구글넷은 혼자 읽기에 어려운 내용이 많아서 개인적으로 의역이 많을거 같다

Abstract
- Inception을 제안
인셉션이란? deep cnn이고 ILSVRC14대회에서 분류와 인지를 위한 최신 세팅임 - 인셉션 아키텍쳐의 특징은 네트워크 안에서 컴퓨터 리소스 활용이 커진다는 것
그말은 즉, 컴퓨팅 연산 비용이 변하지 않고 유지하면서 네트워크의 깊이와 너비는 커질 수 있게함 - 퀄리티를 위해 Hebbian principle(헵의 원리)과 multi-scale processing(여러 스케일을 프로세싱하는)의 직감을 기반으로 아키텍쳐적인 결정을 가짐
Hebbian principal(헵의 원리)
- 시냅스 양쪽의 뉴런이 동시에 또 반복적으로 활성화 되었다면 그 뉴런 사이의 연결강도가 강해진다
- ILSVRC14에 제출하고 22개 층의 깊은 네트워크를 가진 GoogLeNet 등장
Introduction
image recognition(기계가 이미지 속 장소나 객체를 분별하는 능력)과
object detection(사물, 사람등을 감지하는 것)의 극적인 속도로 퀄리티가 좋아졌음
-
이 퀄리티가 좋아진 이유는 더 강력한 하드웨어, 큰 데이터셋, 더 커진 모델이 아닌 주로 새로운 아이디어, 알고리즘 그리고 향상된 네트워크 아키텍쳐들 때문이라는 것
-
GoogLeNet은 Krizhevsky아키텍쳐보다 12배 더 적은 파라미터를 사용했는데 ILSVRC 2014에서 훨씬더 정확했음
-
객체 감지에서 큰 성취는 더 큰 모델이나 단독의 깊은 네트워크가 아닌 깊은 아키텍쳐와 컴퓨터 비전의 시너지로부터 온건데 이건 R-cnn 알고리즘이랑 같음
-
또 다른 중요한 점은 우리의 알고리즘 효율성이(메모리 사용과 전기 사용에서) 모바일, 임베디드 컴퓨팅에 사용할 수 있다는 것
-
inception은 컴퓨터 비전에서 deep neural network architecture이다
-
deep은 2가지 의미를 가지는데 1) 인셉션 모듈의 형식에서 새로운 구조 2)네트워크 깊이가 깊어짐
-
인셉션 아키텍처의 장점은 ILSVRC 2014 분류와 감지 문제에 더 좋은 결과를 내는데 입증했음
Related Work
- LeNet-5는 기본적인 구조를 가짐, conv layers(정규화, max pooling과 함께있는)와 1~2개의 fully connected layers
- 위의 기본 구조에서 변형들이 이미지 분류에서 가장 우세했고 Mnist, CIFAR, imagenet등에서 최고의 결과를 만들어왔다
- 최근 트렌드는 imagenet같은 더 큰 데이터 셋에서 층의 수와 크기를 크게 만들고 과적합을 방지하려고 드롭아웃을 사용하는 방식
1. Inception 모델에서 사용한 것과 사용하지 않은 것
- max pooling 층이 일부분 정확한 정보의 손실을 이끌었다는 문제가 있었지만 똑같은 conv network architecture를 localization, object detection, 인간 자세 추정등에 성공적으로 이용해왔음
localization
- 이미지 내에 객체가 있을때 그 위치가 어딘지 알아내는 것
- [구글넷-인셉션 공통점]
인셉션 모델과 유사하게 시각 정보를 처리하는 대뇌 피질같은 모델은 다양한 크기의 garbor filter 시리즈를 사용함=> why? 다중 스케일을 다루기 위해서 - [구글넷-인셉션 차이점]
하지만, 구글넷에서는 2층으로 고정된 깊은 모델이 아닌 인셉션 모델의 모든 층이 학습되었고 더 나아가 인셉션 층이 많이 반복되었음
2. Network in Nework에 있는 1*1 conv layers를 사용
- 또한, 1*1 conv layers를 2가지 목적으로 사용했는데 1) 컴퓨팅 연산의 보틀넥을 제거하기위해 차원축소 모듈로 사용했고 2) 우리의 네트워크 크기를 제한하는데 사용함
- 1*1 conv 층은 성능 패널티 없이 네트워크의 깊이와 너비를 증가시킴
3. R-cnn의 객체의 카테고리 식별을 위한 2 stage를 강화해 사용
- r-cnn은 2가지로 문제를 분해했는데 1) 잠재적인 객체로 제안을 위해 작은 단위의 단서(색상, 슈퍼 픽셀등)를 사용 2) 그리고 나서 위의 단서들의 위치에있는 객체가 무슨 카테고리인지 식별하려고 cnn 분류기를 사용함
- 위의 2단계는 바운딩 박스 segmentation의 정확도와 분류문제를 잘 풀었음
- 그래서, 구글넷은 위의 파이프 라인을 채택하고 두 단계를 더 강화시켜서 사용했음
- 예를 들어 멀티박스 예측과 바운딩 박스 제안을 더 효과적이게 앙상블 접근을 사용
3. Motivation and High Level Considerations
- 깊은 신경망의 좋은 퍼포먼스를 가지는 방법은 크기를 키우는건데 크기를 키운다는 것은 깊이와 너비가 커지는 것을 말함
- 하지만, 위에 방법은 두개의 단점이 있음
단점 1. 오버피팅
- 큰사이즈의 트레이닝 셋은 파라미터수가 많다는 걸 의미하고 이말은 오버피팅된다는 것임 왜냐하면 라벨링된 예시의 수를 제한시켜야하고 => 즉, 사람이 시베리안 허스키와 에스키모 개를 구분하는 것처럼 세세하게 나눈 데이터셋을 만들 수 없고 이는 보틀넥 현상이 발생함
단점 2. 컴퓨팅 연산량의 증가
- 2개의 conv layer가 연결되어있으면 필터의 수도 증가하고 연산량의 증가로 이어진다
- 만약 대부분의 가중치가 0에 가깝게 끝난다면 컴퓨터 연산이 낭비된다
- 컴퓨터 용량은 한정되기 때문에 결가가 좋은걸 원하면 무차별적인 크기의 증가보다 컴퓨팅 연산의 효율적인 분배가 더 선호된다
위 단점을 해결하기 위한 방법은 fully connected 방법에서 sparsely connected 아키텍쳐로 바꿔야한다
-
만약 확률 분포가 크고, sparse deep neural network로 보여지면 마지막층의 액티베이션의 관계를 통계적으로 분석하고 매우 관련된 뉴런들을 클러스터링하면서 최고의 네트워트 연결이 만들어진다
-
오늘날 컴퓨팅 환경은 균일하지 않은 데이터 구조의 숫자 연산이 매우 비효율적이다
-
산술 연산 회수가 많이 감소하더라도 룩업, 캐시 누락의 메모리가 너무 크게 차지해서 희소 행렬(많은 항이 0으로 되어있는 행렬)로 전환하는 것은 성과를 얻지 못한다
-
convnet은 대칭을 깨고 학습을 향상시키려고 사용했었는데 이 트랜드는 병렬 연산을 최적화하기위해 full connected로 바뀌었다
-
구조의 균형과 많은 필터 갯수, 큰 배치사이즈가 효율적인 dense 연산이 가능하게 했다
Architectual Details
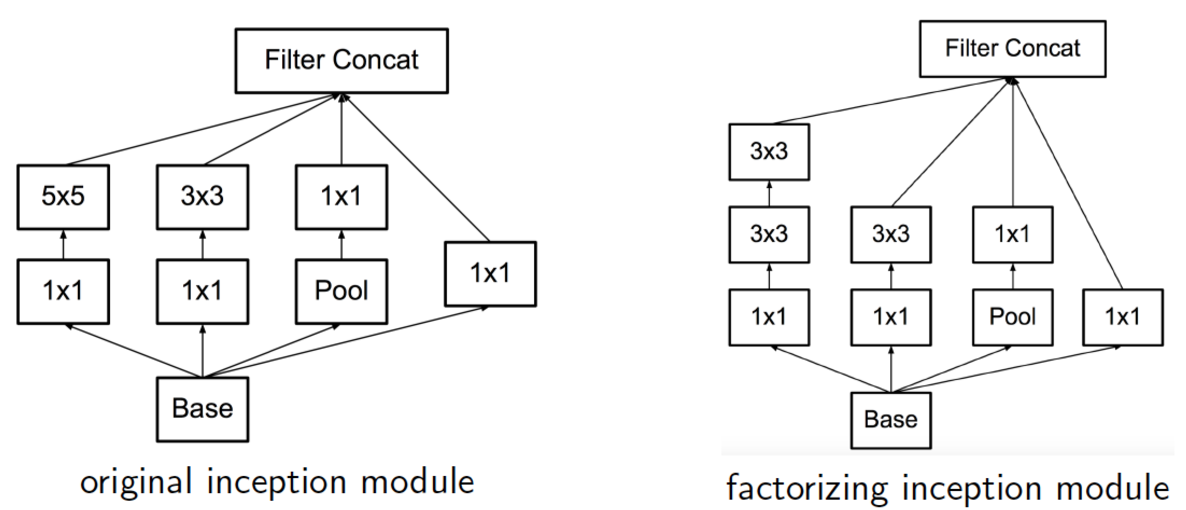
- 기존 인셉션 모듈의 문제인 스테이지를 넘어갈 수록 연산비용이 크기 때문에 인셉션 모듈은 비효율적이다
- 위의 내용으로 아이디어가 제시되었는데 컴퓨팅 조건들이 있던 말던 차원 축소와 투영을 적용하는 것이었다
- 낮은 차원은 임베딩 정보가 많이 포함되어있는데 임베딩 정보는 덴스안에서 정보가 보여지기 때문에 이게 모델을 이해하기 여러움
- 그래서 대부분의 위치에서 sparse하게 만들고 핵심만 담게 했음
- 그 방법은 3x3, 5x5 이전에 1x1 층을 사용하는 것인데 이는 선형 액티베이션을 포함하게 되는 것이다
변경된 인셉션 모듈의 장점
- 컴퓨팅 연산의 복잡함이 통제되지 않게 증가하는 것 없이 각각의 스테이지에서 유닛의 수가 증가하는 것을 허락함
- 시각 정보가 다양한 스케일에서 진행되었고 다른 스케일에서 동시에 특징을 추측할 수 있었음
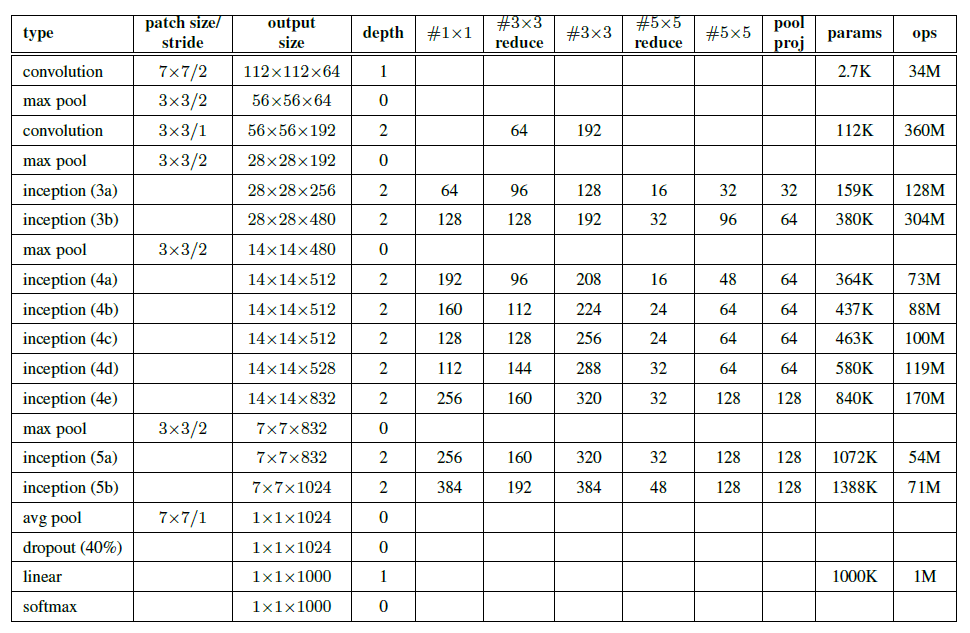
GoogLeNet
- 구글넷은 깊고 넓은 인셉션 네트워크를 가지고 향상된 결과로 보여지게 이 인셉션 네트워크를 앙상블해서 사용함
- 프로젝션 층에서 빌트인 max pooling 이후에 1x1 필터들의 수를 알 수 있고 이로 인해 reduction/프로젝션 층이 relu함수로 사용한다
-
위의 네트워크가 컴퓨터 연산의 효율성과 실용적으로 만들어졌고 그 결과로 제한된 컴퓨팅 자원과 낮은 메모리를 포함해서 개별의 디바이스에서 사용 되어졌다
-
실제 네트워크 층은 100개를 사용했지만 100개의 층은 머신러닝 기반 시스템에 의존했음
-
분류기 이전의 평균 풀링의 사용에서 구글넷은 추가의 선형층을 사용했고 라벨이 있는 세트의 네트워크에서 파인튜닝이 가능했다
-
하지만 위의 방법은 편했으나 주요 영향을 끼치진 않았는데 fully connected layer에서 average pooling 으로 이동이 top-1 accuracy를 대략 0.6 퍼센트만 향상시켰다
-
그리고 fully connected layer의 삭제 후에 드롭아웃을 사용해야했음
-
상대적으로 네트워크의 깊이가 커졌기 때문에 모든층에서 효율적인 방법으로 역전파 능력을 고민했다
-
한가지 인사이트는 중간층의 핏쳐들을 구별해야 상대적으로 낮은 네트워크의 강한 퍼포먼스를 보인다는 것이다
-
중간 층에 연결된 보조의 분류기를 더함으로써 우리는 낮은 층에서 구별이 가능했고 역전파에서 그레디언트 시그널이 증가했음, 그리고 추가적인 정규화도 제공되었음
-
이 분류기는 작은 conv network의 형태로 왔고 inception(4a), (4d) 모듈의 결과의 위에 놓여졌음
-
훈련 동안에는 낮아진 가중치와 함께 토탈 로스가 로스에 더해졌고 추론때는 보조의 네트워크는 사용하지 않았음
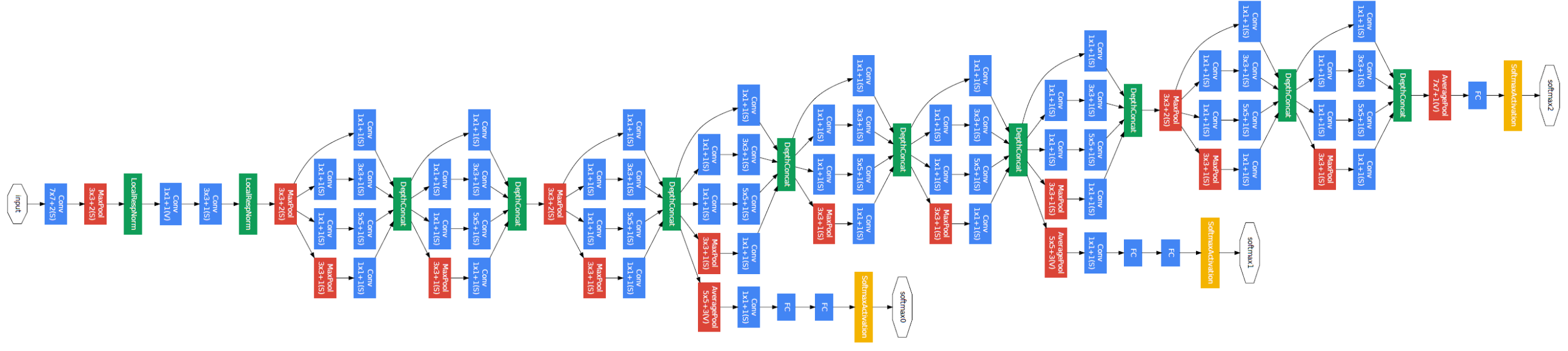
6. Training Methodology
- 실제론 cpu를 사용했지만 일주일동안 최신의 gpu를 사용했을거라고 추정했다
- 훈련은 0.9 모멘텀과 함께 asynchronous stochastic gradient를 사용했고 러닝 레이트를 수정했다 추론 시간에 폴약 평균이 최종 모델을 만드는데 사용되었다
- 우리의 이미지 샘플링 방법은 한달 넘게 바뀌어왔고 이미 사용된 모델은 다른 옵션으로 훈련되었다
(옵션: 드롭아웃, 러닝레이트 같은 바뀐 하이퍼 파라미터)- 문제를 더 복잡하게 하기위해서 그 모델은 주로 상대적으로 더 작은 크롭들에서 훈련되어졌다
- 위처럼 다양한 사이즈의 이미지 패치들의 사용으로 대회 이후에 더 잘 일하는 것으로 확인했다
- 또한, 측광 왜곡이 오버피팅과 싸우는데 유용했다
- 마지막으로 우린 랜덤 보간법을 사용했다
9. Conclution
첫번째 장점
- 얕고 덜 넓은 네트워크와 비교해서 컴퓨터 연산의 증가에서 얻은 퀄리티있는 gain
두번째 장점
- 문맥을 활용하지도 바운딩 박스 회귀의 퍼포먼스 없이도 디텍션 워크가 경쟁적임, 그 사실이 인셉션 아키텍쳐의 강점의 증거로 제공된다
- 유사한 깊이와 넓이의 비싼 네트워크로 인해 비슷한 결과가 기대되지만 우리는 명확한 증거를 보여준다
- sparser 아키텍처로 이동이 일반적으로 유용하고 그럴듯한 아이디어라고
