우리는 머신러닝을 통해서 예측이나 분류를 할 수 있다. 그런데 이 예측이나 분류가 얼마나 정확한지 자문하는 것이 중요하다. 분류 모델을 만들어놨는데, 그 예측이 얼마나 맞고 틀릴지 모르니까.
지도학습(supervised learning)에서는 다행히도 이미 레이블링 된(정답이 있는) 데이터가 있기 때문에 그걸 활용해서 알고리즘의 정확도를 테스트 할 수 있다.
머신러닝 모델의 효과성을 검증하기 위해 데이터를 나눌 때 보통 아래와 같이 세 개의 개념을 이해하면 된다.
- Training Set (학습 세트)
- Validation Set (검증 세트)
- Test Set (평가 세트)
이 중 검증 세트와 평가 세트는 사실 유사한 개념이다.
학습 세트(Training Set)와 검증 세트(Validation Set)
학습 세트(Training Set)는 뭐 말 그대로 알고리즘이 학습할 데이터**다.
이 학습 데이터 세트를 사용하여 모델을 학습시키고 나면 이후에는 검증 세트(Validation Set)을 통해 모델의 예측/분류 정확도를 계산할 수 있다. 사실 모든 검증 세트에 대한 실제 레이블, 즉 정답을 알고 있지만 그렇지 않은 척 하는 셈이다. 그래서 새로운 데이터인 것처럼 분류/예측 모델에 입력해준다. 실제로 학습 시킬 때 이 데이터들을 배제했기 때문에 가능하다. 예측/분류된 값을 받아서 실제로 갖고 있던 답과 비교하기만 하면 결국 정확도(Accuracy)를 알 수 있는 거다.
물론 여기서 말하는 정확도(Accuracy)가 만능의 지표는 아니다. 머신러닝 알고리즘의 효과를 판단할 때 오히려 정밀도(precision)과 재현율(recall), 그리고 정확률과 정밀도의 조화평균인 F1 점수**를 확인하는 등의 방법도 있다.
어떻게 데이터 세트를 나눌 것인가 (How to Split)
학습세트 vs 검증세트를 어떤 비율로 분할할지 판단하기가 쉽지 않다. 학습세트가 너무 작으면 알고리즘이 효과적으로 학습하기에 충분치 않을 수 있다. 반면, 검증 데이터가 너무 작으면 이를 통해 계산한 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수가 서로 차이가 많이 나서 신뢰하기 어려울 수 있다.
일반적으로 전체 데이터 중 80%를 학습으로, 20%를 검증으로 사용하는 것이 좋다고 한다.
나누는 방법은 scikit-learn에서 친절하게 제공한다.
from sklearn.model_selection import train_test_split
training_data, validation_data, training_labels, validation_labels = train_test_split(x, y, train_size = 0.8, test_size = 0.2)교차 검증 (N-Fold Cross-Validation)
데이터가 충분치 않을 경우 80/20으로 나누면 여전히 많은 양의 분산이 발생한다. 이에 대한 한 가지 해결책은 N-Fold 교차 검증을 수행하는 것, 즉 전체 프로세스를 N번 수행하고 모든 수행에서 나온 정확도의 평균을 구하는 방법이다.
예를 들어, 10번 교차 검증을 한다고 하면 아래와 같은 그림으로 표현할 수 있다.
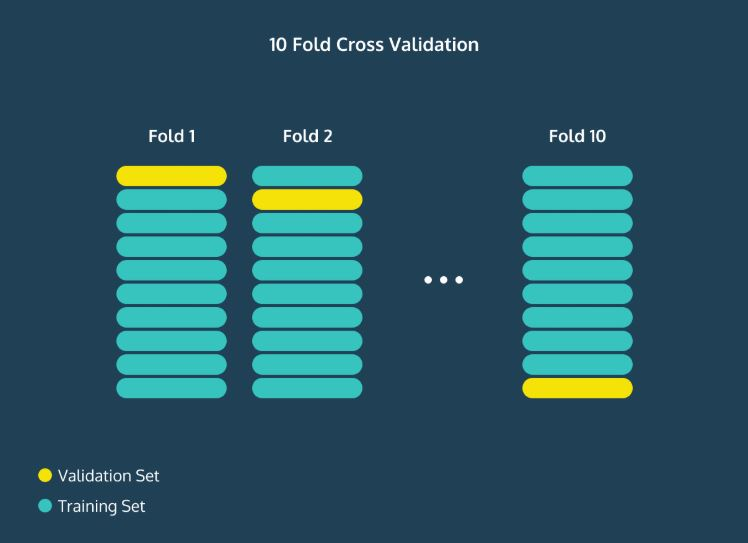
당연히 이렇게 구한 정확도의 평균 값이 아무래도 모델의 평균 성능을 더 잘 나타낸다고 볼 수 있다.
그리고 이걸 일일이 하기 귀찮으니 scikit-learn에서는 아예 이런 기능을 제공하고 있기도 하다.
from sklearn_model_selection import KFold그러니 적극적으로 사용하자.
모델 성능 개선 및 평가 세트 (Test Set)
모델의 파라미터를 세부적으로 튜닝하면 그 모델의 성능을 향상시킬 수 있다. 예를 들어, K-최근접 이웃(K-Nearest Neighbors) 알고리즘에서는 K를 늘리거나 줄일 때 정확도가 어떻게 달라지는지 확인할 수 있다.
만약 모델의 성능이 어느정도 만족스럽다면 평가 세트(Test Set)를 넣어볼 수 있다. 이건 실제 데이터다. 어떤 예측/분류가 일어날지 궁금한 값을 만들어 넣어줄 수도 있고, 새롭게 얻은 데이터일 수도 있으며, 애초에 모델을 생성하기 전에 일부러 따로 떼어놓은 데이터일 수도 있다. 어떻게 보면 검증 세트(Validation Set)와 비슷하지만, 모델을 구축하거나 튜닝할 때 포함된 적 없다는 점에서 차이가 있다.
아무튼 이 평가 세트(Test Set)에서 모델이 예측/분류해준 값과 실제 값을 비교해서 정확도(Accuracy), 정밀도(Precision), 재현율(Recall), F1 점수를 계산해봄으로써 알고리즘이 현실 세계에서 얼마나 잘 수행되는지 이해할 수 있게 되는 거다.
