앙상블 방법론에는 부스팅과 배깅이 있다. (앙상블 (Ensemble) 이란)
배깅의 대표적인 모델은 랜덤 포레스트이고, 부스팅의 대표적인 모델은 AdaBoost, Gradient Boost 등이 있다.
이번 포스팅에서는 Gradient Boost에 대해 알아보자.
Gradient Boost의 변형 모델로는 XGBoost, LightGBM, CatBoost가 있다. 참고로, 이 모델들은 캐글의 top ranker들이 많이 사용한다고 한다.
Gradient Boost는 회귀와 분류에 모두 사용할 수 있는 모델이다. 이번 포스팅은 회귀를 기준으로 설명했다. 분류도 일부 계산 절차만 다를 뿐 프로세스는 이와 유사하다.
Gradient Boost를 이해하기 위해 사전지식으로 AdaBoost
에 대해 알고 있으면 좋다
AdaBoost와 Gradient Boost의 차이
- Weak Learner : Stump vs A leaf & Restricted trees
- Predicted value : Output vs Pseudo-residual
- Model Weight : Different model weights (Amount of Say) vs Equal model weight (learning rate)
1. Weak Learner
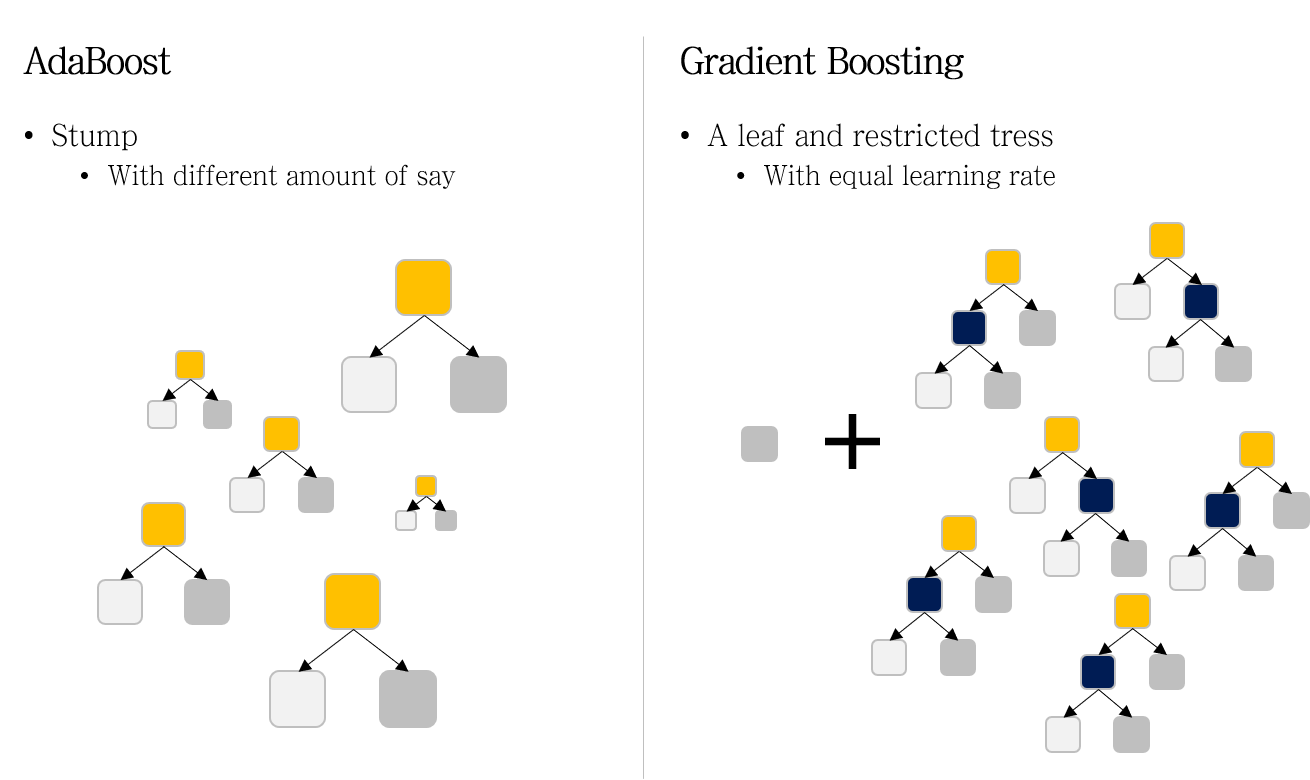
AdaBoost에서는 weak learner로 stump (한 개 노드와 두 개의 가지를 갖는 매우 작은 decision tree) 를 사용한다.
반면 Gradient Boosting에서는 restricted tree를 사용한다. restricted tree란, maximum number of leaves로 성장에 제한을 둔 decision tree다.
또한 Gradient Boosting의 첫 번째 weak learner는 모든 샘플의 output 평균을 값으로 갖는 하나의 leaf다.
2. Predicted value
각 모델이 예측하는 정보가 다르다.
AdaBoost에서는 각 stump들이 모두 실제 output 값을 예측하는 모델이었기 때문에, 이 값을 평균내거나 가중치를 곱한 평균을 통해 실제 값에 가까운 예측값을 만들어냈다.
반면 Gradient Boosting은 각 restricted tree들이 예측하는 값이 실제 output과 이전 모델의 예측치 사이의 오차 (pseudo-residual)다. 최종 예측 시에는 각 모델의 오차를 scaling 후 합하는 과정을 통해 실제 값에 가까운 예측값을 만들어낸다.
Pseudo-residual에서 Pseudo라는 단어가 붙은 이유는 linear regression 에서의 residaul과 구별하기 위해서입니다. Gradient Boosting에서 어떤 Loss function을 사용하느냐에 따라 residual과 동일할 수도, 비슷할 수도 있기에 이런 이름을 붙였다고 합니다.
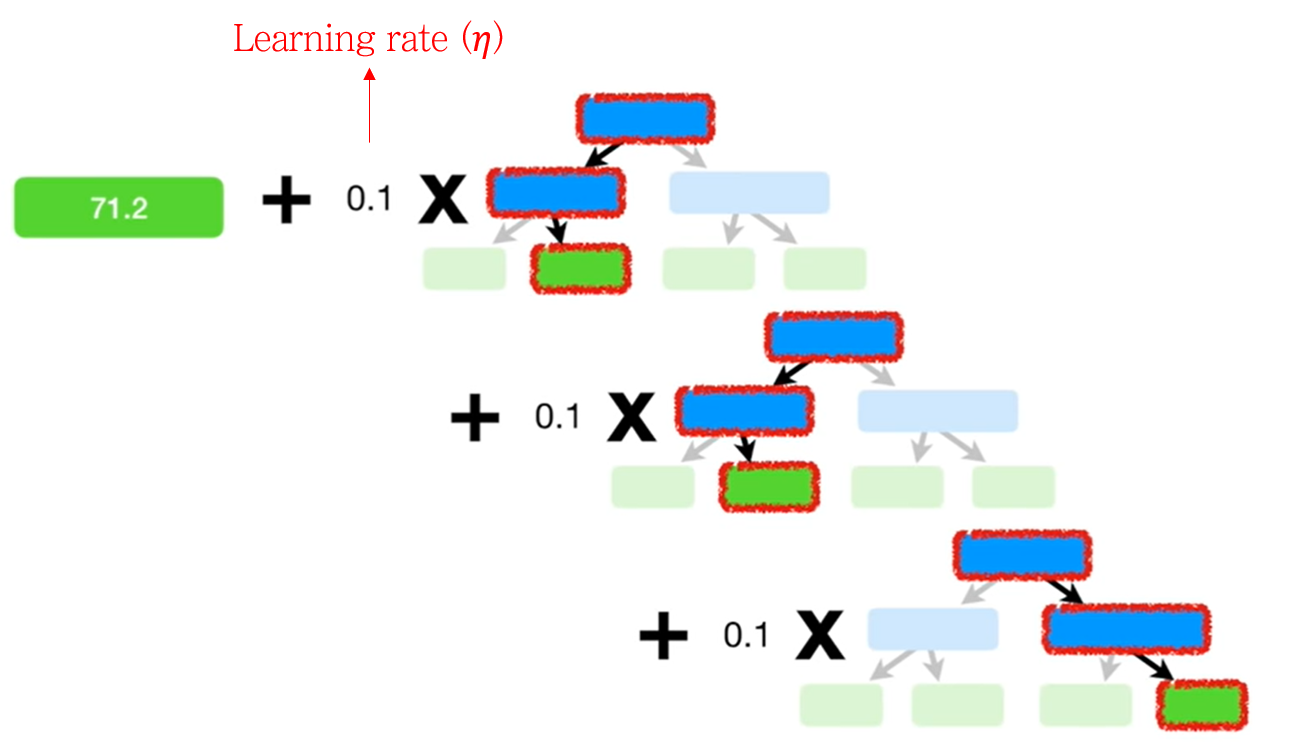
3. Model weight
각 모델에 대해 가중치를 주는 방식이 다르다.
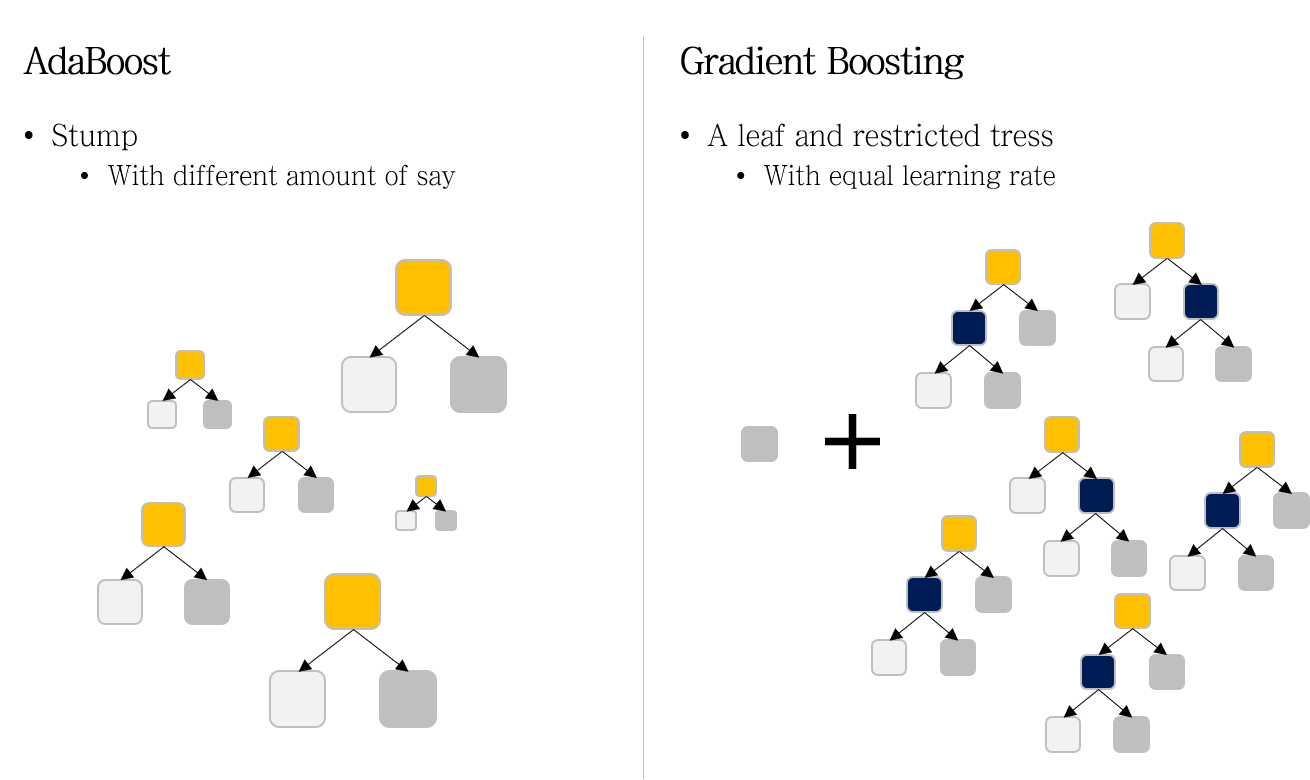
위 그림을 보면, AdaBoost에서는 각 모델의 크기가 다른 반면, Gradient Boosting에서는 크기가 동일한 것을 알 수 있다.
왼쪽의 있는 네모는 첫번째 모델 (a leaf)의 값을 의미한다.
회귀와 분류 구별
Create decision trees to predict residual (observed value – predicted value) of __, with limitation of maximum number of leaves.
여기에 들어갈 __에 따라 GBM을 회귀로 쓸지 분류로 쓸지가 나뉜다.
-
회귀 : Output 그 자체
-
분류 : Output class의 probability
