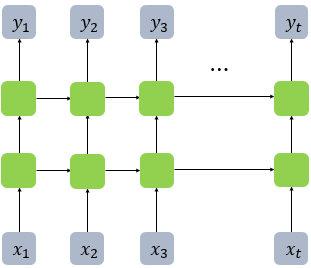
다. RNN Structure
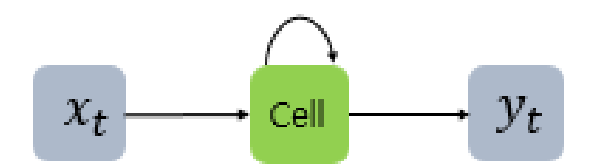
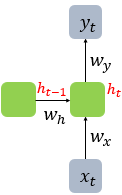
여기서 은 입력층의 입력 벡터, 은 출력층의 출력 벡터이다. RNN의 은닉층에서 활성화 함수를 통해 결과를 내보내는 역할을 하는 노드를 셀(cell) 이라고 한다. 이 셀은 이전의 값을 기억하는 메모리 역할을 하므로, 메모리 셀 또는 RNN 셀이라고도 부른다.
현재 시점을 변수 라고 할 때, 메모리 셀이 출력층 방향 또는 다음 시점인 의 자신에게 보내는 값을 은닉 상태(hidden state) 라고 한다.
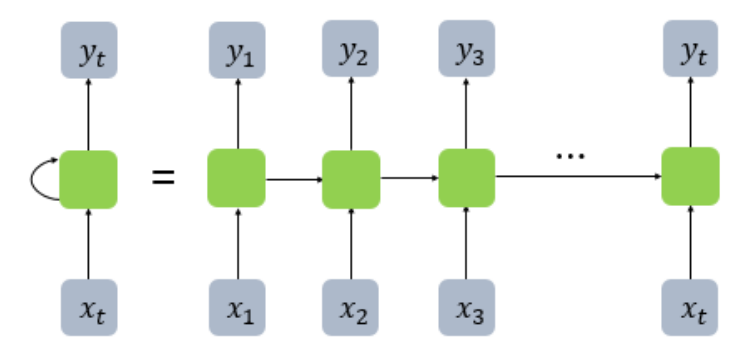
RNN은 위의 그림에서 좌측 또는 우측처럼 표현한다.
한편, 피드 포워드 신경망에서는 뉴런이라는 단위를 사용했지만, RNN의 경우, 입력층과 출력층에서는 각각 입력 벡터와 출력 벡터, 은닉층에서는 은닉 상태라는 표현을 주로 사용한다. 위의 그림에 있는 사각형들은 기본적으로 벡터 단위이다. 피드 포워드 신경망과의 비교를 위해, RNN을 뉴런 단위로 표현하면 다음과 같다.
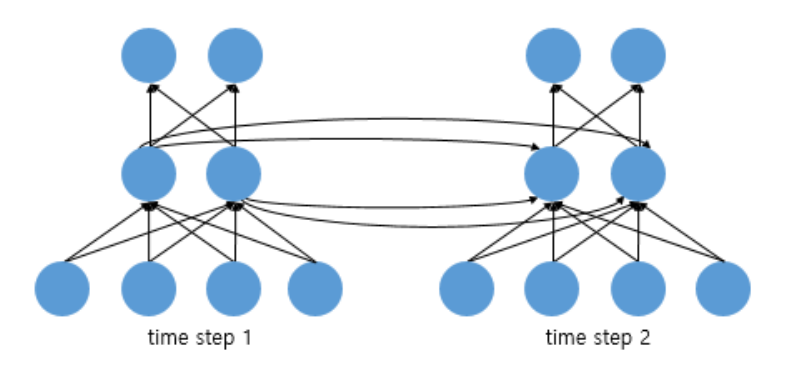
위의 그림은 입력 벡터의 차원이 4, 은닉 상태의 크기가 2, 출력층의 출력 벡터의 차원이 2인 RNN의 시점이 2일 때의 모습이다. 뉴런 단위로 바꾸면, 입력층의 뉴런 수는 4, 은닉층의 뉴런 수는 2, 출력층의 뉴런 수는 2이다.
라. RNN Types
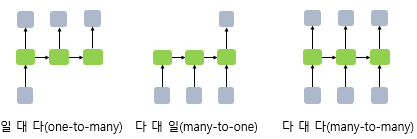
RNN은 위 그림과 같이, 다음 용도에 맞게 입출력 길이를 다양하게 하여 구성할 수 있다.
일대다(one-to-many): Image Captioning
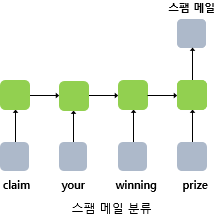
다대일(many-to-one): 감성 분류, 스팸 메일 분류
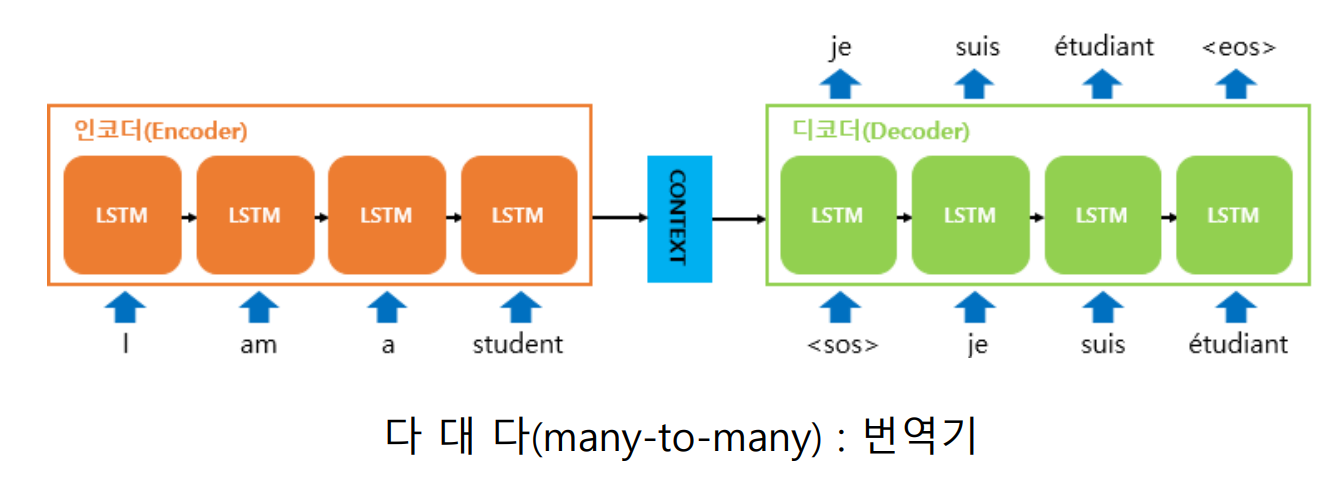
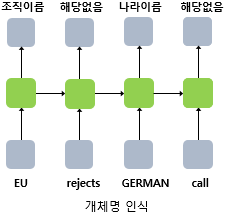
다대다(many-to-many): 번역기, 개체명 인식, 품사 태깅
마. RNN Mathematical Expression
- 은닉층:
- 출력층:
는 비선형 활성화 함수 중 하나.
RNN의 은닉층 연산을 벡터와 행렬 연산으로 표현하면 다음과 같다. 여기서 단어 벡터의 차원을 라고 하고, 은닉 상태의 크기를 라고 하겠다.
배치 크기를 1, 와 모두 4라고 하면 RNN의 은닉층 연산은 다음과 같다.

을 계산하기 위한 활성화 함수로는 보통 가 쓰인다. 그리고 은 하나의 층에서는 모든 시점에서 값을 동일하게 공유하지만, 은닉층이 2개 이상이면 각 은닉층에서의 가중치는 서로 다르다.
출력층에서 을 계산하기 위한 활성화 함수로는, 푸는 문제에 따라 다르다. 예를 들어, 이진 분류를 해야 한다면 출력층에 로지스틱 회귀를 사용하여 시그모이드 함수를 사용할 수 있고, 다중 클래스 분류를 해야 하면 소프트맥스 회귀를 사용하여 소프트맥스 함수를 사용할 수 있다.
2. Keras로 RNN 구현
3. Numpy로 RNN 구현
4. 깊은 순환 신경망(Deep Recurrent Neural Network)
RNN은 다수의 은닉층을 가질 수 있다. 다음 그림은 RNN에서 은닉층이 하나 더 추가된 것이다.
model = Sequential()
model.add(SimpleRNN(hidden_units, input_length=10, input_dim=5, return_sequences=True))
model.add(SimpleRNN(hidden_units, return_sequences=True))5. 양방향 순환 신경망(Bidirectional Recurrent Neural Network)
양방향 RNN은 시점 에서의 출력값을 예측할 때 이전 시점의 입력뿐만 아니라, 이후 시점의 입력 또한 예측에 기여할 수 있다는 아이디어에 기반한다.
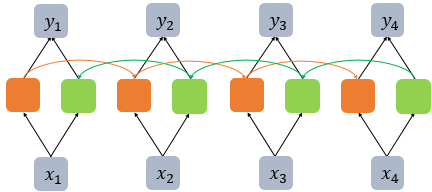
양방향 RNN은 하나의 출력값을 예측하기 위해 기본적으로 두 개의 메모리 셀을 사용한다. 첫 번째 메모리 셀은 앞 시점의 은닉 상태(Forward States) 를 전달 받아 현재의 은닉 상태를 계산한다. 위의 그림에서 주황색 메모리 셀에 대응된다. 두 번째 메모리 셀은 뒷 시점의 은닉 상태(Backward States) 를 전달받아 현재의 은닉 상태를 계산한다. 위의 그림에서 초록색 메모리 셀에 대응된다. 이렇게 이 두 개의 값 모두가 현재 시점의 출력층에서 출력값을 예측하기 위해 사용된다.
from tensorflow.keras.layers import Bidirectional
timesteps = 10
input_dim = 5
model = Sequential()
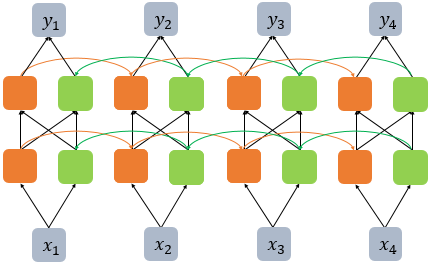
model.add(Bidirectional(SimpleRNN(hidden_units, return_sequences=True), input_shape=(timesteps, input_dim)))또한, 양방향 RNN은 다수의 은닉층을 가질 수 있다. 다음 그림은 양방향 RNN에 은닉층이 하나 더 추가된 것이다.
6. Training RNN
가. Training Process
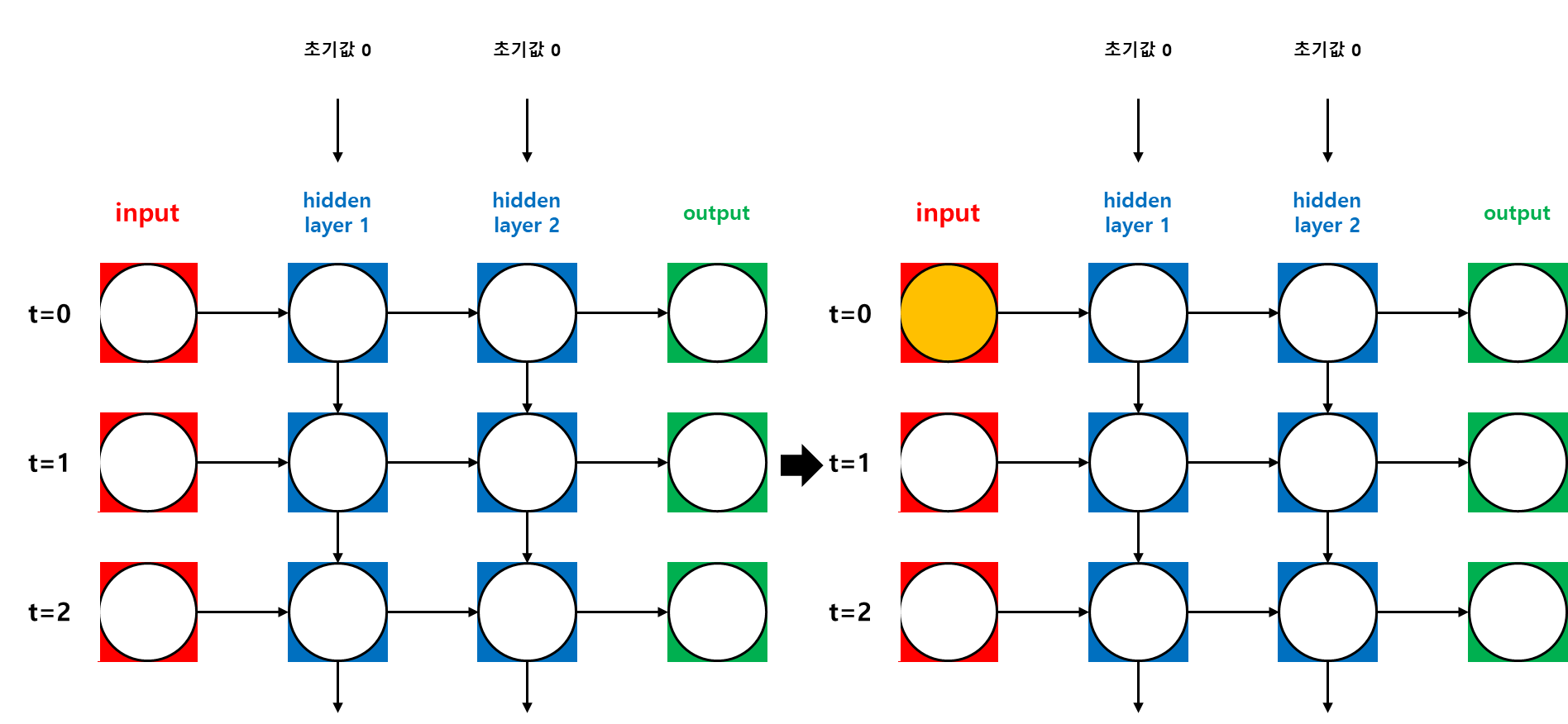
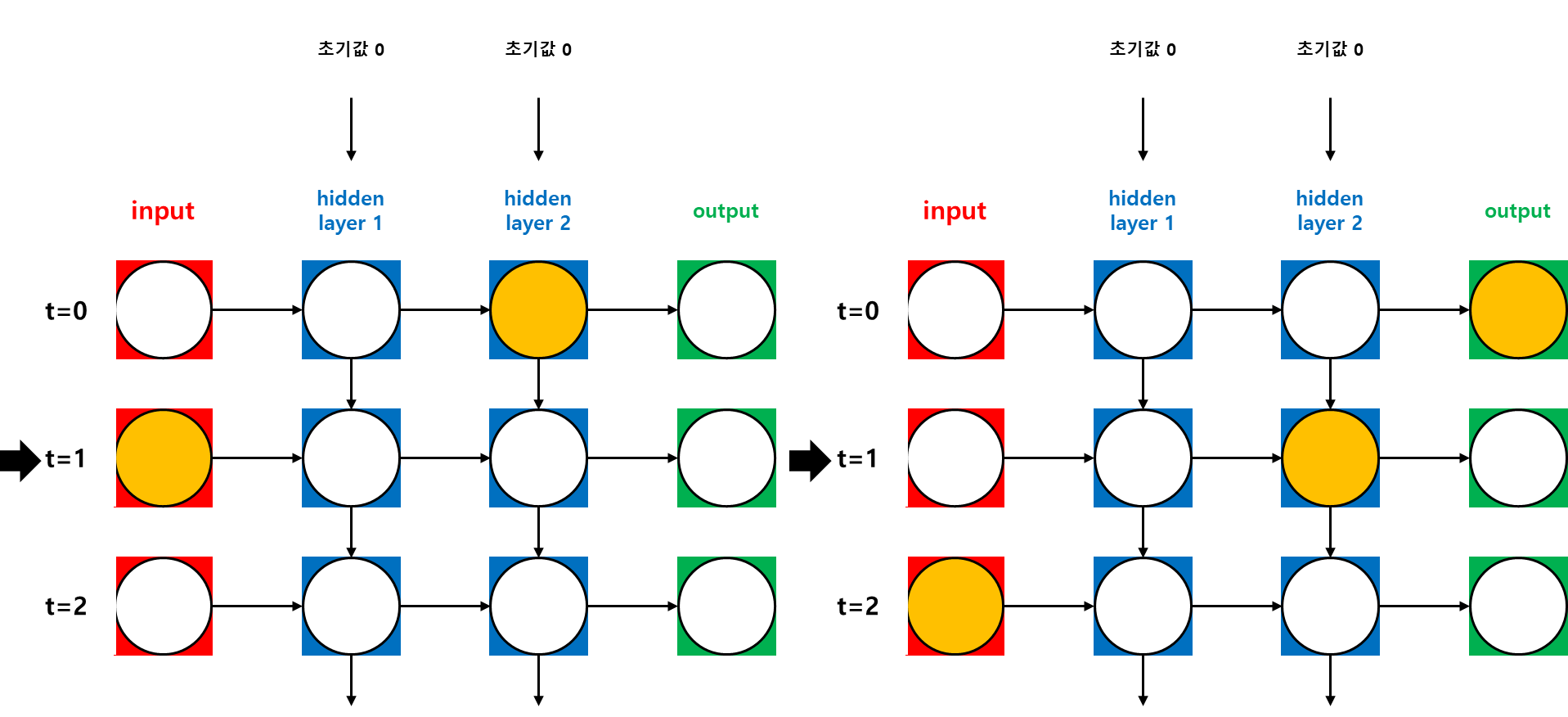
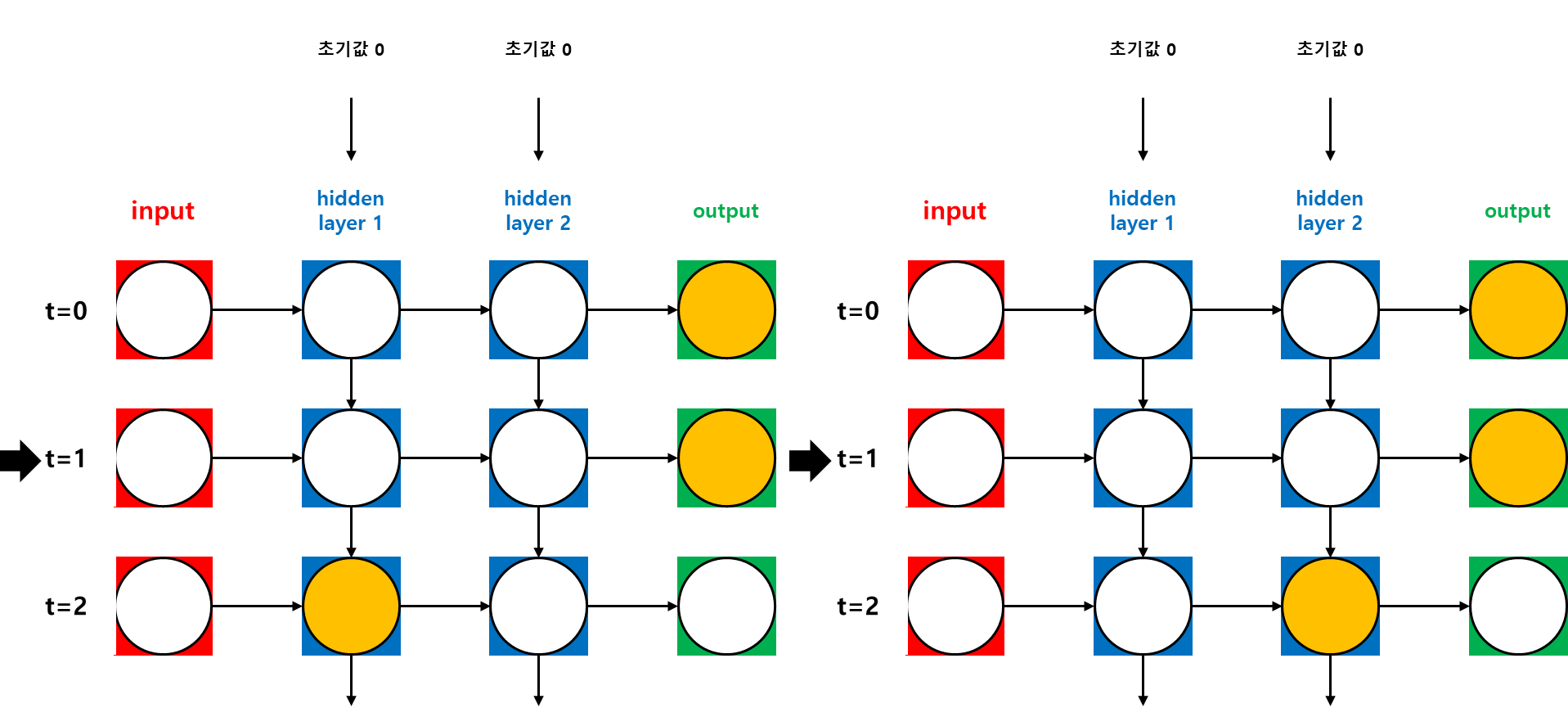
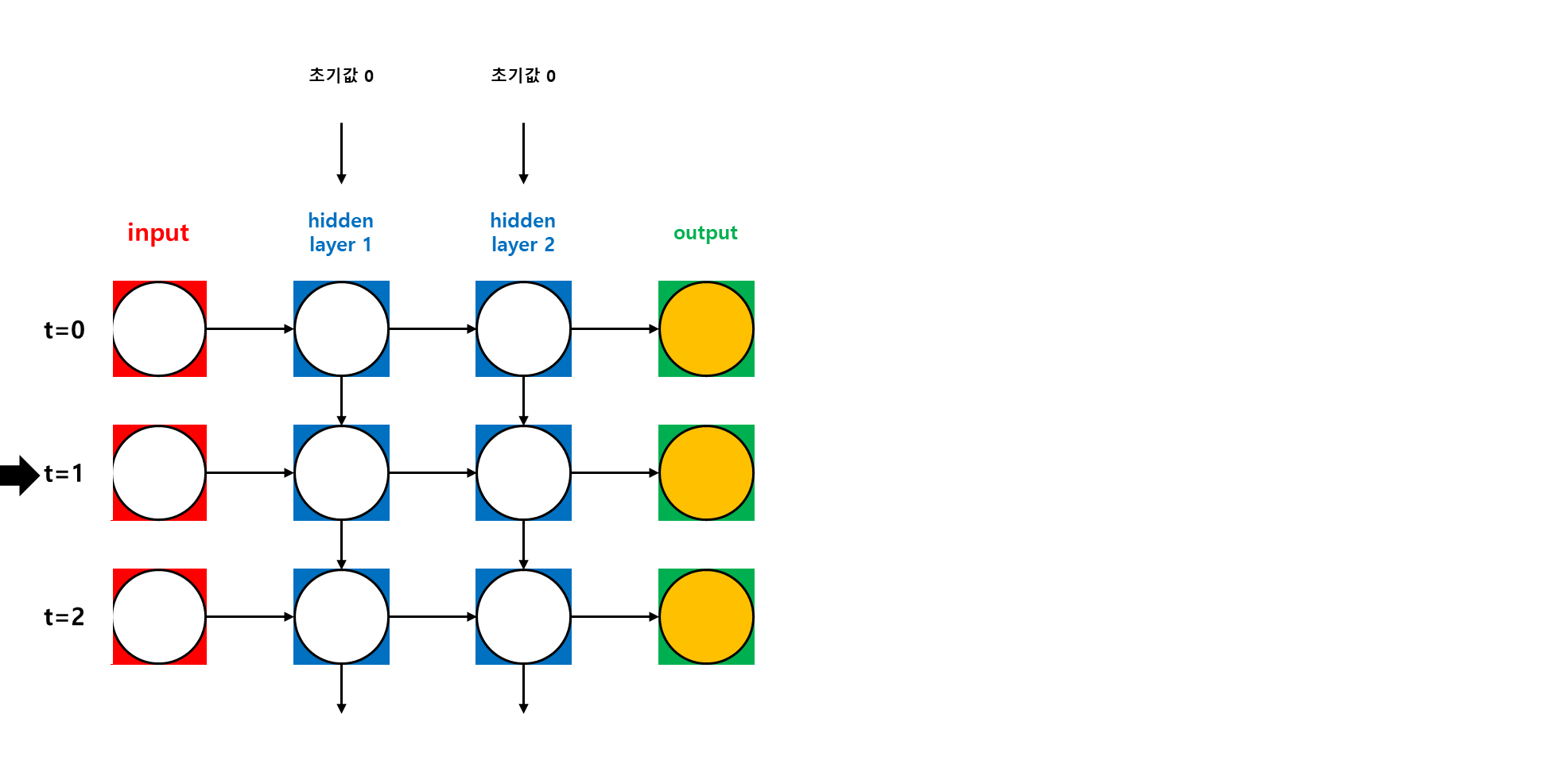
나. Back Propagation Through Time
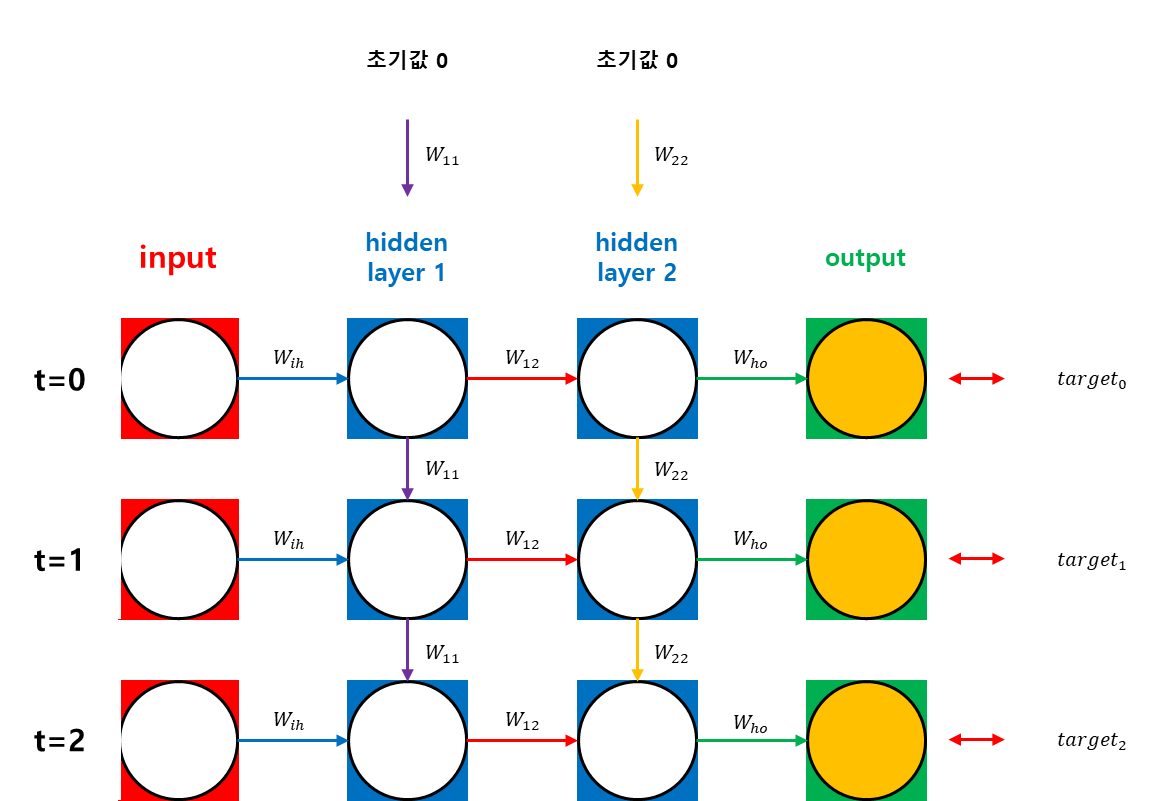
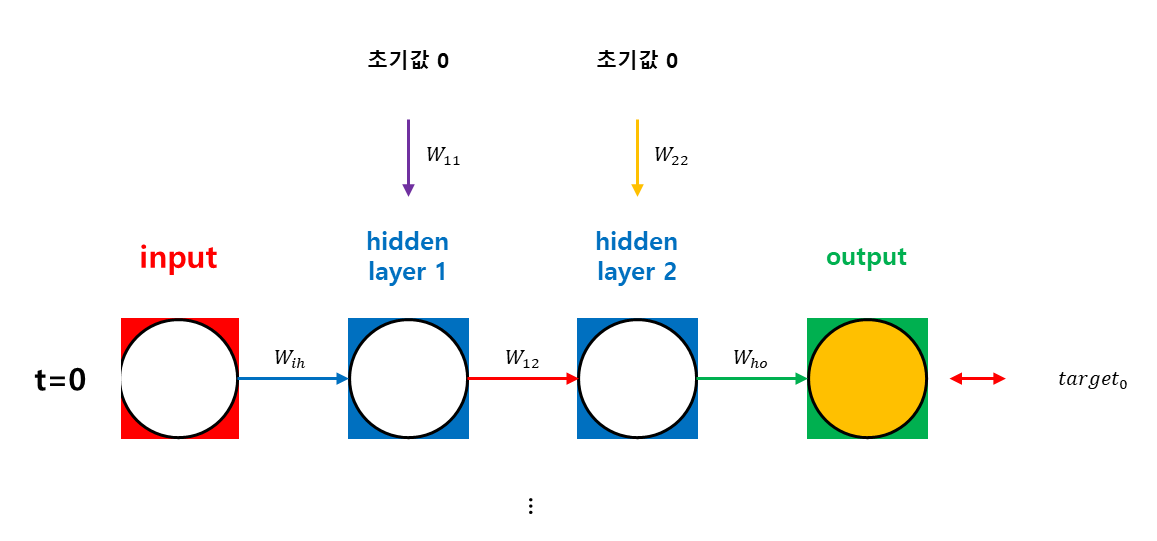
Recurrent Network이기 때문에 weight을 공유한다.
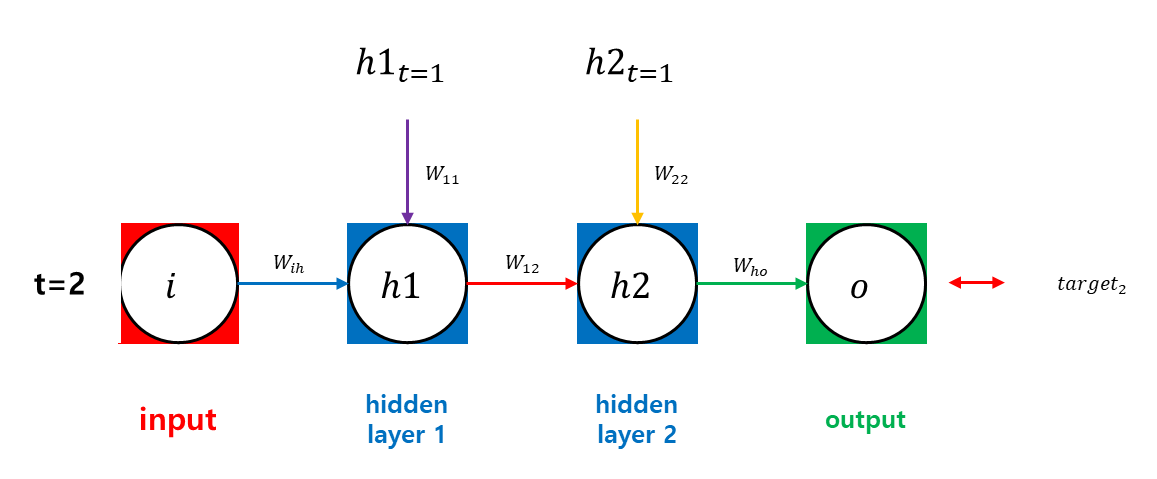
위 식에서 이다. 이를 계산하기 위해서는 까지 가야 한다. 다시 말해, 가중치 업데이트에 필요한 을 계산하기 위해서는 출력(targets)에 영향을 미치는 모든 시간 단계에 대해 gradient을 계산하고 합산해야 한다. 따라서 BPTT에서는 마지막 시점에서 시작하여 첫 번째 시점()까지 거슬러 올라가며 모든 그라디언트를 계산하게 된다.
한편, 가 늘어날수록 그 성능이 안 좋아진다. 역전파가 진행되면 함수의 미분도 여러 번 발생한다. 0과 1 사이의 값을 계속 곱하다 보면 gradient가 사라지고 종국적으로 해당 loss에 대해 학습이 되지 않는다. 이를 해결하기 위해 장기 기억을 추가해본다.
7. 장단기 메모리(Long Short-Term Memory, LSTM)
가. Vanilla RNN의 한계
Vanilla RNN은 출력 결과가 이전의 계산 결과에 의존한다. 그러나 Vanilla RNN은 비교적 짧은 시퀀스에 대해서만 효과를 보이는 단점이 있다. 이에 따라 time step이 길어질수록 앞의 정보가 뒤로 충분히 전달되지 못하는 현상이 발생한다. 이를 장기 의존성 문제(the problem of Long-Term Dependencies)라고 한다.
나. Vanilla RNN 내부
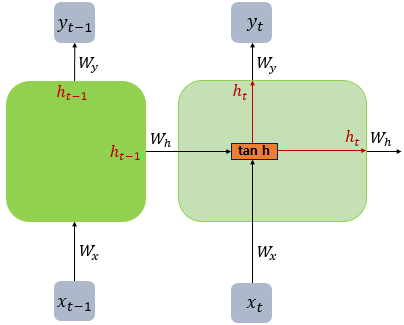
Vanilla RNN은 와 라는 두 개의 입력이 각각의 가중치와 곱해져 메모리 셀의 입력이 된다. 그리고 이를 함수의 입력으로 사용하고, 이 값은 은닉층의 출력인 은닉 상태가 된다.
다. LSTM
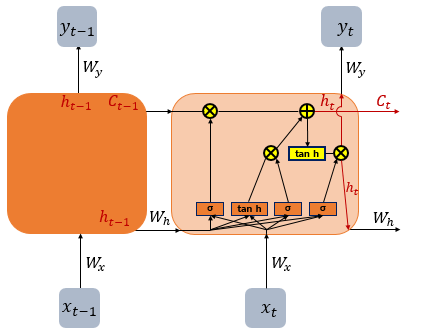
LSTM은 은닉층의 메모리 셀에 입력 게이트, 망각 게이트, 출력 게이트를 추가하여 불필요한 기억을 지우고, 기억해야 할 것들을 정한다. 다시 말해, LSTM은 은닉 상태를 계산하는 식이 기존의 RNN보다 조금 더 복잡해졌으며, 셀 상태(cell state) 가 추가되었다. 위 그림에서 시점의 셀 상태를 로 표현한다. LSTM은 RNN보다 긴 시퀀스의 입력을 처리하는데 탁월한 성능을 보인다.
① 입력 게이트
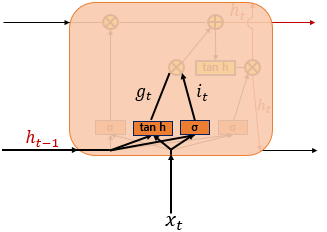
sigmoid 함수를 지나 0과 1 사이의 값을 가지는 와 함수를 지나 -1과 1 사이의 값을 가지는 로, 기억할 정보의 양을 정한다.
② 삭제 게이트
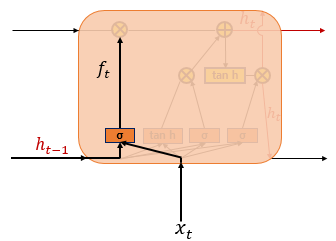
sigmoid 함수를 지나면 0과 1 사이의 값이 나오는데, 이 값이 곧 삭제 과정을 거친 정보의 양이다. 0에 가까울수록 정보가 많이 삭제된 것이고, 1에 가까울수록 정보를 온전히 기억한 것이다.
③ 셀 상태
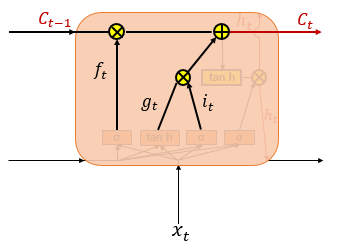
ⓐ 삭제 게이트 이라면?
이전 시점의 셀 상태 값인 은 현재 시점의 셀 상태의 값을 결정하기 위한 영향력이 아예 없어서 오직 입력 게이트의 결과만이 현재 시점의 셀 상태의 값 을 결정한다.
ⓑ 입력 게이트 이라면?
은 오직 에만 의존한다.
결론적으로, 삭제 게이트는 이전 시점의 입력을 얼마나 반영할지를, 입력 게이트는 현재 시점의 입력을 얼마나 반영할지를 결정한다.
④ 출력 게이트와 은닉 상태
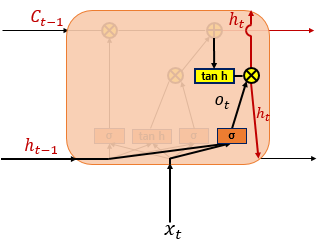
8. 게이트 순환 유닛(Gated Recurrent Unit, GRU)
GRU은 삭제 게이트와 입력 게이트를 Update gate 하나로 합치고, 셀 상태와 은닉 상태도 하나로 합친 것으로, LSTM의 성능과 유사하게 하되, 복잡했던 LSTM의 구조를 간단하게 하였다.
가. GRU의 구조
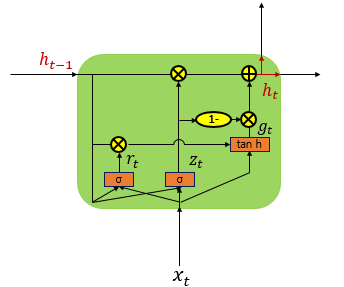
← Update Gate
← Reset Gate
← New Hidden State
GRU은 업데이트 게이트와 리셋 게이트 두 개만 존재한다.
나. Keras에서의 GRU
model.add(GRU(hidden_size, input_shape=(timesteps, input_dim)))9. Keras의 SimpleRNN과 LSTM
10. RNN 언어 모델(RNNLM)
n-gram 언어 모델과 NNLM은 단어를 고정된 개수만큼만 입력받아야 한다는 단점이 있었다. 그런데 time step이라는 개념이 도입된 RNN으로 언어 모델을 만들면 입력의 길이를 고정할 필요가 없다.
가. 교사 강요(teacher forcing)
what will the fat cat sit on
언어 모델은 주어진 단어 시퀀스로부터 다음 단어를 예측하는 모델이다. 다음 그림은 RNNLM이 어떻게 이전 시점의 단어들과 현재 시점의 단어로 다음 단어를 예측하는지 보여준다.
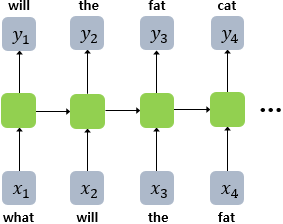
RNNLM은 기본적으로 예측 과정에서 이전 시점의 출력을 현재 시점의 입력으로 한다. 즉, what을 입력 받으면, will을 예측하고, 이 will은 다음 시점의 입력이 되어, the을 예측한다. 이러한 원리로, 세 번째 시점에서 fat은 앞서 나온 what, will, the라는 시퀀스로 인해 결정된 단어인 것이다.
사실 상기 과정은 훈련이 끝난 모델이 실제 사용될 때에 관한 것이다. 훈련 과정에서는 이전 시점의 예측 결과를 다음 시점의 입력으로 넣으면서 예측하는 것이 아니라, what will the fat cat sit on이라는 훈련 샘플이 있다면, what will the fat cat sit 시퀀스를 모델의 입력으로 넣으면, will the fat cat sit on을 예측하도록 훈련된다. will, the, fat, cat, sit, on은 각 시점의 레이블이다.
이러한 RNN 훈련 기법을 교사 강요라고 한다. 교사 강요란, 테스트 과정에서 시점의 출력이 시점의 입력으로 사용되는 RNN 모델을 훈련시킬 때 사용되는 훈련 기법이다. 훈련할 때 교사 강요를 쓰면, 모델이 시점에서 예측한 값을 시점에 입력으로 사용하지 않고, 시점의 레이블, 즉, 실제 알고 있는 정답을 시점의 입력으로 사용한다.
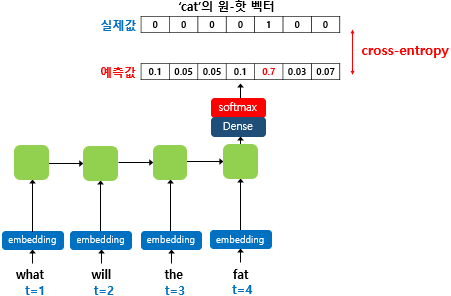
훈련 과정 동안 출력층에서 사용하는 활성화 함수는 소프트맥스 함수이다. 그리고 모델이 예측한 값과 실제 레이블과의 오차를 계산하기 위해서 손실 함수로 크로스 엔트로피 함수를 사용한다.
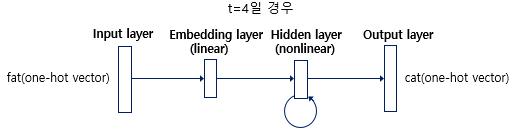
RNNLM은 위와 같이 총 4개의 layers로 이루어진 인공 신경망이다. 현재 timestep은 4로 하겠다. 그래서 네 번째 입력 단어인 fat의 one-hot 벡터가 입력이 된다. 한편, 모델이 예측해야 하는 정답에 해당하는 단어 cat의 one-hot 벡터는 출력층에서 모델이 예측한 값의 오차를 구하기 위해 사용될 예정이다. 그리고 이 오차로부터 손실 함수를 사용해 인공 신경망이 학습을 하게 된다.
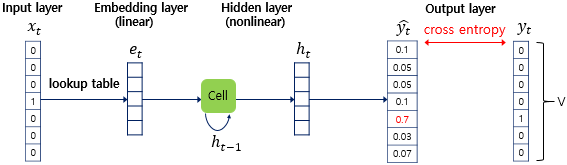
현재 time step의 입력 단어의 one-hot 벡터 을 입력받은 RNNLM은 임베딩층(Embedding Layer) 을 지난다. NNLM에서 룩업 테이블을 수행하는 층을 투사층(Projection Layer) 이라고 하였고, 투사층의 결과로 얻는 벡터를 임베딩 벡터라고 하였다. 임베딩층은 임베딩 벡터를 얻는 투사층인 것이다.
단어 집합의 크기가 일 때, 임베딩 벡터의 크기를 이라 하면, 각 입력 단어들은 임베딩층에서 크기의 임베딩 행렬과 곱해진다.
임베딩층:
은닉층:
출력층:
룩업 테이블의 대상이 되는 테이블인 임베딩 행렬을 라고 했을 때, 결과적으로 RNNLM에서, 학습 과정에서 학습되는 가중치 행렬은 4개이다.
<참고 문헌>
유원준/안상준, 딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/21694
박호현 교수님, 인공지능, 중앙대학교 전자전기공학부, 2024
