
1. 단어를 표현하는 다양한 방법
가. 단어의 표현 방법
① 국소 표현(Local Representation) 방법
해당 단어 그 자체만 보고 특정값을 맵핑하여 단어를 표현하는 방법이며, 이산 표현(Discrete Representation)이라고도 한다. 예를 들어, puppy(강아지), cute(귀여운), lovely(사랑스러운)라는 단어가 있을 때, 각 단어에 1번, 2번, 3번 등 숫자를 맵핑하여 부여하는 것이다. 그런데 이 방식은 단어의 의미나 뉘앙스를 표현할 수 없다.
② 분산 표현(Distributed Representation) 방법
어떤 단어를 표현하고자 주변을 참고하여 단어를 표현하는 방법이며, 연속 표현(Continuous Representation)이라고도 한다. 예를 들어, puppy(강아지)라는 단어 근처에는 주로 cute(귀여운), lovely(사랑스러운)이라는 단어가 자주 등장하므로, puppy라는 단어는 cute, lovely한 느낌이라고 정의하는 것이다. 따라서 단어의 뉘앙스를 표현할 수 있다.
2. Bag of Words(BoW)
단어들의 순서는 고려하지 않고, 단어들의 출현 빈도에만 집중하는 텍스트 데이터의 수치화 표현 방법이다. 이를 만드는 과정은 다음과 같다.
① 각 단어에 고유한 정수 인덱스를 부여(단어 집합 생성)
② 각 인덱스의 위치에 단어 토큰의 등장 횟수를 기록한 벡터(BoW) 생성
가. 문서 단어 행렬(Document-Term Matrix, DTM)
다수의 문서에서 등장하는 각 단어들의 빈도를 행렬로 나타낸 것이다. 즉, BoW 표현을 다수의 문서에 대해서 행렬로 표현한 것이다. 행과 열을 반대로 선택하면 TDM이라고도 부른다. 다음은 예시이다.
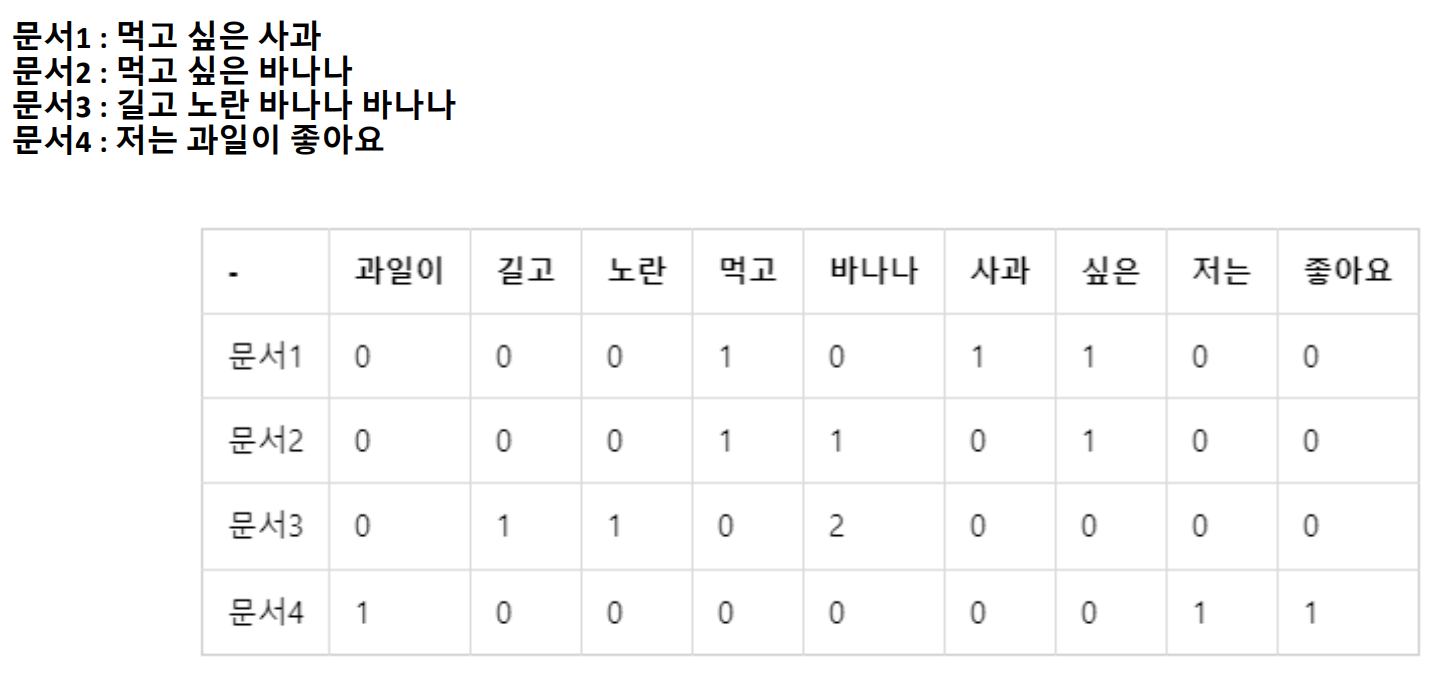
이 방식은 다음의 한계가 있다.
① 희소 표현(Sparse representation)
DTM에서의 각 행을 문서 벡터라고 하면, 각 문서 벡터의 차원은 one-hot vector와 마찬가지로 전체 단어 집합의 크기를 가진다. 만약 가지고 있는 전체 코퍼스가 방대한 데이터라면, 문서 벡터의 차원은 수만 이상의 차원을 가질 수도 있다. 희소 벡터(sparse vector) 또는 희소 행렬(sparse matrix)은 많은 양의 저장 공간과 높은 계산 복잡도를 요구한다.
② 단순 빈도 수 기반 접근
각 문서에는 중요한 단어와 불필요한 단어가 혼재되어 있다. 불용어와 같은 단어들은 빈도수가 높더라도 NLP에 있어 의미를 가지지 못해, 쓸데없이 높은 빈도 수만 차지하여 DTM의 불용어와 중요한 단어에 대해 각각 가중치를 줄 필요가 있다.
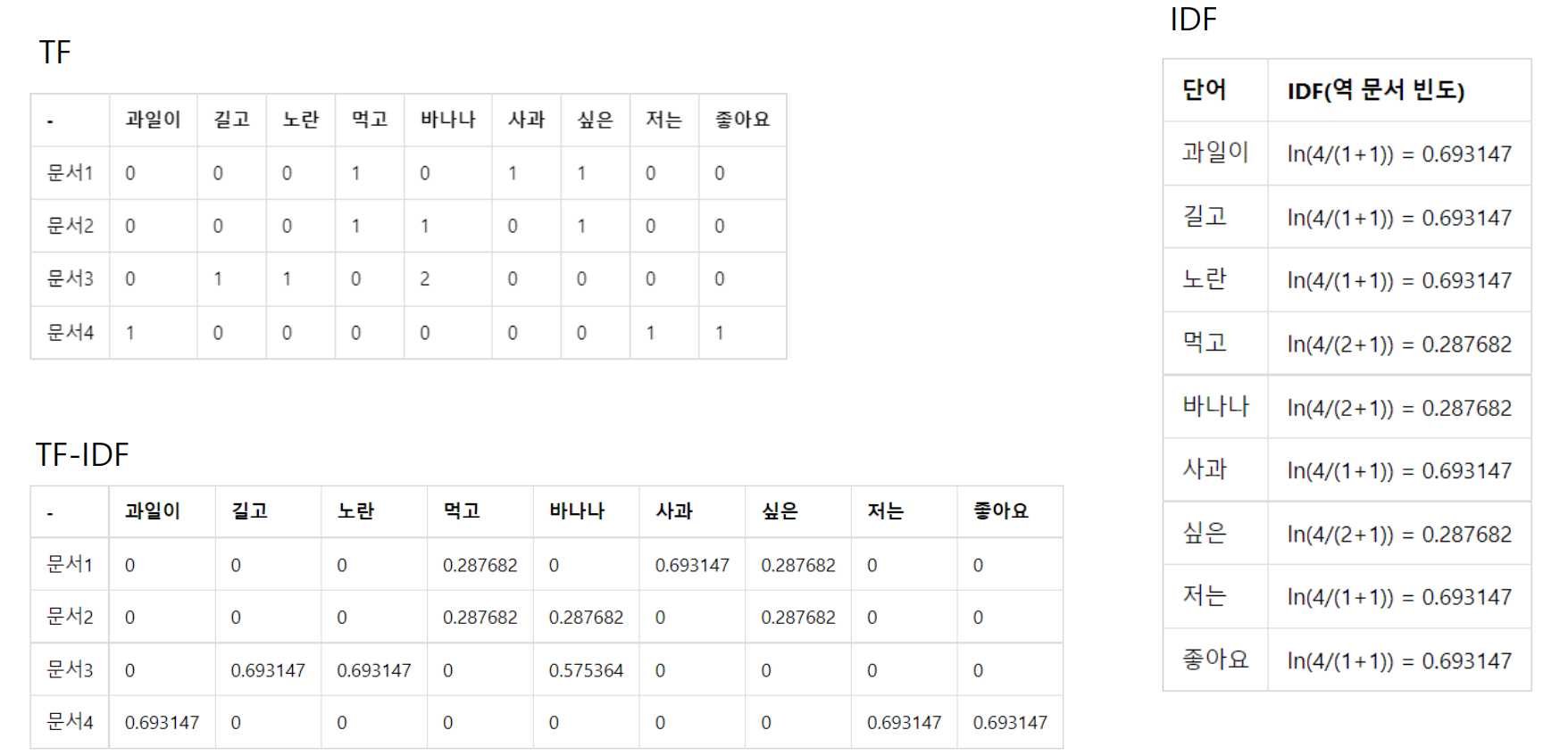
나. TF-IDF
TF-IDF(단어 빈도-역 문서 빈도, Term Frequency-Inverse Document Frequency) 는 단어의 빈도와 역 문서 빈도(문서의 빈도에 특정 식을 취함)를 사용하여 DTM 내 각 단어들마다 중요한 정도로 가중치를 부여하는 방법이다. 모든 문서에서 빈번하게 등장하는 단어는 중요도가 낮다고 판단하고, 특정 문서에서만 자주 등장하는 단어는 중요도가 높다고 판단한다. 이 방법은 문서의 유사도를 구하는 작업, 검색 시스템에서 검색 결과의 중요도를 정하는 작업, 문서 내에서 특정 단어의 중요도를 구하는 작업 등에 쓰일 수 있다.
TF-IDF은 TF와 IDF을 곱한 값을 의미한다. 문서를 , 단어를 , 문서의 총 개수를 이라고 표현하면 TF, DF, IDF는 각각 다음과 같이 정의할 수 있다.
: 특정 문서 에서의 특정 단어 의 등장 횟수
: 특정 단어 가 등장한 문서의 수
: 에 반비례하는 수
한편, 위 식을 보면 알 수 있듯이, IDF는 log-scale로 다뤄진다. 불용어 등 자주 쓰이는 단어들은 비교적 자주 쓰이지 않는 단어들보다 최소 수십 배 이상 빈번하게 등장한다. 그런데 자주 쓰이지 않는 단어들도 희귀한 단어들과 비교하면 최소 수백 배 이상 빈번하게 등장한다. 따라서 log-scale로 다루지 않으면, 희귀 단어들에 엄청난 가중치가 부여될 우려가 있다.
<참고 문헌>
유원준/안상준, 딥러닝을 이용한 자연어 처리 입문
https://wikidocs.net/21694
박호현 교수님, 인공지능, 중앙대학교 전자전기공학부, 2024
