
Abstract
- Alexnet은 ImageNet LSVRC-2010 대회에서 top-1, top-5 error rates가 각각 37.5%, 17.5%를 보여줬다.
top-1, top-5 error rates란
- 훈련이 된 분류기가 새로운 테스트 이미지들에 대해 예측한 클래스(=top-1 class)가 실제 클래스와 닽다면 top-1 error는 0%가 됨
- top-5 class 중에 실제 클래스가 있다면 0%가 됨
- 위의 LSVRC-2010 contest는 1000개의 클래스를 가지고 훈련된 분류기의 top-5 error가 5%보다 작을 경우 분류 능력이 상당히 좋다고 판단함
- 1000개의 클래스에서 top-5 class는 높은 확률로 판단한 5개의 클래스가 유사한 것일 가능성이 높은데, 예를 들어 자동차 중에 승용차, 버스, suv 같이 차중에 다른 종류일 수 있음
- 훈련을 더 빠르게 하기위해 포화되지 않는 뉴런(non-saturating neurons)과 합성곱에 매우 효과적인 GPU 도구를 사용함
- 과적합(overfitting)을 줄이기 위해 완전 연결 층(Fully connected layer)에 드롭아웃(dropout)을 적용함
- ILSVRC-2012 competition에서 변형된 모델로 참가했고 top-5 test error rate가 15.3%로 보여줌(2등은 26.2%임)
Introduction
해당 논문은 반복되는 내용이 많으므로 중복내용은 무시하고 진행
퍼포먼스를 높이기 위해서
- collect larger datasets
- learn more powerful models
- preventing overffiting
1. collect larger datasets
-
Mnist처럼 간단한 테스크는 원본 데이터(label)의 특성을 보존하면서(preserving) 변형(transformation)된 데이터 셋으로 꽤 잘 해결되었음
-
하지만, 실제 환경에서의 객체들은 매우 다양하게 나타나기 때문에 훨씬 더 큰 데이터 셋이 필요함
2. learn more powerful models
- 수백만개의 이미지 속 1000개의 객체를 학습하려면 거대한 학습공간의 모델이 필요함
- feedforward neural network보다 CNN이 훨씬더 적은 connections과 파라미터를 가져서 훈련이 더 용이함
3. preventing overffiting
- CNNs은 대규모의 고해상도 이미지로 적용시키는데 엄청 비싼게 문제임
- 하지만, 2차원 합성곱을 병렬로 처리가능한 최신 GPU는 CNN 훈련이 가능하고 ImageNet같은 데이터셋도 과적합 없이 모델 훈련하는데 충분함
The Dataset
- ImageNet은 다양한 고해상도 이미지로 구성되어 있어서 256*256 픽셀로 이미지를 다운 샘플링해서 씀
The Architecture
1. ReLU Nonlinearity
- 원래는 f(x) = tanH(x)를 썼는데 경사하강의 학습 속도 측면에서 비포화 비선형 함수인 f(x) = max(0, x)가 빠름
- 즉, 깊은 합성곱 뉴럴 네트워크에서 Relu 사용이 몇배 더 빠름 그리고 과적합도 막아줌
2. Training on Multiple GPUs
- 1개의 GTX 580 GPU가 3기가 메모리만 가져서 네트워크를 훈련할 때 max사이즈가 제한됨 => 2개의 GPU를 병렬화해서 사용함
- 병렬화 구조는 절반의 커널(또는 뉴런)을 각각의 gpu로 인풋해주고 특정 층(layer-3)에서 소통하게함
- 2개의 gpu를 사용하는 구조는 gpu 1개를 사용했을 때보다 top-1, top-5 오류율이 1.7, 1.2%로 줄어듬
- 그리고 2개 GPU 네트워크는 훈련시간도 약간 감소됨
3. Local Response Normalization
- Relu는 saturating(0으로 수렴해서 정보를 잃어버리는 것)을 방지해주는 정규화가 필요하지 않음
- 아래의 지역 정규화가 일반화해줌
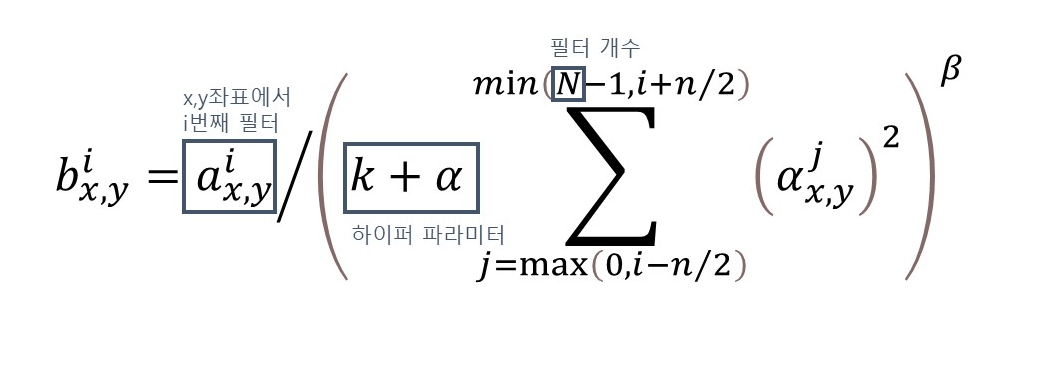
- relu는 매우 높은 픽셀값이 영향을 크게 미치기 때문에 이를 방지해야하는데 다른 액티베이션 맵에 같은 위치에 있는 픽셀들에 정규화를 하는 것
4. Overlapping Pooling
- 원래는 풀링 유닛이 겹치지 않았음
기존 Pooling units
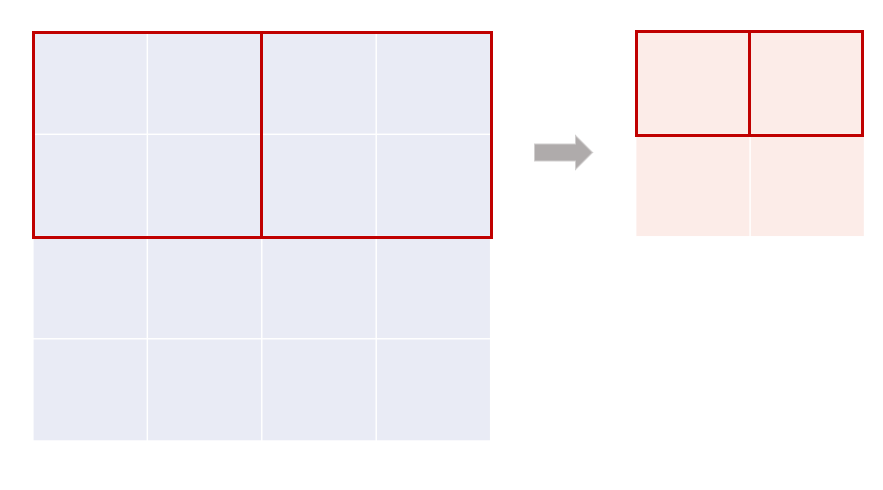
Overlapping pooling units
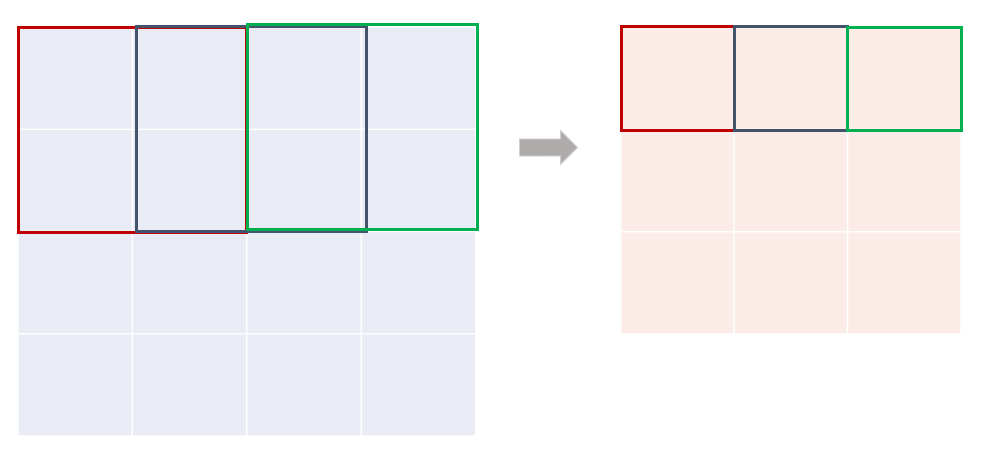
- 하지만, overlapping pooling을 사용했고 그 결과, top-1,top-5 error rate가 각각 0.4%, 0.3%로 됨
- 오버랩핑 풀링은 과적합을 약간 막아줌
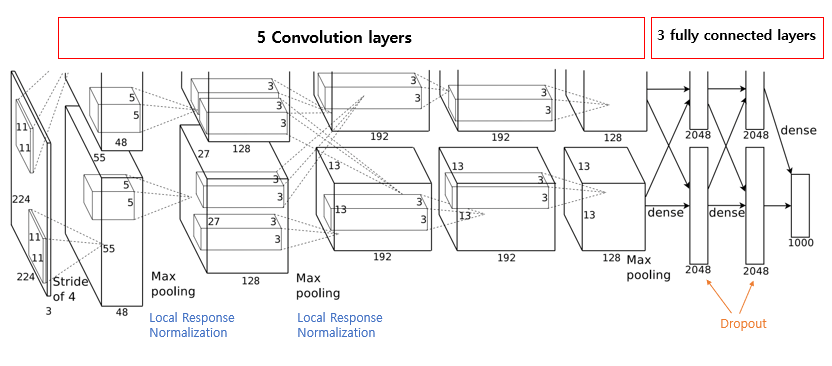
5. Overall Architecture
- 2,4,5번째 conv layer는 이전층 각각의 커널맵이랑 연결됨
- 3번째 conv layer는 이전층 모든 커널맵과 연결됨
- fully connected layer는 이전층의 모든 뉴런들과 연결됨
Conv layer 1
- input image = 224x224x3
- kernels/kernels size = 96/11x11x3
- stride = 4
Conv layer 2
- kernls/kernels size = 256/5x5x48
Conv layer 3,4,5
- pooling, normalization layers없이 연결됨
Conv layer 3
- kernels/kernels size = 384/3x3x256
Conv layer 4
- kernels/kernels size = 384/3x3x192
Conv layer 5
- kernels/kernels size = 256/3x3x192
fully connected layers
- 4096 neurons
Reducing Overfitting
- 위의 방법들이 과적합을 피하기 어렵기 때문에 데이터 증강과 드롭아웃을 통해 과적합을 방지함
Data Augmentation
- 이미지 사이즈(256256)를 224224로 줄이고 좌우 반전해줌 그러면 10개의 이미지를 얻을 수 있음
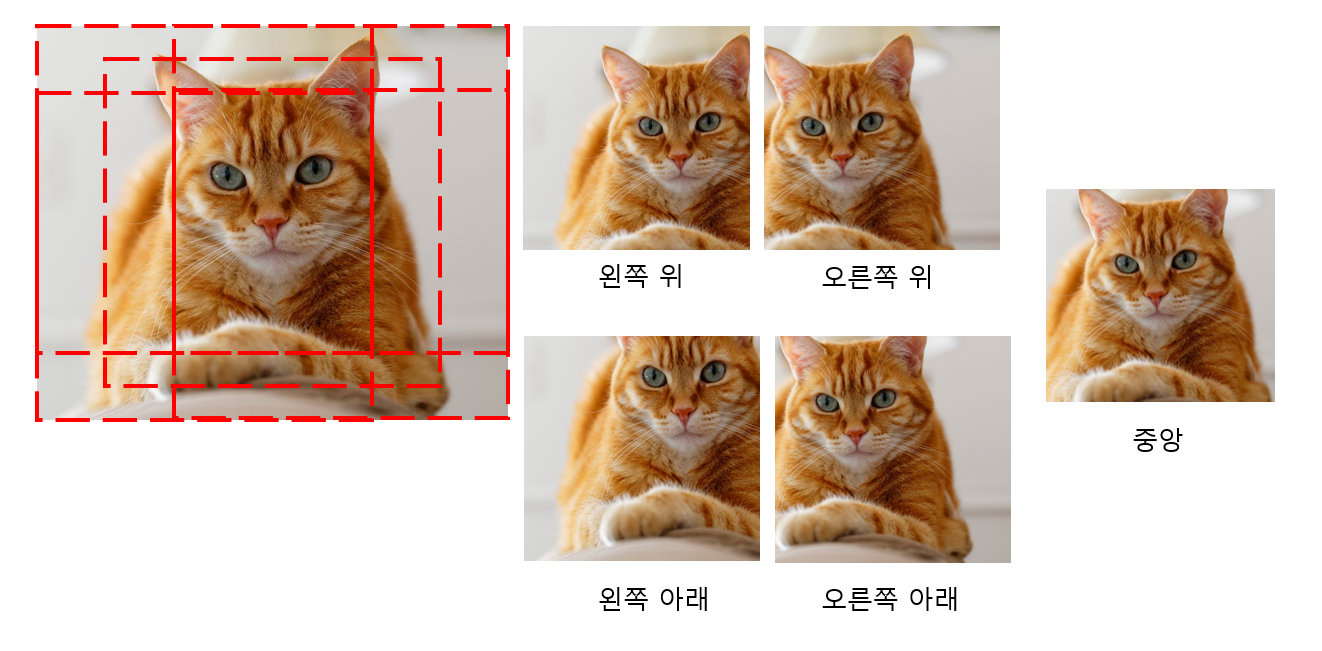
위의 이미지 상태에서 좌우 반전을 적용해줌 그럼, 10개
- 훈련 이미지의 rgb 채널의 인텐서티를 변경해줌
- pca를 통해 평균은 0, 표준편차는 0.1이 되는 랜덤 변수를 에이겐 벨류에 곱해줌 그리고 이 값을 원래 픽셀 값에 더해줌
Dropout
- 1,2번째 fully connected layer에 드롭아웃 적용함
Details of learning
- batch_size = 128, momentum = 0.9, weight decay = 0.0005(가중치가 작으면 모델의 훈련 에러를 줄여줌)로 확률적 경사하강법 수행(SGD)
- 학습률은 모든 레이어에서 동일하게 진행했으며 val error가 개선되지 않을 경우 10으로 나눈 학습률을 사용함
- 학습률은 0.01로 초기화했고 학습이 끝나기 전까지 3번 감소했음
Results
Qualitative Evaluations

위의 8개 이미지에서 top5의 예측 라벨을 보여줌
- mite도 분류되고 아래의 컨버터블과 체리 이미지는 모호하게 구별함

- 가장 왼쪽 첫번째 컬럼은 test image이며 테스트 이미지와 Euclidean distance가 가까운 training image들 6개를 보여줌
- 코끼리나 강아지는 자세도 다른데 동일한 클래스로 보여줬음

안녕하세요. 기억보다 기록을 믿는 레나입니다!