1. print
1.1 print 규칙
print()에서 괄호 안 그대로 출력된다. ''가 있는 경우 문자로 인식하여 숫자도 문자처럼 인식한다.
print(1+2) # 결과값 3
print('1+2') # 결과값 1+2- 유의사항
print('12'-3)위 코드는 12는 문자, 3은 숫자 데이터인데 12-3으로 표시하게 되면 12가 숫자 데이터인지 문자 데이터인지 구분할 수 없기에 출력시 오류 발생
1.2 연산자 및 기본 기호
1.2.1 +
숫자는 더하고, 문자 데이터는 연결한다. (ex. 집에+갈래 -> 집에갈래)
1.2.2 ,
데이터 사이 한 칸의 공백 생성
1.2.3 기타 연산자
- : 곱셈
** : 거듭제곱
/ : 나눗셈
// : 나눗셈의 몫
% : 나눗셈의 나머지
1.2.4 연습문제
print('집'*3) #출력값: 집집집2. input
2.1 input
데이터를 입력받는다. (문자, 숫자 다 가능)
3. 변수
3.1 정수값을 저장할 때
앞서 언급한 input 함수와 int를 활용한다.
p=3.14
r=int(input('반지름 값 입력'))
result = p*r**2
print(result)- 반지름 값 입력시 input 앞에 int을 넣지 않으면 오류가 발생하는 이유: input은 숫자와 문자 데이터을 모두 입력 받을 수 있다. result 과정에서 사칙연산이 진행되기에 int을 활용해 '난 숫자(정수) 데이터만 받아서 연산할거야'라고 밝히는 것
4. if
4.1 if의 들여쓰기
if 함수를 쓰다보면 자동으로 들여쓰기가 되는 걸 볼 수 있다. 이는 if 밑에 나오는 조건이 if 산하에 있을 때 들여쓴다고 볼 수 있다. 예를 통해 설명해보겠다.
age = int(input('나이를 입력하세요'))
if age > 19:
print('성인입니다')
else:
print('미성년자입니다')위 코드에서 '성인입니다'를 출력하기 위해서는 19살 초과여야한다는 조건이 먼저 성립되어야 한다. 즉, if의 경우 특정 행동을 할 때 if에 적힌 조건이 전제 된다면 들여쓴다. (포함관계라고 생각하면 조금 더 쉬울 것이라 생각한다.)
4.2 elif와 else
if로만은 모든 조건을 다 표기하기 어렵다. 좀 더 간단한 코딩을 위해 elif와 else를 사용한다. elif의 경우 조건이 여러 가지일 때 if 다음으로 사용하고, else는 위 조건을 제외한 나머지 조건을 말할 때 사용한다.
즉 사용 순서를 정리하면 if -> elif (원하는 만큼) -> else 의 구조라고 할 수 있다.
4.3 기타 유의사항
if, elif, else 모두 각 조건의 끝에 : 를 써야한다.
ex. if i > 1: else:
5. for
5.1 for 함수의 구조
for i in range(a,b,c)라면 a부터 b-1까지의 범위에서 c만큼 증가한다는 것으로, a가 생략되면 0부터 시작하고 c가 생략되면 1씩 증가한다.
case1. 0부터 n-1까지
for i in range(n):
print(i)case2. a부터 b-1까지
for i in range(a, b):
print(i)case3. a부터 b-1까지 n만큼 증감하면서
print(i)- print(i, end=' ')의 의미: i를 출력하고 범위가 끝나면 줄바꿈 대신 공백을 출력한다는 뜻이다. ' '안에 다른 걸 넣으면 다른 문자로 출력된다.
5.2 for 들여쓰기 및 규칙
for도 if와 마찬가지로 작성한 뒤 : 표기 및 들여쓰기가 필요하다.
6. while
6.1 while
조건이 참인 동안 반복해서 실행 후 조건이 거짓되면 반복을 멈춘다. 조건문에 오류가 있으면 계속 반복될 수도 있는 이런 경우 무한 루프 라고 부른다.
a = 1
sum = 0
while sum <= 10:
sum = sum + a
a = a+1
print(sum)6.2 while 들여쓰기 및 규칙
while도 if, for과 마찬가지로 작성한 뒤 : 표기 및 들여쓰기가 필요하다.
6.3 함수 내 변수 재정의
sum=sum+10과 같은 코드는 어떻게 해석해야 할까? 등호 기준 오른쪽 sum은 처음 저장된 값을, 왼쪽 sum은 10이 더해져 업데이트된 값을 의미한다.
7. 배열
7.1 리스트
숫자나 문자 등을 주어진 순서에 따라 저장하는 데이터 타입을 말한다. index는 0번부터 시작한다!!
list = ['권유빈', '권은수', '이민주', '류희진']
list[2] = 이민주7.2 리스트 내 명령어
은근 뭐가 많아요..ㅎㅎ 예시를 보면서 이해하면 좀 더 쉬울 것 같아 다음 리스트를 가지고 설명해볼게요
이 리스트에 대해서 명령어를 적용해볼게요
1. append(항목) : 리스트 마지막에 항목 추가
fruits.append('orange')
print(fruits) #출력값 ['apple', 'banana', 'apple', 'cherry', 'banana', 'orange']- remove(항목) : 리스트의 항목 삭제
fruits.remove('apple')
print(fruits) #출력값 ['banana', 'apple', 'cherry', 'banana', 'orange']
- count(항목) : 특정 항목이 리스트에 몇 개 있는지 개수 셈
print(fruits.count('banana')) #출력값 2- index(항목): 리스트에서 항목이 나타나는 위치 조사 (0번부터 시작)
print(fruits.index('cherry')) #출력값 2- len(list명): 리스트 크기 (리스트 전체 항목 수)
print(len(fruits)) #출력값 5- sort(): 리스트 오름차순 정렬
fruits.sort()
print(fruits) # 출력값 ['apple', 'banana', 'banana', 'cherry', 'orange']- 항목 in list명: 리스트에 항목이 있는가? (True / False로만 판정)
print('apple' in fruits) #출력값 True
print('grape' in fruits) #출력값 False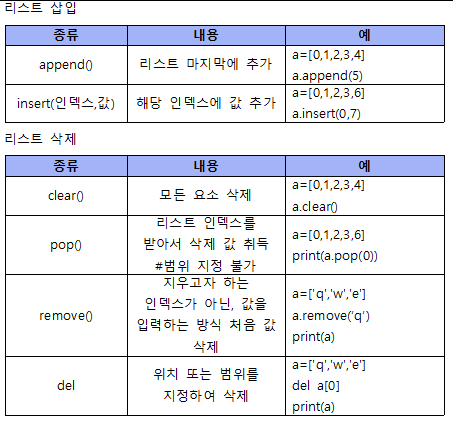
8. 함수
8.1 함수 정의
함수 정의는 def를 사용한다. 사실 어쩌면 여기가 제일 헷갈릴 수도 있다..ㅎㅎ
def f(x):
y=2*x+1
return y위와 같은 코드를 통해 설명해보자. 우선 def를 통해 새로운 함수 f(x)를 정의했다. 우리는 앞으로 f(x)를 y라고 하기로 약속했어요~ 왜냐하면 return이라는 게 있기 때문! f(x)를 y로 돌려준다(=출력한다)고 이해하면 돼요. 근데 코드 안에 보면 y를 2x+1이라고 정의한 거에요.
복잡해져서 정리하자면 그냥 f(x)를 y=2x+1이라고 정의했다고 이해하면 됩니당
위와 같이 f(x)라는 함수를 정의하면 뭐가 좋냐? y=2x+1 연산을 할 때 이 식을 또 쓰지 않고 사용이 가능해요 (마치 복잡한 함수 치환하는 감성)
result = f(3)
print(result)이걸 실행하면 이제 f(x)에 3을 넣은 값이 자동으로 계산됩니다
8.2 함수의 특징
- 프린트에 있길래 적어봤어요..ㅎㅎ 가볍게 읽어보는 정도로~
- 복잡하고 큰 프로그램을 작은 단위의 여러 부분 프로그램으로 나눌 수 있다.
- 프로그램을 기능 중심으로 단순하고 이해하기 쉽게 표현할 수 있다.
- 중복되는 부분을 함수로 만들어 반복호출함으로써 코드의 불필요한 중복을 최소화할 수 있다.
- 프로그램의 크기를 줄일 수 있고 오류 발생시 수정하기가 용이하다.
- 함수를 재사용함으로써 프로그래밍의 생산성을 높일 수 있다.
9. 정렬과 탐색
9.1 정렬
9.1.1 버블 정렬 (시간복잡도 )
버블 정렬이란 맨 처음 값과 그 다음 값을 비교하여 처음 값이 더 크다면 두 값의 자리를 바꾸고, 더 작다면 두 값을 그대로 유지한채 다음 값으로 넘어간다. 이 과정을 맨 끝에 도달할 때까지 반복하는 것이라고 할 수 있다.
def bubble_sort(arr): # bubble_sort라는 함수 정의
n = len(arr) # arr의 길이를 n이라고 정의
for i in range(n):
swapped = False # 처음에는 교환 없다고 가정하고 시작
# 마지막 i개 요소는 이미 정렬됨
for j in range(0, n-i-1):
# 인접한 두 요소를 비교하여 필요시 교환
if arr[j] > arr[j+1]:
arr[j], arr[j+1] = arr[j+1], arr[j]
swapped = True
# 교환이 없었다면 이미 정렬된 상태
if not swapped:
break
return arr9.1.2 선택 정렬 (시간복잡도 )
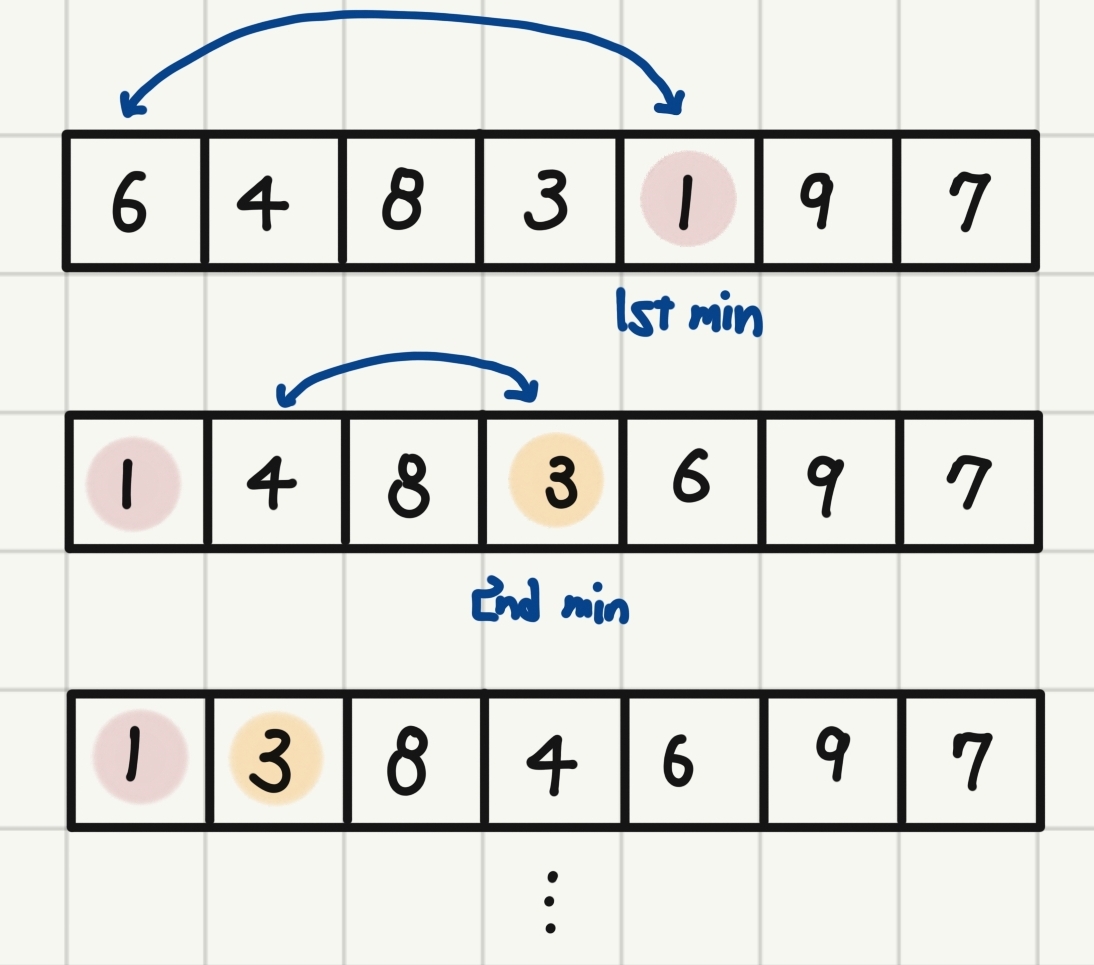
1. 전체에서 가장 작은 값인 '1'을 찾는다.
2. 첫 번째에 있는 값 '6'과 비교했을 때 '1'이 더 작기에, '1'을 맨 앞으로 보내고 나머지 값을 한 칸씩 뒤로 민다.
3. 두 번째로 작은 값인 '3'과 '1' 다음으로 앞에 있는 '4'를 비교했을 때 '3'이 더 작기에 '3'을 '1'과 '4' 사이에 배치하고 나머지 값을 한 칸씩 뒤로 민다.
4. 위 과정을 전체가 정렬될 때까지 반복한다.
def selection_sort(arr):
n = len(arr)
for i in range(n):
# 현재 인덱스를 최솟값이라고 가정
min_idx = i
# 끝까지 탐색하며 최소 인덱스 찾기
for j in range(i+1, n):
if arr[j] < arr[min_idx]:
min_idx = j
# 찾은 최솟값과 현재 위치 i 값 교환
arr[i], arr[min_idx] = arr[[min_idx], arr[i]
return arr9.1.3 삽입 정렬 (시간복잡도 )
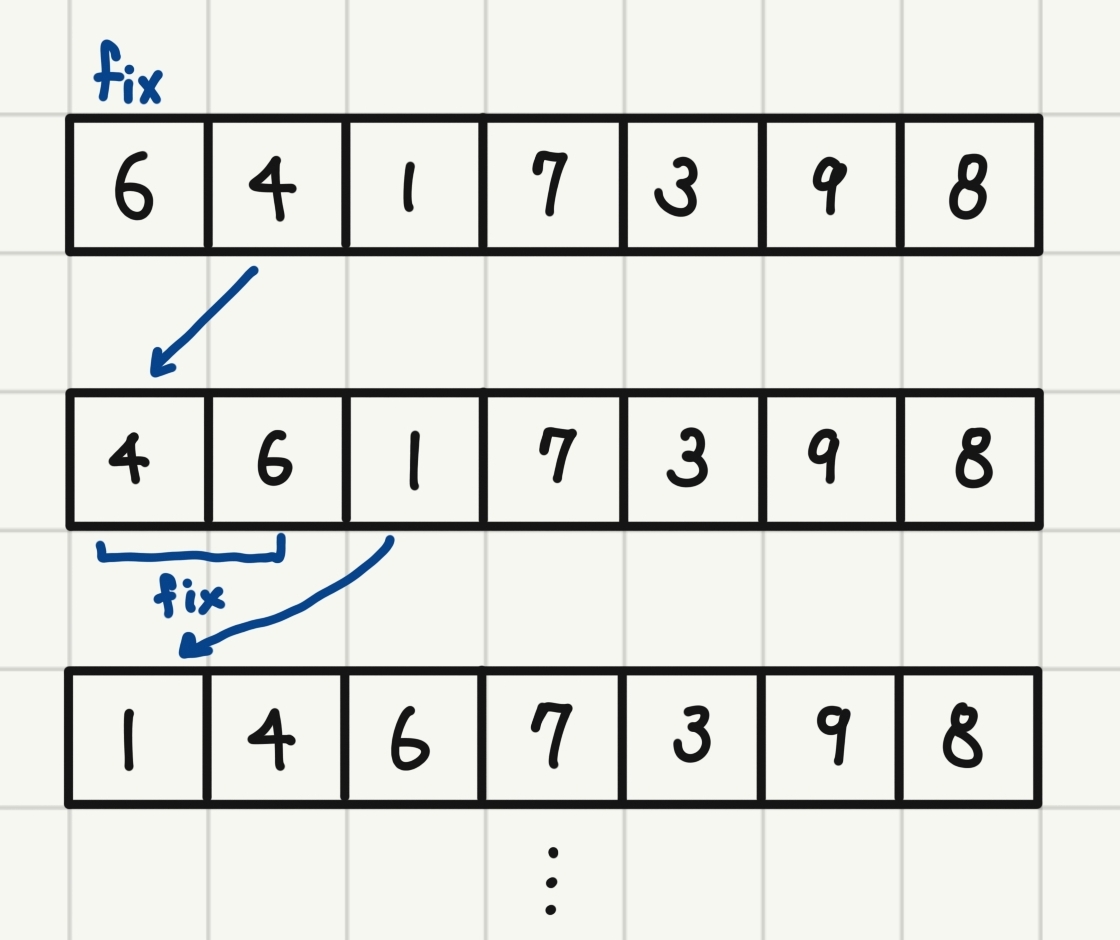
1. 맨 처음 값인 '6'을 고정시킨 뒤 그 다음 값인 '4'를 고정된 값과 비교하여 '6' 앞으로 삽입한다.
2. 이미 정렬한 '4'와 '6'을 고정시키고 그 다음 값인 '1'을 고정된 값들과 비교하여 '4' 앞으로 삽입한다.
3. 이미 정렬한 '1', '4', '6'을 고정시키고 그 다음 값인 '7'을 고정된 값들과 비교하여 기존 위치에 그대로 둔다.
4. 위 과정을 정렬이 끝날 때까지 반복한다.
9.1.4 병합 정렬 (시간복잡도 )
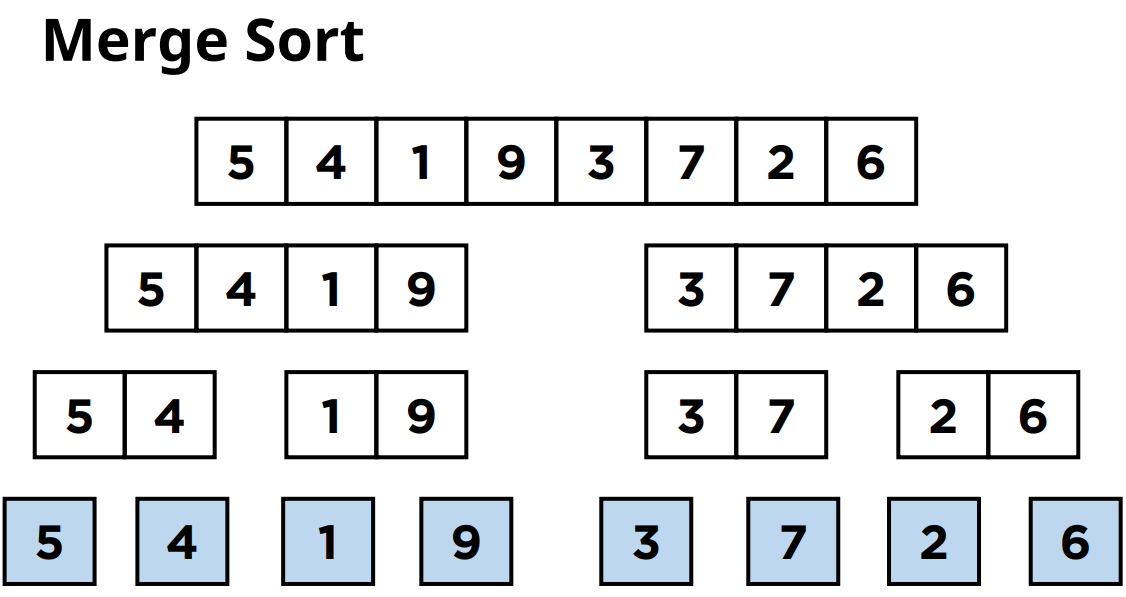
위 그림과 같이 리스트가 한 칸만 남을 때까지 쪼개는데, 쪼갤 때 큰 값을 오른쪽, 작은 값을 왼쪽으로 보낸다는 특징이 있다.
9.1.5 퀵 정렬 (시간복잡도 )
- 주의: 복잡함! 나도 처음에 이해하다 헷갈렸엉...ㅎㅎ 모르면 물어봐여
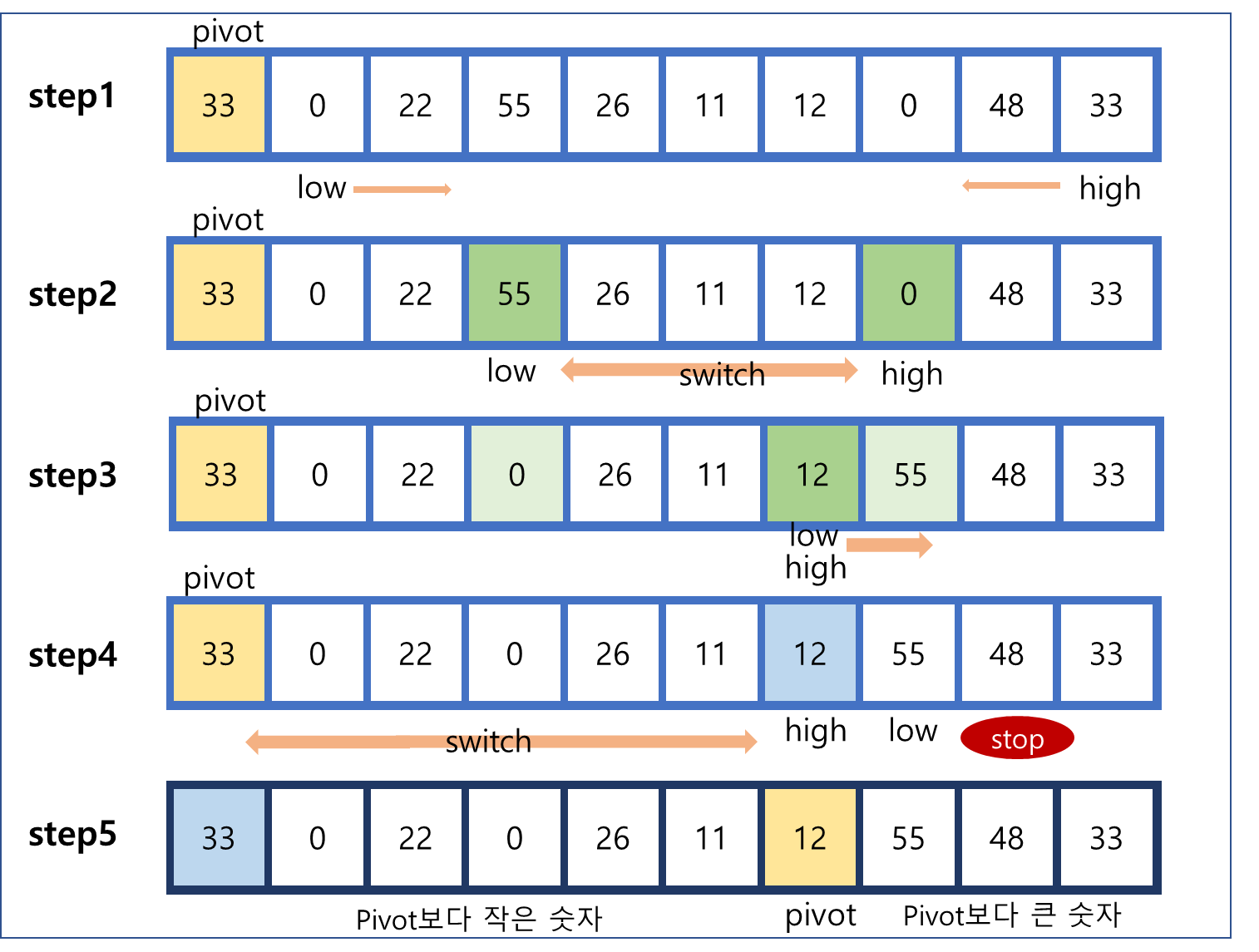
- 피벗(pivot, 기준값) 설정 -> 이 이미지에서는 맨 처음 값인 33을 피벗으로 설정했다.
- low는 왼쪽에서 오른쪽으로, high는 오른쪽에서 왼쪽으로 진행한다.
- low는 피벗보다 큰 값에서, high는 피벗보다 작은 값에서 멈춘다.
- low와 high에 해당하는 55와 0의 위치를 바꾼다.
- low와 high는 각각 55와 0의 위치에서 다시 이동한다.
- low는 12에서, high는 12에서 멈춘다.
- low와 high가 만나면 피벗과 high의 값을 교환한다.
https://velog.io/@kongji47/%EC%95%8C%EA%B3%A0%EB%A6%AC%EC%A6%98%EC%A0%95%EB%A0%AC-2.-%ED%80%B5-%EC%A0%95%EB%A0%ACQuick-Sort
이 글을 참고하긴 했는데 어려우면 지피티 또는 저에게 질문 주세여..ㅎㅎ
솔직히 나도 아직 헷갈리긴해
9.1.6 알고리즘 비교
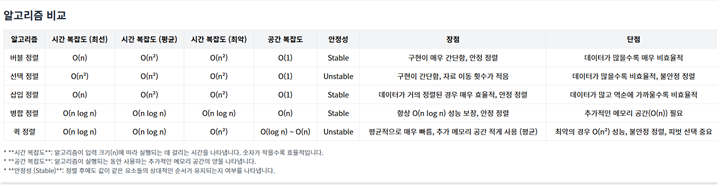
9.2 탐색
9.2.1 깊이 우선 탐색
목표 상태가 발견될 때까지 한쪽으로 가능한 모든 상태를 탐색. 더 탐색할 곳이 없으면 다시 이전 상태로 돌아와 다른 경로의 한쪽으로 계속 탐색, 스택 또는 재귀를 활용한다.
(대충 쭉 타고 내려갔다 다시 올라오는 느낌)
9.2.2 너비 우선 탐색
목표 상태가 발견될 때까지 현재 상태에서 가능한 모든 상태를 우선 탐색. 더 탐색할 곳이 없으면 다음 상태로 이동하여 다시 현재 상태에서 가능한 모든 상태를 계속 탐색. 큐를 사용한다.
(한층한층 가로 따라 내려가는 느낌)
9.2.3 언덕 등반 탐색
현 상태에서 이웃 노드 중 가장 좋은(높은 휴리스틱 값) 노드를 선택해 계속 이동하는 방식. 지역 최적해에 빠질 수 있음 (전역 최적해를 찾지 못할 수 있음) 백트래킹이 없음. 메모리 사용 적고 구현 간단.
9.2.4 최상 우선 탐색
휴리스틱 함수 h(n)에 따라 가장 좋은 것처럼 보이는 노드를 먼저 탐색. open list, 우선순위 큐를 사용해서 가장 작거나 큰 h(n) 값을 가진 노드를 선택. 탐색 속도 빠름. 휴리스틱이 부정확하면 잘못된 경로를 탐색할 수 있음. 최적해를 보장하지는 않음.
9.2.5 A* 알고리즘
실제 비용 g(n)과 예상 비용 h(n)의 합인 f(n) = g(n) + h(n)을 기준으로 노드 선택
g(n): 시작점에서 현재 노드까지의 실제 비용
h(n): 현재 노드에서 목표까지의 휴리스틱 추정 비용
휴리스틱이 admissible(과소평가)하면 최적해를 보장. 메모리 소모는 큼. 가장 널리 사용되는 경로 탐색 알고리즘 중 하나
ex. GPS 경로 탐색 (실제 거리 + 예상 거리 기반으로 가장 좋은 경로 탐색)
10. 연습문제 중 주목할만한 개념
10.1 한글파일 9쪽 문제2
import random #1
print('구구단을 외자! 구구단을 외자!')
for i in range(10):
a = random.randint(2,9) #2
b = random.randint(1,9)
answer = int(input(str(a) + 'x' + str(b) + '?')) #3
if answer == a*b :
continue #4
else:
print('땡! 틀렸습니다. 게임 종료!')
break #5#1. random이라는 라이브러리(명령어 저장소 갬성) 불러오는 것
#2. random 라이브러리 내 randint라는 함수, 2에서 9 사이 무작위 정수 추첨
- 함수끼리 연결해서 쓸 때는 '.' 찍어서 연결한다
#3. 위 코드에서 a,b는 '정수'인 상태. 이를 문자로 바꾸기 위해 문자형으로 변환하는 함수 str 사용 - 문자로 바꾸는 이유: a × b를 그대로 표시하기 위해서! 숫자라면 a×b가 아닌 계산한 값 ab가 나온다.
#4. continue: 반복문 계속 진행
#5. break: 반복문 멈춤 (탈출)
10.2 코랩 파이썬 수행연습
파이차트 표시
import matplotlib.pyplot as plt
ratio = [34, 32, 16, 18]
labels = ['Apple', 'Banana', 'Melon', 'Grapes']
plt.pie(ratio, labels=labels)
plt.show()