머신러닝
1.지도학습이란?

분류와 회귀로 구분됨
2.비지도 학습이란?
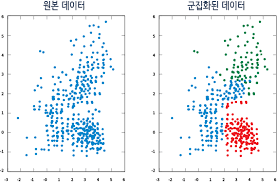
비지도 학습(Unsupervised Learning) 정답을 따로 알려주지 않고(label이 없다), 비슷한 데이터들을 군집화 하는 것. 일종의 그룹핑 알고리즘. 라벨링 되어있지 않은 데이터로부터 패턴이나 형태를 찾아야 하기 때문에 지도학습보다는 조금 더 난이도가 있다. 실제로 지도 학습에서 적절한 피처를 찾아내기 위한 전처리 방법으로 비지도 학습을...
3.강화학습이란?

강화학습(Reinforcement Learning)
4.분류(Clasification)란?
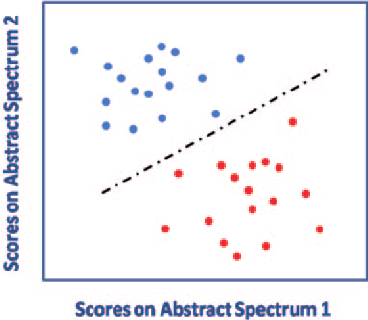
분류
5.분석 시 회귀와 분류 구별하는 법
지도학습의 종류 1. 회귀 종속변수가 양적 데이터일 때 사용 예시1 예시2 란?
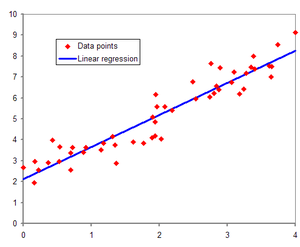
회귀 개념
7.군집화 알고리즘 종류
.png)
군집화 알고리즘 종류
8.선형 회귀 모델 (Linear regression model)
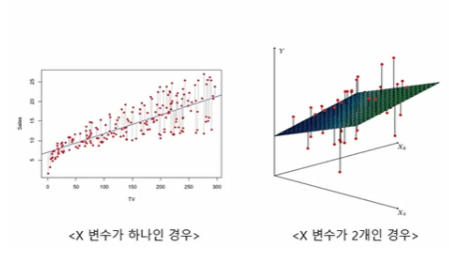
선형회귀모델
9.로지스틱 회귀 (Logistic Regression)
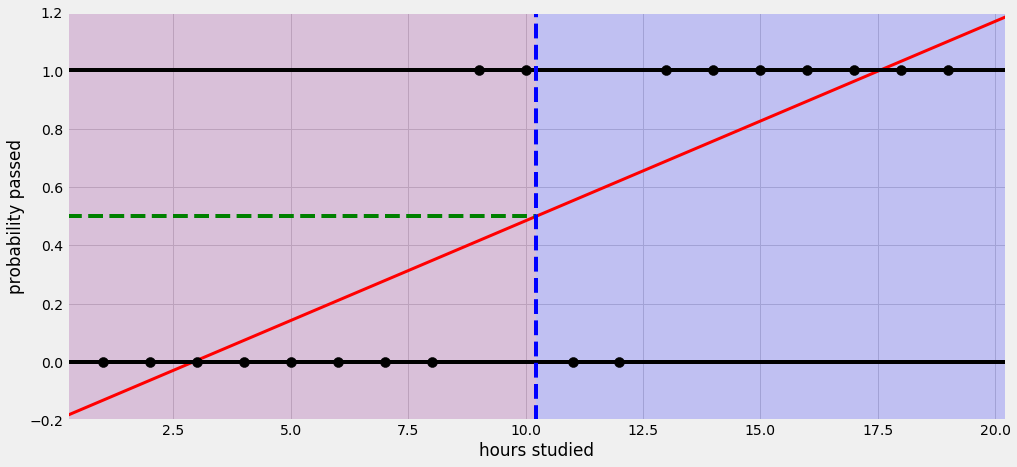
로지스틱 회귀
10.다중선형회귀(Multiple Linear Regression) 예제
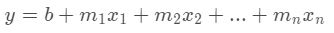
다중선형회귀 예제
11.선형 회귀 분석(Linear Regression) 예제

선형 회귀 분석 예제
12.정규화(Normalization)
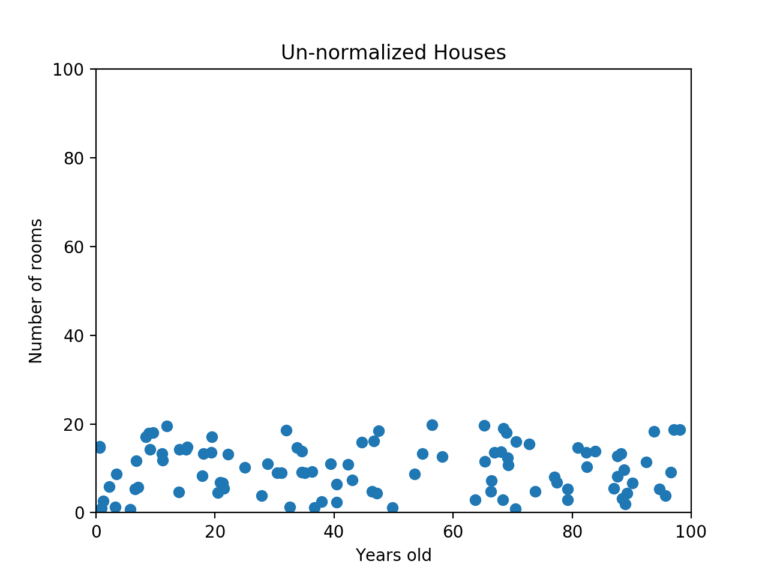
정규화
13.로지스틱회귀(Logistic Regression) 예제

로지스틱회귀
14.KNN (K-Nearest Neighbor) 개념
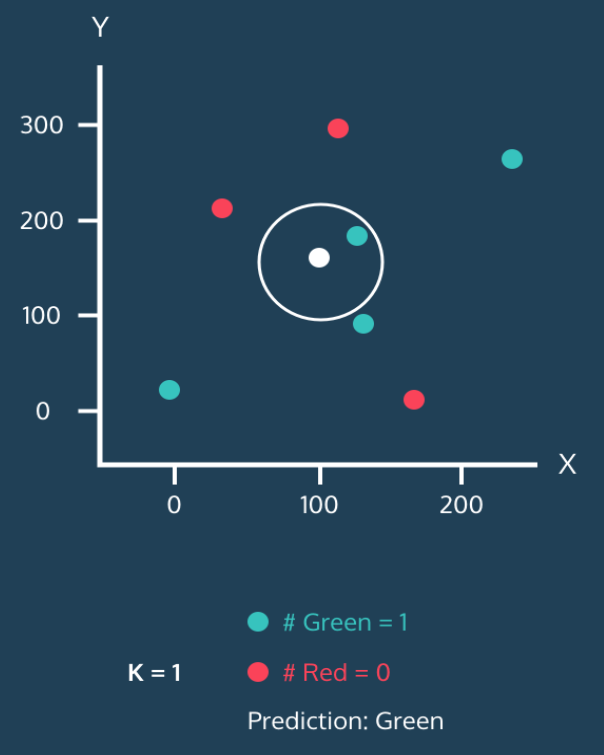
KNN
15.KNN(K-Nearest Neighbor) 분류 예제

KNN 분류
16.KNN(K-Nearest Neighbor) 회귀 예제
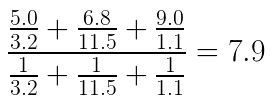
KNN 회귀
17.머신러닝 overfitting 개념과 해결 방법 (feat. 기울어진 운동장)
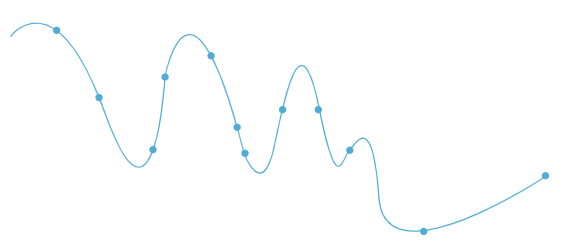
) 머신러닝은 (쉽게 이야기하자면) 대량의 데이터를 알고리즘에 넣어서 일종의 규칙을 생성하고, 그 규칙에 따라 입력값을 분류하도록 하는 거다. 그래서 이 알고리즘에 제공하는 학습 데이터가 매우 중요하다. 학습 데이터의 모든 값들을 하나하나 살펴보면서 규칙을 생성하기 때문이다. Overfitting(과적합)이란 overfitting은 모델의 파라미터들을...
18.머신러닝에서 학습세트, 평가세트를 나누는 이유와 방법
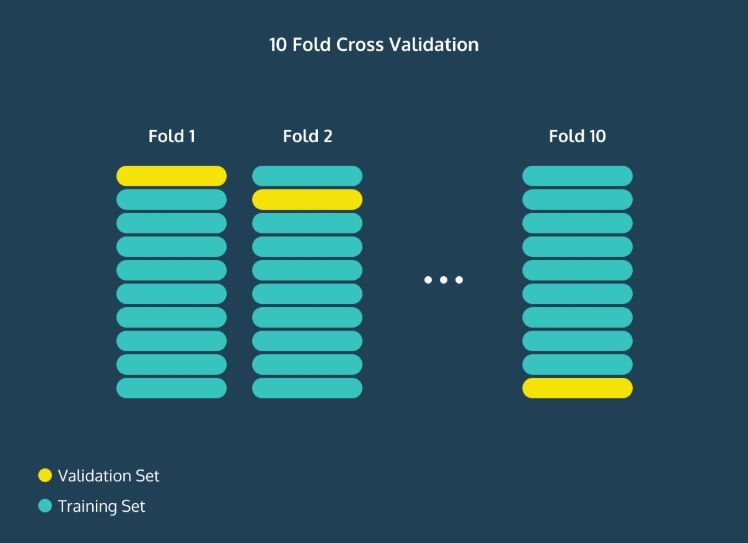
우리는 머신러닝을 통해서 예측이나 분류를 할 수 있다. 그런데 이 예측이나 분류가 얼마나 정확한지 자문하는 것이 중요하다. 분류 모델을 만들어놨는데, 그 예측이 얼마나 맞고 틀릴지 모르니까. 지도학습(supervised learning)에서는 다행히도 이미 레이블링 된(정답이 있는) 데이터가 있기 때문에 그걸 활용해서 알고리즘의 정확도를
19.두 점 사이의 거리 공식
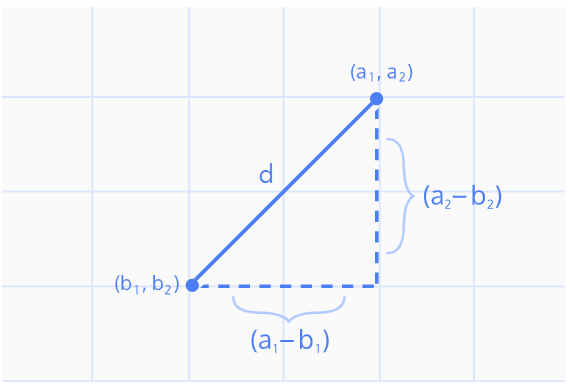
본 포스팅에서는 두 점 사이의 거리를 구하는 여러가지 방법을 알아본다. 그런데 거리(distance)를 왜 구해야 할까? 거리는 일종의 유사도(similarity) 개념이기 때문이다. 거리가 가까울수록 그 특성(feature)들이 비슷하다는 뜻이니까. 그래서 머신러닝 알고리즘에서도 매우 널리 사용된다. 예를 들면 K-최근접 이웃(K-Nearest Ne...
20.서포트 벡터 머신(Support Vector Macine, SVM)
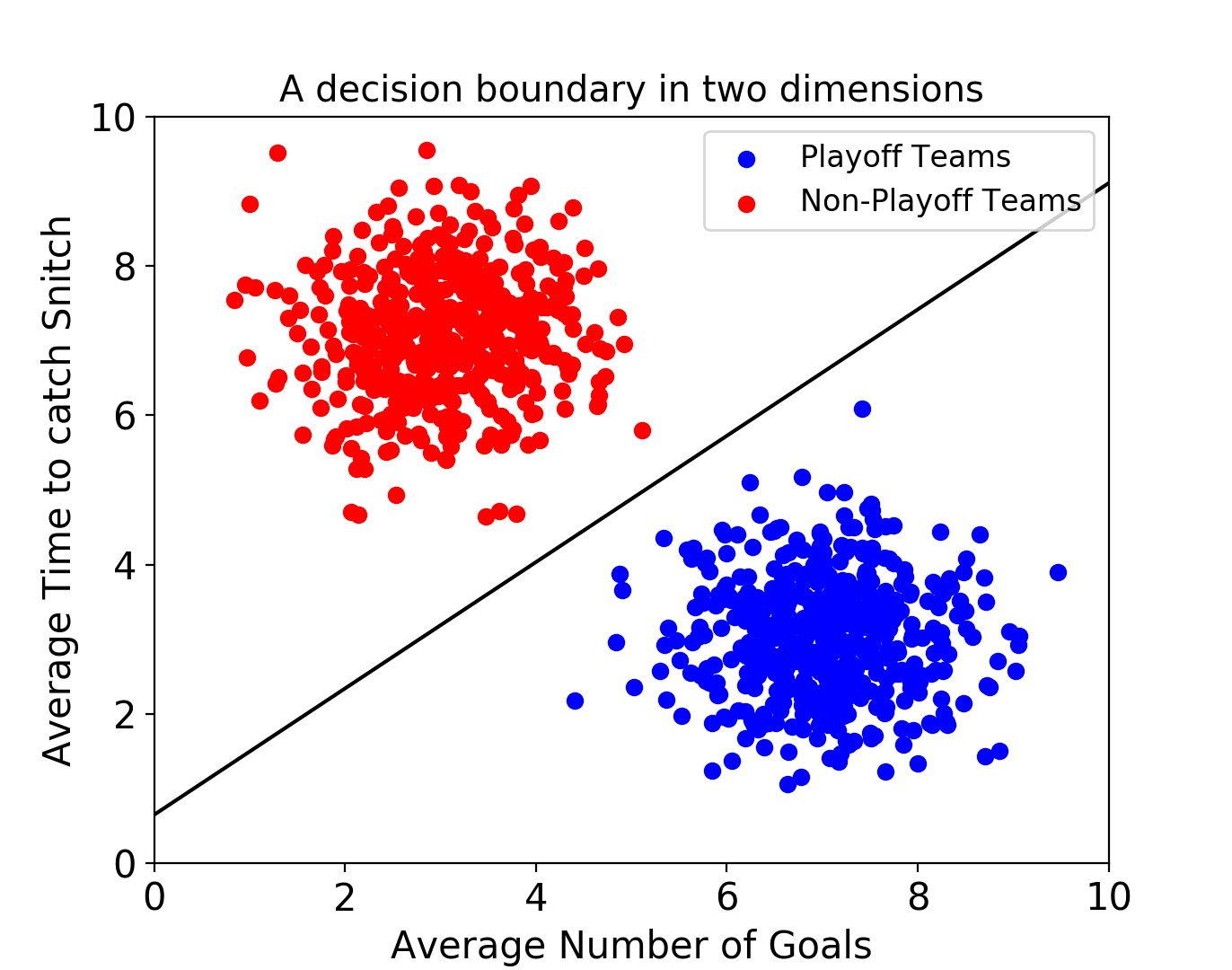
서포트 벡터 머신
21.의사결정나무(Decision Tree)
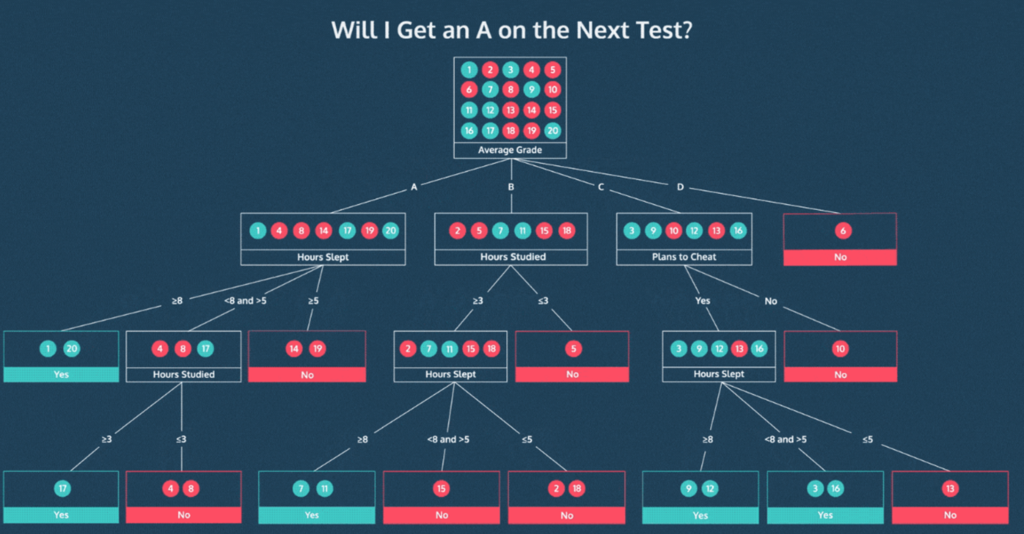
) 의사결정나무(Decision Tree) 각 데이터들이 가진 속성들로부터 패턴을 찾아내서 분류 과제를 수행할 수 있도록 하는 지도학습 머신러닝 모델이다. 일단 이 모델의 개념만 최대한 쉽게 설명해본다. 목차는 아래와 같다. 의사결정나무란 무엇인가 지니 불순도 (Gini Impurity) 정보 획득량 (Information Gain) scikit-...
22.베이즈 정리 (Bayes' Theorem)
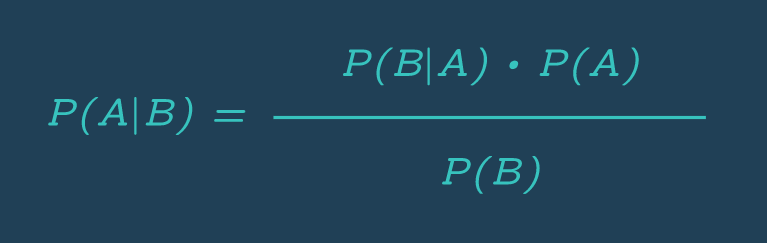
) 머신러닝 알고리즘 나이브 베이즈 (Naive Bayes)를 사용하기 위해서는 일단 베이즈 정리(Bayes' Theorem)라는 걸 먼저 이해해야 한다. 본 포스팅에서는 베이즈 정리의 개념만 최대한 쉽고 단순하게 설명해본다. 베이즈 정리(Bayes' Theorem)는 새로운 사건의 확률을 계산하기 전에 이미 일어난 사건을 고려하는 것을 전제로 하는 베...
23.나이브 베이즈(Naive Bayes)를 확용한 문서 분류 쉽게 이해하기
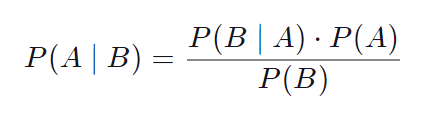
나이브 베이즈
24.나이브 베이즈(Naive Bayes)를 활용한 문서 분류 예제

나이브 베이즈 분류 예제
25.랜덤 포레스트(Random Forest)

랜덤 포레스트
26.K-Means 클러스터링 쉽게 이해하기
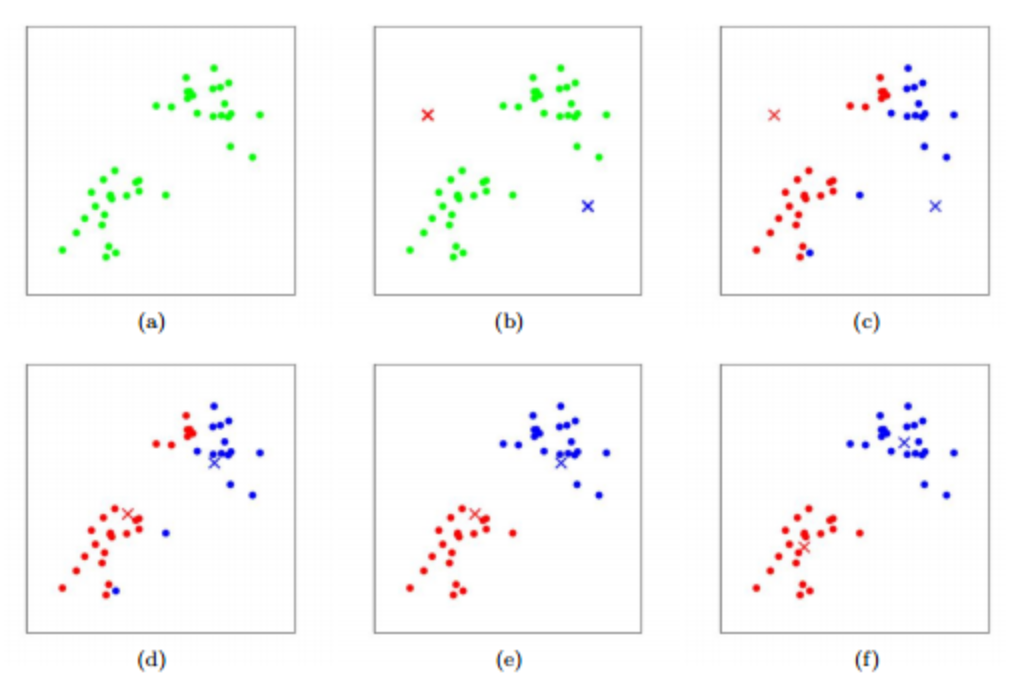
본 포스팅에서는 데이터 클러스터링(군집화)로 널리 사용되는 비지도학습 알고리즘 K-Means 클러스터링에 대해 최대한 쉽게 설명해보고자 한다. 파이썬 라이브러리 scikit-learn 사용법도 간략히 소개한다. 클러스터링, 군집화란 무엇인가 만약 우리가 다루는 데이터에 '레이블'이 붙어 있다면 지도학습, 즉 미리 가지고 있는 데이터와 레이블을 기반으...
27.K-Means++ 클러스터링 쉽게 이해하기
이전 포스팅에서 K-Means 클러스터링의 개념이나 원리를 다뤘다. K-Means 클러스터링 알고리즘은 소개된지 거의 반세기가 지났지만, 여전히 머신러닝에 가장 널리 사용되는 클러스터링 알고리즘 중 하나이다. 그러나 K-Means 알고리즘의 가장 큰 단점은 **처음에
28.머신러닝 분류 모델의 성능 평가 지표 (Accuracy, Recall, Precision, F1)
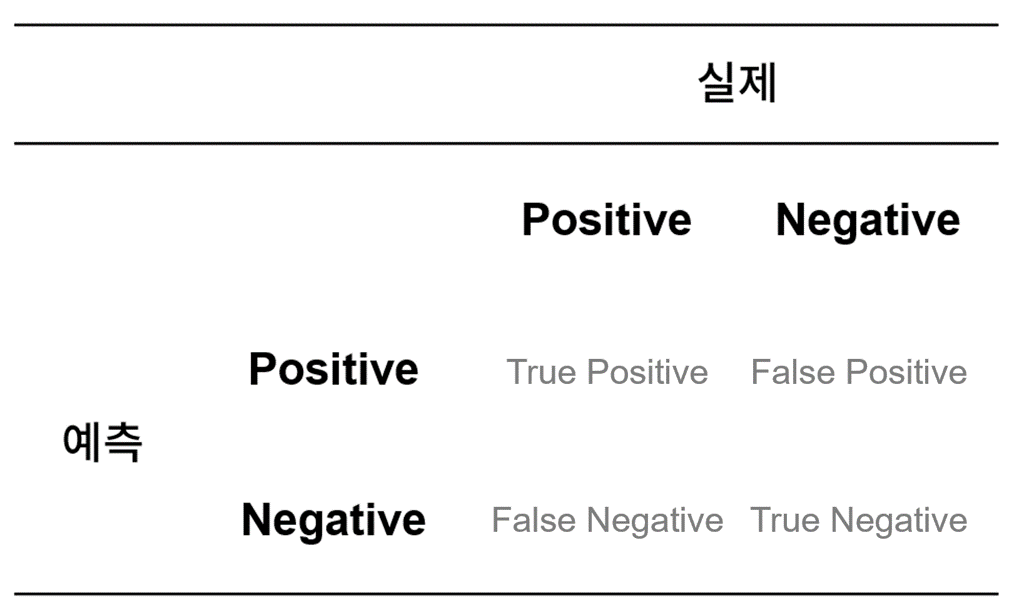
) 분류를 수행할 수 있는 기계 학습 알고리즘을 만들고 나면, 그 분류기의 예측력을 검증/평가 해봐야 한다. 모델의 성능을 평가하려면 모델을 생성하기 전부터 애초에 데이터를 학습 세트와 평가 세트로 분리해서, 학습 세트로 모델을 만들고 평가 세트로 그 모델의 정확도를 확인하는 절차를 거친다. (자세한 내용은 [이 포스팅](https://velog.io/...
29.머신러닝 회귀 모델의 성능 평가 지표 (MAE, MSE, RMSE, R-squred)
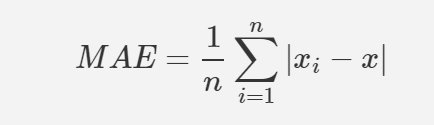
) 회귀모델을 평가하는 평가지표 회귀모델은 그 모델이 잘 학습되어졌는지 확인하기 위한 회귀모델의 평가지표들이 4가지 있다. 이를 하나씩 살펴보자. MAE(Mean Absolute Error) 모델의 예측값과 실제값의 차이의
30.문자 카테고리형 데이터 처리 (Label Encoding, One-Hot Encoding)
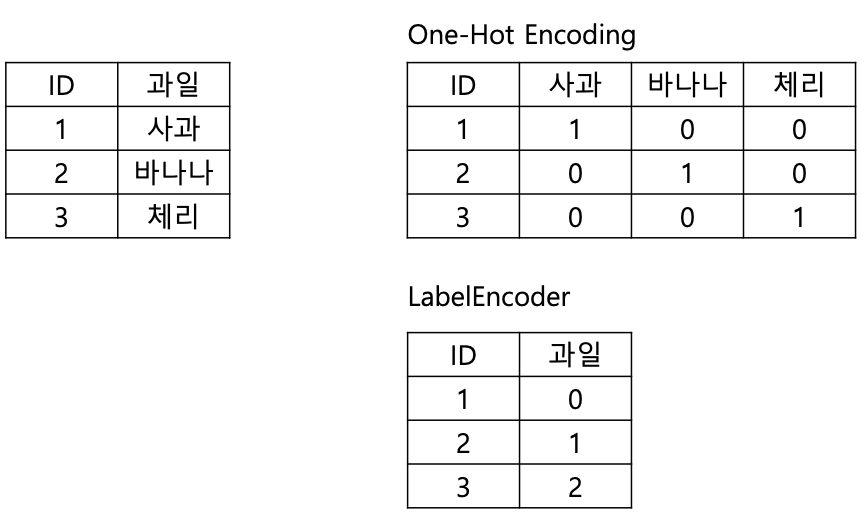
) 머신러닝 알고리즘은 문자열 데이터 속성을 입력받지 않으며 모든 데이터는 숫자형으로 표현되어야 한다.따라서 문자형 카테고리형 속성은 모두 숫자 값으로 변환/인코딩 되어야 한다. scikit-learn을 사용한 변환 방식에는 대표적으로 2가지가 있다. 레이블 인코딩 (Label Encoding) 원-핫 인코딩(One-Hot Encoding) 이 두...
31.앙상블 (Ensemble) 이란
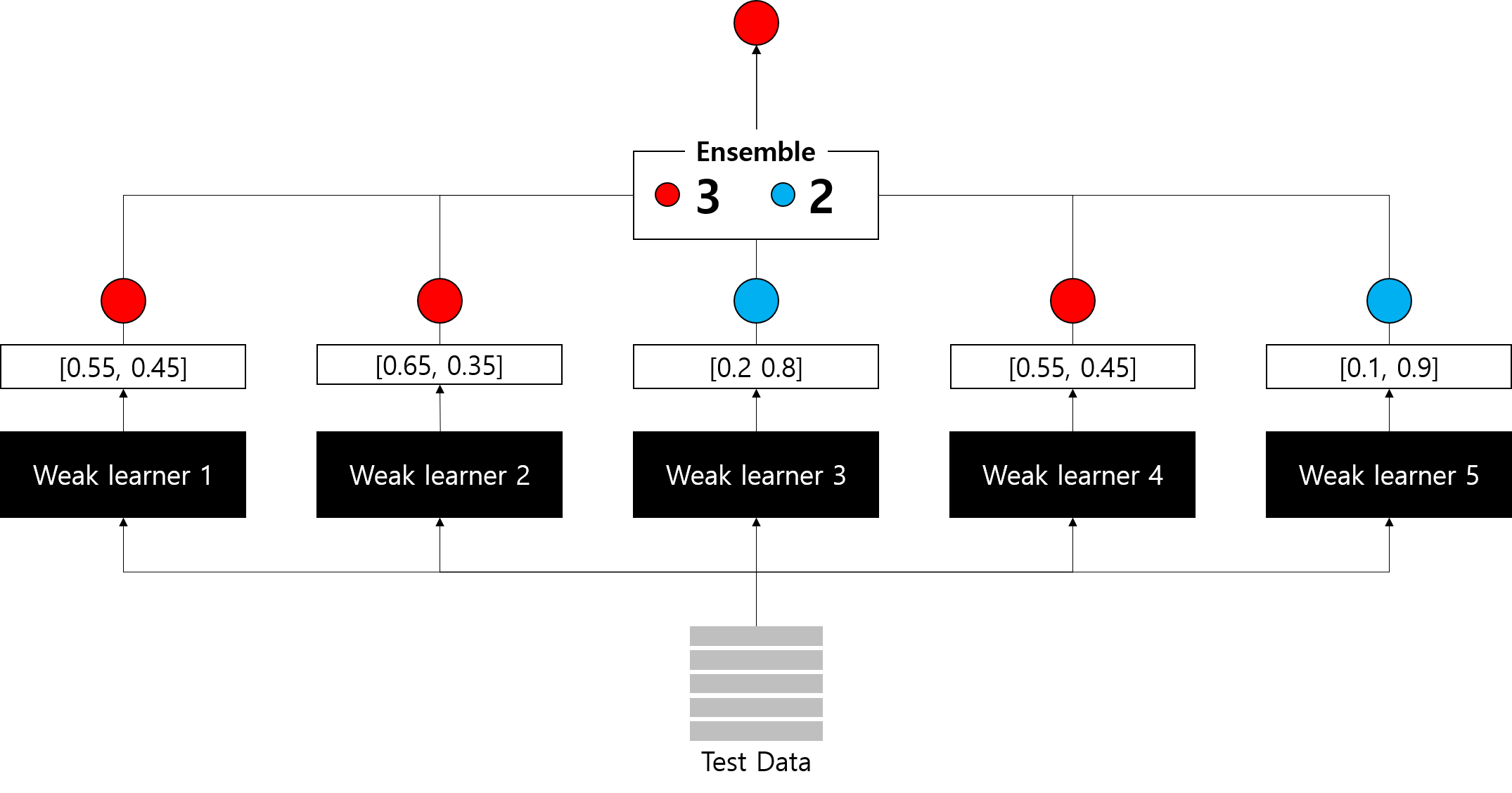
앙상블
32.AdaBoost란
AdaBoost
33.Gradient Boost (GBM)란
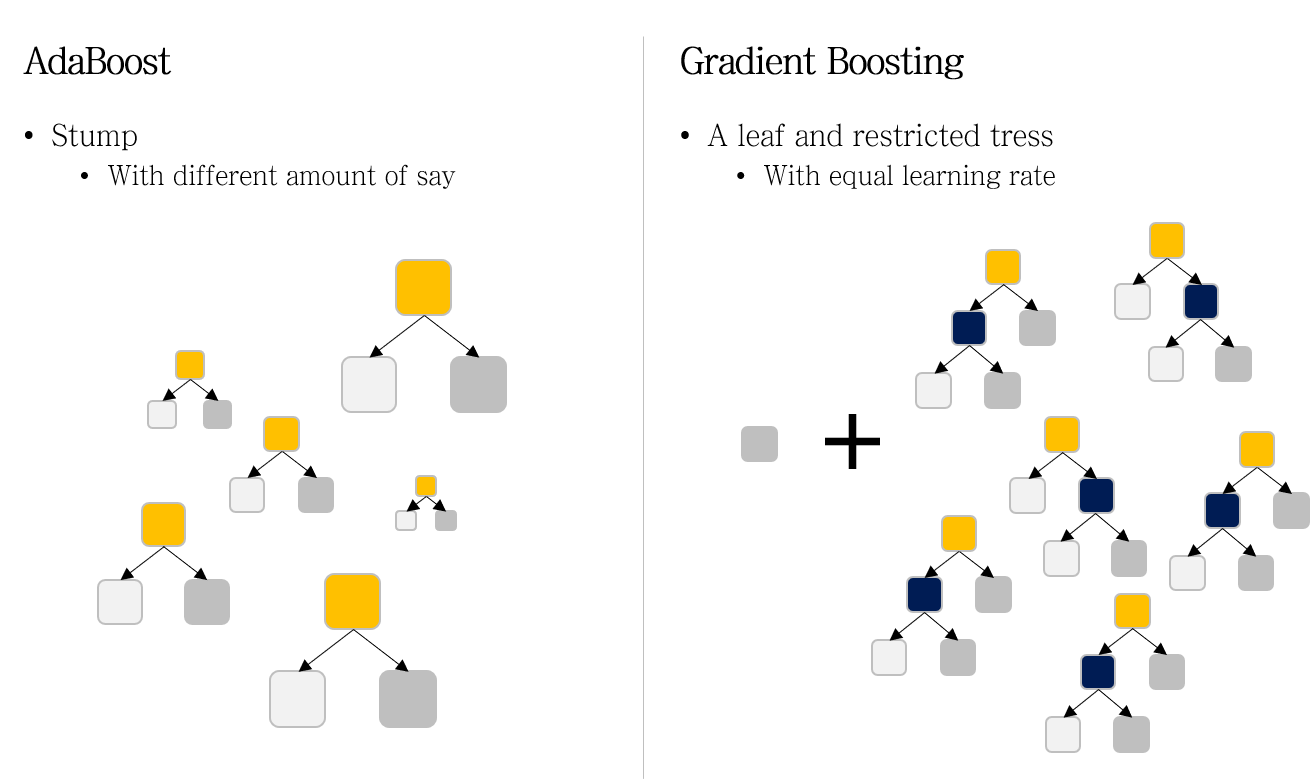
GBM