본 포스팅에서는 파이썬 라이브러리 scikit-learn을 통해 KNN 알고리즘을 사용한 분류를 직접 수행하는 예제를 소개한다. 누구나 따라할 수 있는 수준으로 작성했다.
KNN 알고리즘의 기초적인 내용은 간단히 짚어봤으니, 반드시 그걸 이해한 상태에서 코드를 작성해보자.
sklearn KNeighboresClassifier 사용법
실제 데이터 돌려보기 전에 사용법부터 익히고 가자.
일단 그 유명한 파이썬 머신러닝 라이브러리 싸이킷런을 불러오자.

이제 KNeighborsClassifier 모델을 생성해야 하는데, 이 때 n_neighbors로 k를 정해줘야 한다. (그리고 x 데이터를 분류할 때 k개의 이웃 중 거리가 가까운 이웃의 영향을 더 많이 받도록 가중치를 설정하려면 weight = 'distance'를 지정해줄 수 있는데 여기서는 일단 생략한다)

그 다음 데이터를 .fit()시켜준다. x 데이터는 여러 개의 차원으로 이루어진 배열(점들의 집합)이 될 거고, y 데이터는 레이블(각 점들의 분류 결과)가 된다. 이 예제에서는 0 아니면 1로 분류되는 거다.

끝난 거다. 이제 만약 새로운 값들을 분류하고 싶다면 .predict()를 사용하면 된다. 이렇게.

sklearn KNeighborsClassifier 실전 예제
데이터와 레이블 불러오기
일단 데이터가 마땅치 않으니 본 예제에서는 sklearn에서 제공하는 예시 데이터 중 유방암 데이터를 사용해보겠다. 일단 이렇게 불러오자.

데이터 확인하기
그리고 이걸 평소에 익숙하게 다루는 pandas의 데이터 프레임의 형태로 바꿔서 확인해보자.
.data를 찍어주면 데이터, .target을 찍어주면 라벨을 돌려준다.

잘 불러왔는지 확인해보자.
일단 df_labels는 확인해보니 0과 1로만 표시되어 있었다.

그리고 그 0과 1이 각각 어떤 걸 의미하는지 이렇게 .target_names을 찍어보면 알 수 있다.

사전 찾아보니 각각 음성(malignant), 양성(benign)이라는 뜻이라고 한다.
그런데 df_data에는 좀 문제가 있었다.

항목 이름(컬럼) 같은 것도 없고, 그냥 30개 항목에 대한 값만 쭉 들어 있다. 그런데 값이 어떤 건 엄청 큰 거 같고, 어떤 건 1이 채 안되는 것 같다.
각 항목 별로 최대/최소값을 비롯한 기초 통계량을 확인하기 위해 .describe()를 찍어보았다.
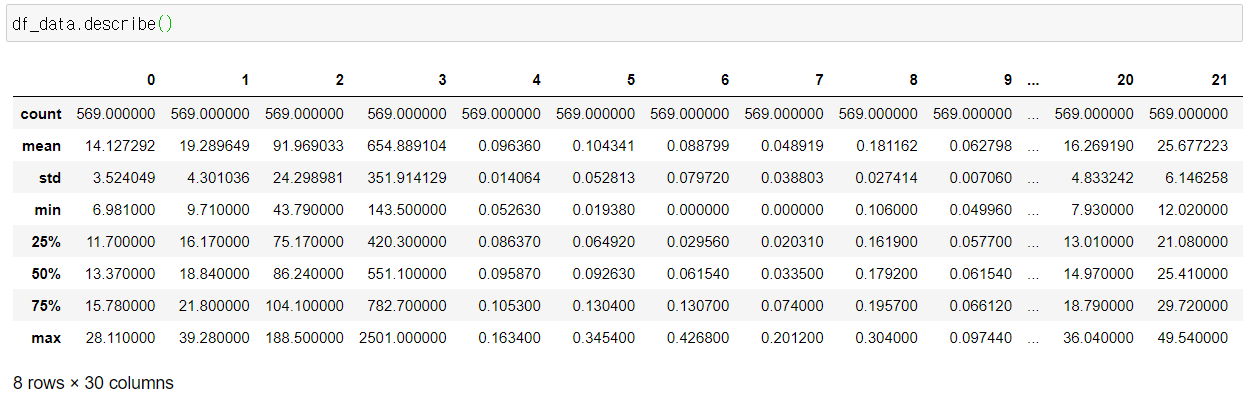
역시 뭔가 이상하다. 3번 컬럼은 최대 값이 2501이나 되는데, 9번 컬럼은 0.097이 최대값이다. 최소값도 항목에 따라 편차가 크다.
항목마다 스케일이 너무나 다른데 그걸 무시한채 동일한 정도로 학습에 반영하면 안될 거 같다. 정규화를 해줘야겠다
정규화(Normalization)
만약 정규화에 대해 자세히 알고 싶다면 이 포스트를 참고하자.
본 예제에서는 최소-최대 정규화 함수를 작성한 후 df_data에 적용해봤다.
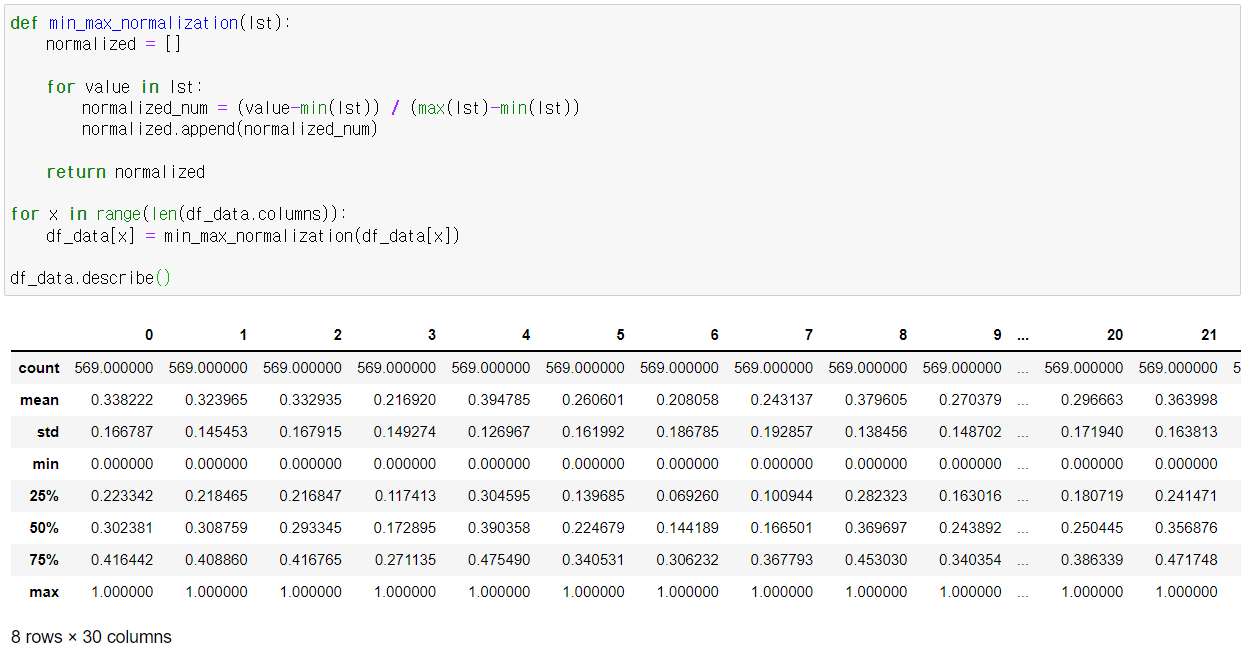
모든 항목이 최소값은 0, 최대값은 1로 변환된 걸 확인할 수 있다.
데이터 세트 분리하기 (Training & Validation)
가지고 있는 데이터를 모두 사용해서 분류 모델을 만들 수도 있지만, 우리는 실제로 생성한 분류 모델의 성능을 테스트 해봐야 하니까 학습(training) 세트와 검증(validation) 세트를 분리해보자. 모든 데이터에는 분류된 레이블(target)이 있으니, 검증 데이터를 예측 모델에 넣어서 실제 그 레이블(정답)을 잘 맞추는지 보기 위함이다.
데이터 세트 분리는 sklearn에서 train_test_split을 통해 손쉽게 할 수 있다.
-
데이터 세트를 나누는 비율을 지정할 수도 있는데 기본 값은 0.75:0.25, 즉 3:1이다. 3으로 학습해서 1로 시험보는 거다. 만약 비율을 바꾸고 싶다면
test_size의 값만 0에서 1사이로 넣어주면 된다.test_size = 0.2이렇게. -
random_state라는 파라미터도 있다. 데이터 세트를 나눌 때 난수를 바탕으로 무작위로 나누게 되는데, 이때 난수의 초기값을 고정시켜주는 기능이다.
random_state = 100이라고 지정해놓았으니, 나중에도 이렇게 적어주면 이 실험 결과를 재현할 수 있다. (안그러면 돌릴 때마다 매번 다르게 나눠줄 거다.)

개수를 찍어보자.

445:144 대략 8:2로 분리된 걸 확인했다.
모델 생성하기
이제 모델을 생성하자. 당연히 학습 데이터를 가지고 모델을 생성한다. k=3으로 지정해보자.

생성한 모델에 데이터를 학습시키자. 위에서 나눠놓은 학습 데이터 세트(train_data, train_labels)로 학습시킨다.

모델의 정확도(Accuracy) 평가하기
위에서 데이터 세트를 나눠놨기 때문에 학습시킨 모델을 테스트 할 수 있다. 당연히 검증 세트의 데이터와 레이블을 넣어줘야 한다.
KNeighborsClasifier에서는 .score()를 쓰면 모델의 정확도를 바로 확인할 수 있다.

정확도가 96%, 꽤 나쁘지 않다.
그런데 이건 k=3일 때의 모델이다.
그렇다면 이번엔 k값을 1부터 100까지 바꿔가면서 모델 정확도를 구해서 저장해놓고, 시각화를 해보자.
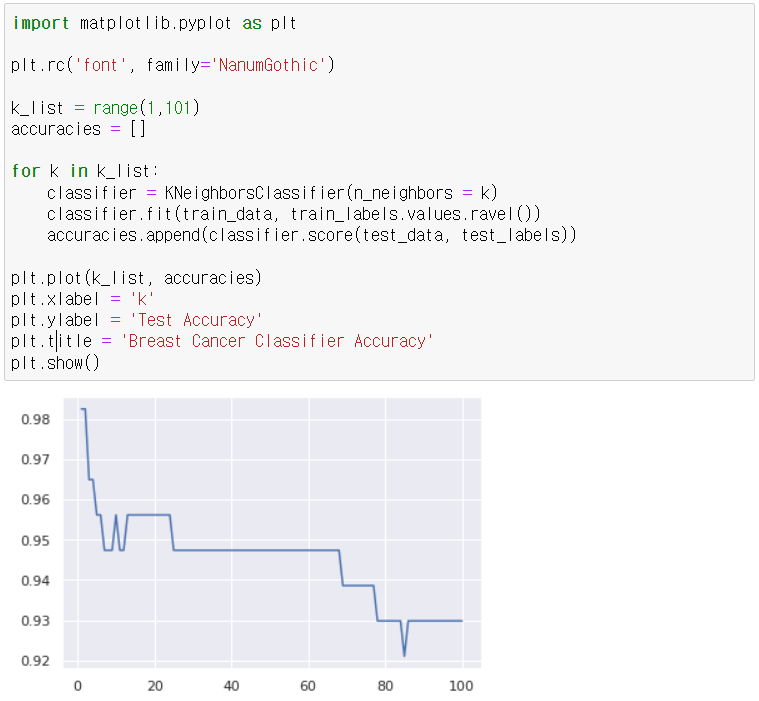
k가 커질수록 underfitting이 생겨서 정확도가 떨어지는걸 확인할 수 있다. 대충 집어서 확인하는거다.
어쨌든 적절한 k값을 찾아 분류 모델을 생성해주면 되겠다. 당연히 이후에 .predict()로 레이블을 예측하는 것도 가능하다.
아, 그리고 위에서 데이터 세트를 학습/검증 데이터로 분리할 때 random_state를 지정했다. 이걸 바꿔주면 모델의 정확도도 당연히 조금씩 달라질 거다. (물론 데이터가 이상적으로 충분히 크다면 차이가 거의 없겠지만.)
